 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeON-TRAC Consortium Systems for the IWSLT 2022 Dialect and Low-resource Speech Translation Tasks
May 04, 2022

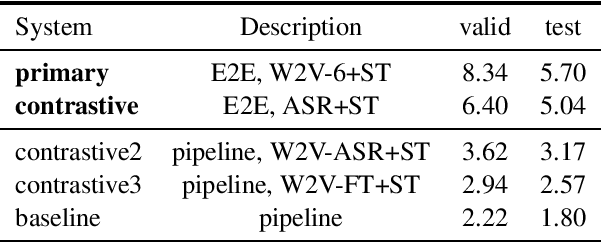

This paper describes the ON-TRAC Consortium translation systems developed for two challenge tracks featured in the Evaluation Campaign of IWSLT 2022: low-resource and dialect speech translation. For the Tunisian Arabic-English dataset (low-resource and dialect tracks), we build an end-to-end model as our joint primary submission, and compare it against cascaded models that leverage a large fine-tuned wav2vec 2.0 model for ASR. Our results show that in our settings pipeline approaches are still very competitive, and that with the use of transfer learning, they can outperform end-to-end models for speech translation (ST). For the Tamasheq-French dataset (low-resource track) our primary submission leverages intermediate representations from a wav2vec 2.0 model trained on 234 hours of Tamasheq audio, while our contrastive model uses a French phonetic transcription of the Tamasheq audio as input in a Conformer speech translation architecture jointly trained on automatic speech recognition, ST and machine translation losses. Our results highlight that self-supervised models trained on smaller sets of target data are more effective to low-resource end-to-end ST fine-tuning, compared to large off-the-shelf models. Results also illustrate that even approximate phonetic transcriptions can improve ST scores.
Speech Resources in the Tamasheq Language
Jan 14, 2022
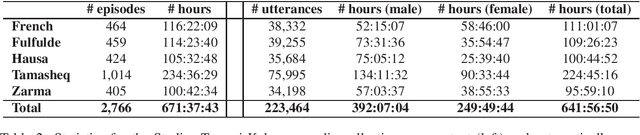

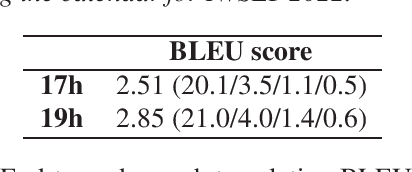
In this paper we present two datasets for Tamasheq, a developing language mainly spoken in Mali and Niger. These two datasets were made available for the IWSLT 2022 low-resource speech translation track, and they consist of collections of radio recordings from the Studio Kalangou (Niger) and Studio Tamani (Mali) daily broadcast news. We share (i) a massive amount of unlabeled audio data (671 hours) in five languages: French from Niger, Fulfulde, Hausa, Tamasheq and Zarma, and (ii) a smaller parallel corpus of audio recordings (17 hours) in Tamasheq, with utterance-level translations in the French language. All this data is shared under the Creative Commons BY-NC-ND 3.0 license. We hope these resources will inspire the speech community to develop and benchmark models using the Tamasheq language.
Combining Vagueness Detection with Deep Learning to Identify Fake News
Oct 31, 2021
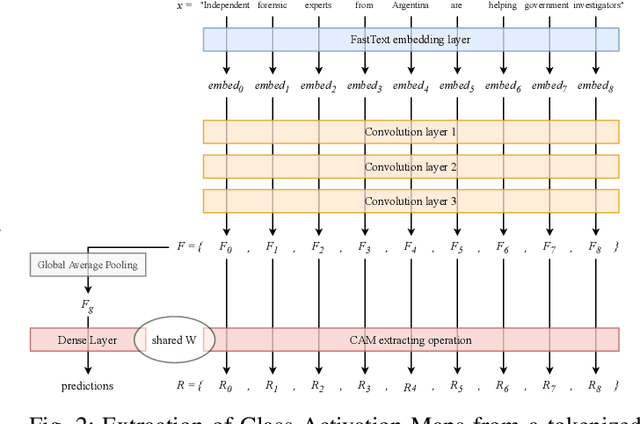
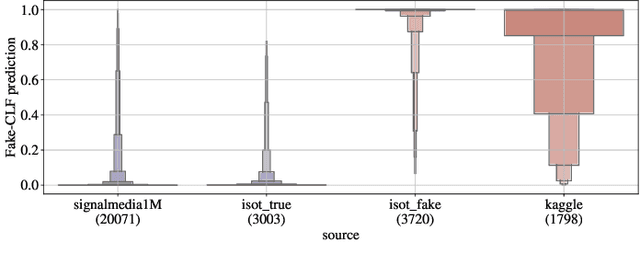
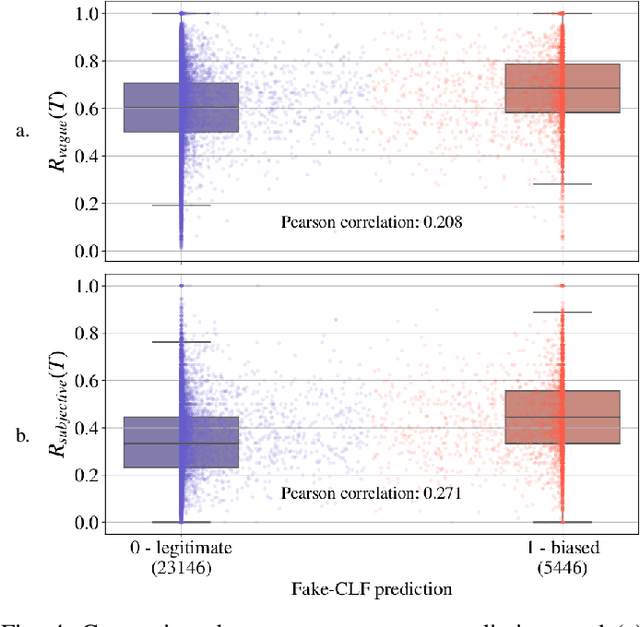
In this paper, we combine two independent detection methods for identifying fake news: the algorithm VAGO uses semantic rules combined with NLP techniques to measure vagueness and subjectivity in texts, while the classifier FAKE-CLF relies on Convolutional Neural Network classification and supervised deep learning to classify texts as biased or legitimate. We compare the results of the two methods on four corpora. We find a positive correlation between the vagueness and subjectivity measures obtained by VAGO, and the classification of text as biased by FAKE-CLF. The comparison yields mutual benefits: VAGO helps explain the results of FAKE-CLF. Conversely FAKE-CLF helps us corroborate and expand VAGO's database. The use of two complementary techniques (rule-based vs data-driven) proves a fruitful approach for the challenging problem of identifying fake news.