 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Label Dataset of French Fake News: Human and Machine Insights
Apr 11, 2024
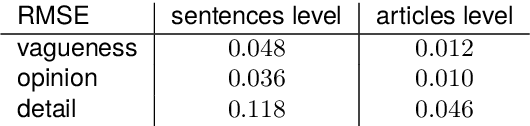
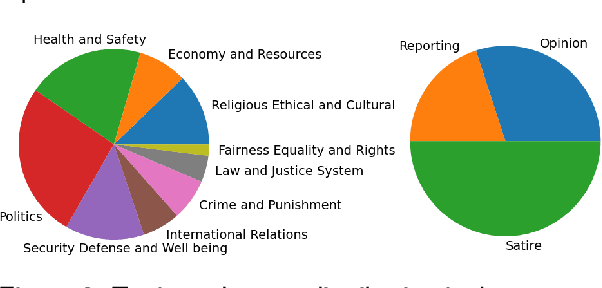
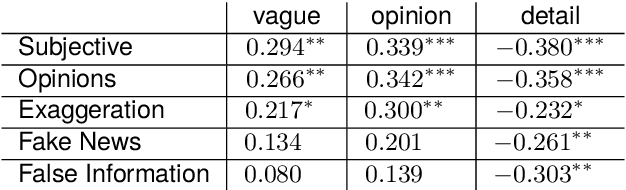
We present a corpus of 100 documents, OBSINFOX, selected from 17 sources of French press considered unreliable by expert agencies, annotated using 11 labels by 8 annotators. By collecting more labels than usual, by more annotators than is typically done, we can identify features that humans consider as characteristic of fake news, and compare them to the predictions of automated classifiers. We present a topic and genre analysis using Gate Cloud, indicative of the prevalence of satire-like text in the corpus. We then use the subjectivity analyzer VAGO, and a neural version of it, to clarify the link between ascriptions of the label Subjective and ascriptions of the label Fake News. The annotated dataset is available online at the following url: https://github.com/obs-info/obsinfox Keywords: Fake News, Multi-Labels, Subjectivity, Vagueness, Detail, Opinion, Exaggeration, French Press
Measuring vagueness and subjectivity in texts: from symbolic to neural VAGO
Sep 12, 2023



We present a hybrid approach to the automated measurement of vagueness and subjectivity in texts. We first introduce the expert system VAGO, we illustrate it on a small benchmark of fact vs. opinion sentences, and then test it on the larger French press corpus FreSaDa to confirm the higher prevalence of subjective markers in satirical vs. regular texts. We then build a neural clone of VAGO, based on a BERT-like architecture, trained on the symbolic VAGO scores obtained on FreSaDa. Using explainability tools (LIME), we show the interest of this neural version for the enrichment of the lexicons of the symbolic version, and for the production of versions in other languages.
Semantic of Cloud Computing services for Time Series workflows
Feb 01, 2022



Time series (TS) are present in many fields of knowledge, research, and engineering. The processing and analysis of TS are essential in order to extract knowledge from the data and to tackle forecasting or predictive maintenance tasks among others The modeling of TS is a challenging task, requiring high statistical expertise as well as outstanding knowledge about the application of Data Mining(DM) and Machine Learning (ML) methods. The overall work with TS is not limited to the linear application of several techniques, but is composed of an open workflow of methods and tests. These workflow, developed mainly on programming languages, are complicated to execute and run effectively on different systems, including Cloud Computing (CC) environments. The adoption of CC can facilitate the integration and portability of services allowing to adopt solutions towards services Internet Technologies (IT) industrialization. The definition and description of workflow services for TS open up a new set of possibilities regarding the reduction of complexity in the deployment of this type of issues in CC environments. In this sense, we have designed an effective proposal based on semantic modeling (or vocabulary) that provides the full description of workflow for Time Series modeling as a CC service. Our proposal includes a broad spectrum of the most extended operations, accommodating any workflow applied to classification, regression, or clustering problems for Time Series, as well as including evaluation measures, information, tests, or machine learning algorithms among others.
Combining Vagueness Detection with Deep Learning to Identify Fake News
Oct 31, 2021
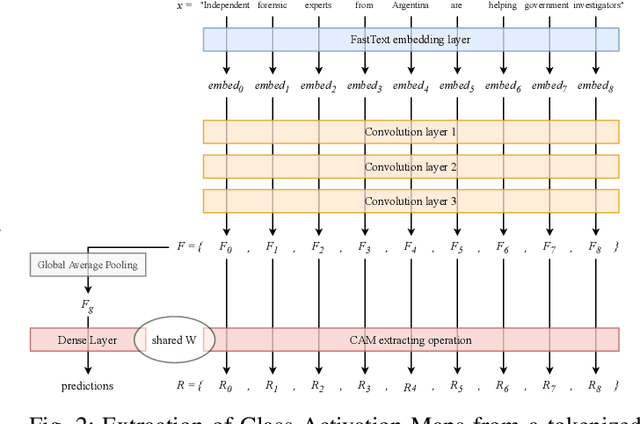
In this paper, we combine two independent detection methods for identifying fake news: the algorithm VAGO uses semantic rules combined with NLP techniques to measure vagueness and subjectivity in texts, while the classifier FAKE-CLF relies on Convolutional Neural Network classification and supervised deep learning to classify texts as biased or legitimate. We compare the results of the two methods on four corpora. We find a positive correlation between the vagueness and subjectivity measures obtained by VAGO, and the classification of text as biased by FAKE-CLF. The comparison yields mutual benefits: VAGO helps explain the results of FAKE-CLF. Conversely FAKE-CLF helps us corroborate and expand VAGO's database. The use of two complementary techniques (rule-based vs data-driven) proves a fruitful approach for the challenging problem of identifying fake news.