 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Multi-Human Neural Rendering Using Geometry Constraints
Feb 11, 2025



We present a method for recovering the shape and radiance of a scene consisting of multiple people given solely a few images. Multi-human scenes are complex due to additional occlusion and clutter. For single-human settings, existing approaches using implicit neural representations have achieved impressive results that deliver accurate geometry and appearance. However, it remains challenging to extend these methods for estimating multiple humans from sparse views. We propose a neural implicit reconstruction method that addresses the inherent challenges of this task through the following contributions: First, we propose to use geometry constraints by exploiting pre-computed meshes using a human body model (SMPL). Specifically, we regularize the signed distances using the SMPL mesh and leverage bounding boxes for improved rendering. Second, we propose a ray regularization scheme to minimize rendering inconsistencies, and a saturation regularization for robust optimization in variable illumination. Extensive experiments on both real and synthetic datasets demonstrate the benefits of our approach and show state-of-the-art performance against existing neural reconstruction methods.
GeoTransfer : Generalizable Few-Shot Multi-View Reconstruction via Transfer Learning
Aug 27, 2024This paper presents a novel approach for sparse 3D reconstruction by leveraging the expressive power of Neural Radiance Fields (NeRFs) and fast transfer of their features to learn accurate occupancy fields. Existing 3D reconstruction methods from sparse inputs still struggle with capturing intricate geometric details and can suffer from limitations in handling occluded regions. On the other hand, NeRFs excel in modeling complex scenes but do not offer means to extract meaningful geometry. Our proposed method offers the best of both worlds by transferring the information encoded in NeRF features to derive an accurate occupancy field representation. We utilize a pre-trained, generalizable state-of-the-art NeRF network to capture detailed scene radiance information, and rapidly transfer this knowledge to train a generalizable implicit occupancy network. This process helps in leveraging the knowledge of the scene geometry encoded in the generalizable NeRF prior and refining it to learn occupancy fields, facilitating a more precise generalizable representation of 3D space. The transfer learning approach leads to a dramatic reduction in training time, by orders of magnitude (i.e. from several days to 3.5 hrs), obviating the need to train generalizable sparse surface reconstruction methods from scratch. Additionally, we introduce a novel loss on volumetric rendering weights that helps in the learning of accurate occupancy fields, along with a normal loss that helps in global smoothing of the occupancy fields. We evaluate our approach on the DTU dataset and demonstrate state-of-the-art performance in terms of reconstruction accuracy, especially in challenging scenarios with sparse input data and occluded regions. We furthermore demonstrate the generalization capabilities of our method by showing qualitative results on the Blended MVS dataset without any retraining.
MAAIP: Multi-Agent Adversarial Interaction Priors for imitation from fighting demonstrations for physics-based characters
Nov 04, 2023



Simulating realistic interaction and motions for physics-based characters is of great interest for interactive applications, and automatic secondary character animation in the movie and video game industries. Recent works in reinforcement learning have proposed impressive results for single character simulation, especially the ones that use imitation learning based techniques. However, imitating multiple characters interactions and motions requires to also model their interactions. In this paper, we propose a novel Multi-Agent Generative Adversarial Imitation Learning based approach that generalizes the idea of motion imitation for one character to deal with both the interaction and the motions of the multiple physics-based characters. Two unstructured datasets are given as inputs: 1) a single-actor dataset containing motions of a single actor performing a set of motions linked to a specific application, and 2) an interaction dataset containing a few examples of interactions between multiple actors. Based on these datasets, our system trains control policies allowing each character to imitate the interactive skills associated with each actor, while preserving the intrinsic style. This approach has been tested on two different fighting styles, boxing and full-body martial art, to demonstrate the ability of the method to imitate different styles.
* SCA'23, Supplementary video: https://youtu.be/wQfIiw_rQ3w
Neural Mesh-Based Graphics
Aug 23, 2022



We revisit NPBG, the popular approach to novel view synthesis that introduced the ubiquitous point feature neural rendering paradigm. We are interested in particular in data-efficient learning with fast view synthesis. We achieve this through a view-dependent mesh-based denser point descriptor rasterization, in addition to a foreground/background scene rendering split, and an improved loss. By training solely on a single scene, we outperform NPBG, which has been trained on ScanNet and then scene finetuned. We also perform competitively with respect to the state-of-the-art method SVS, which has been trained on the full dataset (DTU and Tanks and Temples) and then scene finetuned, in spite of their deeper neural renderer.
Learning Generalizable Light Field Networks from Few Images
Jul 24, 2022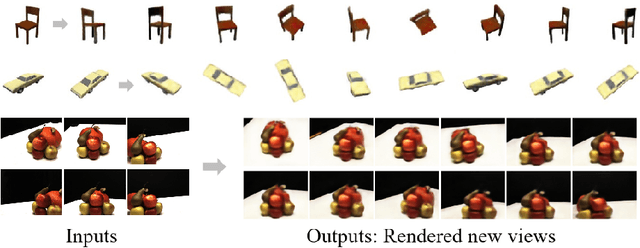
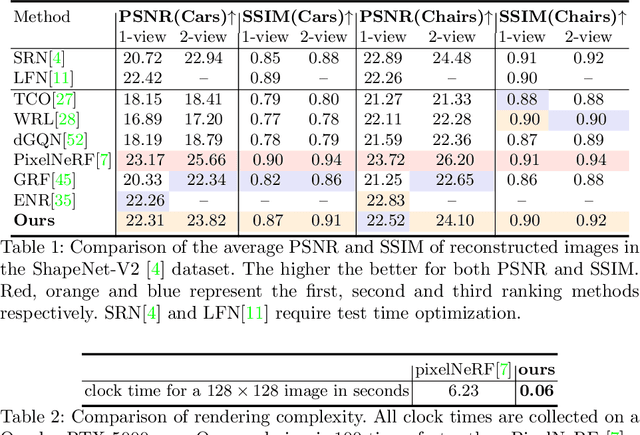
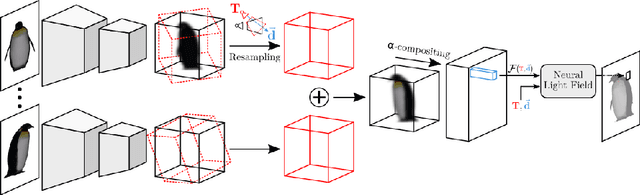

We explore a new strategy for few-shot novel view synthesis based on a neural light field representation. Given a target camera pose, an implicit neural network maps each ray to its target pixel's color directly. The network is conditioned on local ray features generated by coarse volumetric rendering from an explicit 3D feature volume. This volume is built from the input images using a 3D ConvNet. Our method achieves competitive performances on synthetic and real MVS data with respect to state-of-the-art neural radiance field based competition, while offering a 100 times faster rendering.
FaceTuneGAN: Face Autoencoder for Convolutional Expression Transfer Using Neural Generative Adversarial Networks
Dec 01, 2021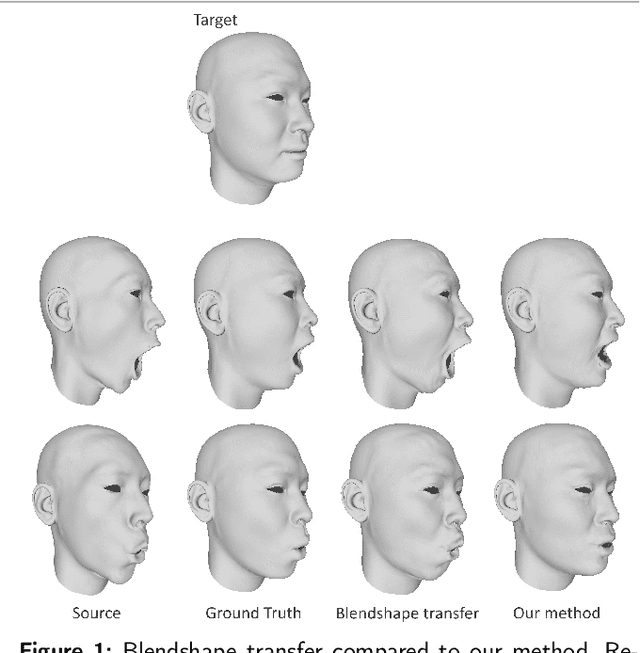

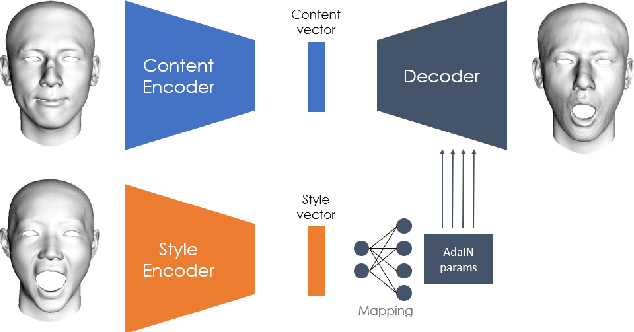
In this paper, we present FaceTuneGAN, a new 3D face model representation decomposing and encoding separately facial identity and facial expression. We propose a first adaptation of image-to-image translation networks, that have successfully been used in the 2D domain, to 3D face geometry. Leveraging recently released large face scan databases, a neural network has been trained to decouple factors of variations with a better knowledge of the face, enabling facial expressions transfer and neutralization of expressive faces. Specifically, we design an adversarial architecture adapting the base architecture of FUNIT and using SpiralNet++ for our convolutional and sampling operations. Using two publicly available datasets (FaceScape and CoMA), FaceTuneGAN has a better identity decomposition and face neutralization than state-of-the-art techniques. It also outperforms classical deformation transfer approach by predicting blendshapes closer to ground-truth data and with less of undesired artifacts due to too different facial morphologies between source and target.
Monocular Human Shape and Pose with Dense Mesh-borne Local Image Features
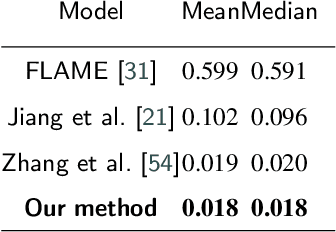
Nov 11, 2021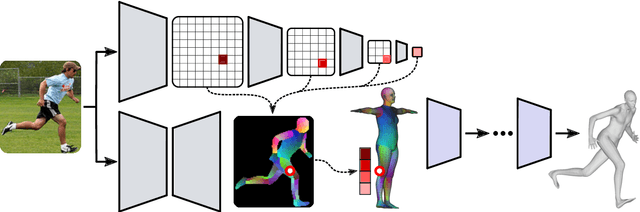

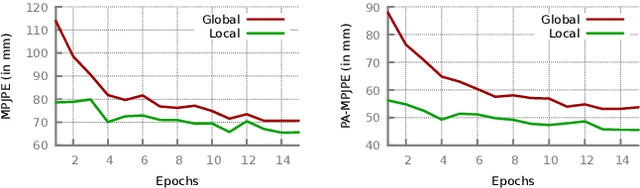
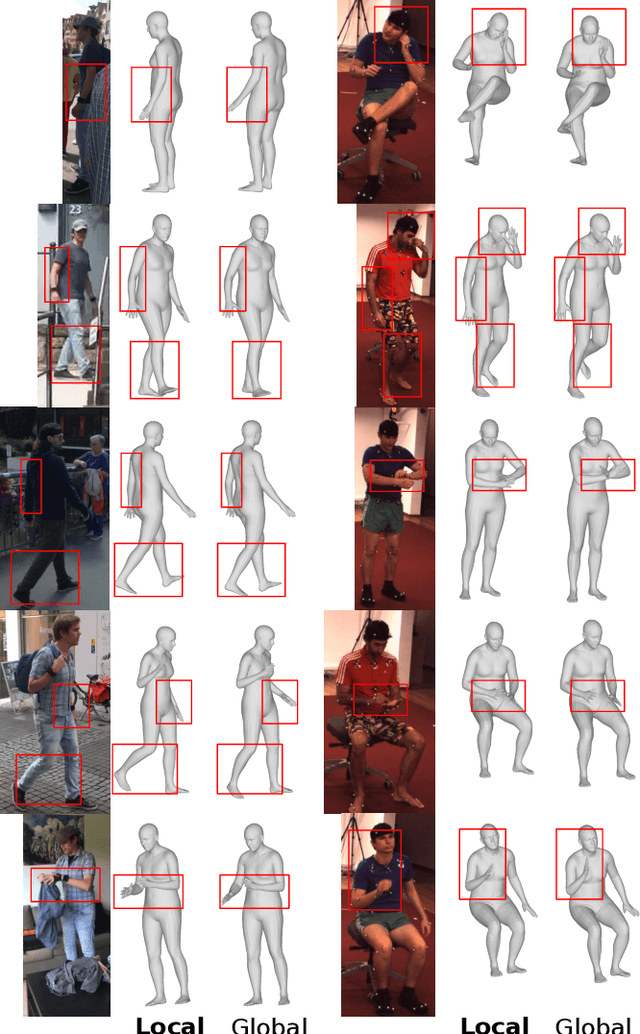
We propose to improve on graph convolution based approaches for human shape and pose estimation from monocular input, using pixel-aligned local image features. Given a single input color image, existing graph convolutional network (GCN) based techniques for human shape and pose estimation use a single convolutional neural network (CNN) generated global image feature appended to all mesh vertices equally to initialize the GCN stage, which transforms a template T-posed mesh into the target pose. In contrast, we propose for the first time the idea of using local image features per vertex. These features are sampled from the CNN image feature maps by utilizing pixel-to-mesh correspondences generated with DensePose. Our quantitative and qualitative results on standard benchmarks show that using local features improves on global ones and leads to competitive performances with respect to the state-of-the-art.
Neural Human Deformation Transfer
Oct 01, 2021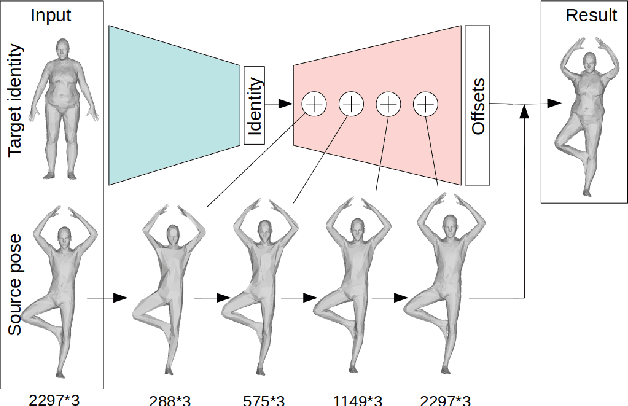

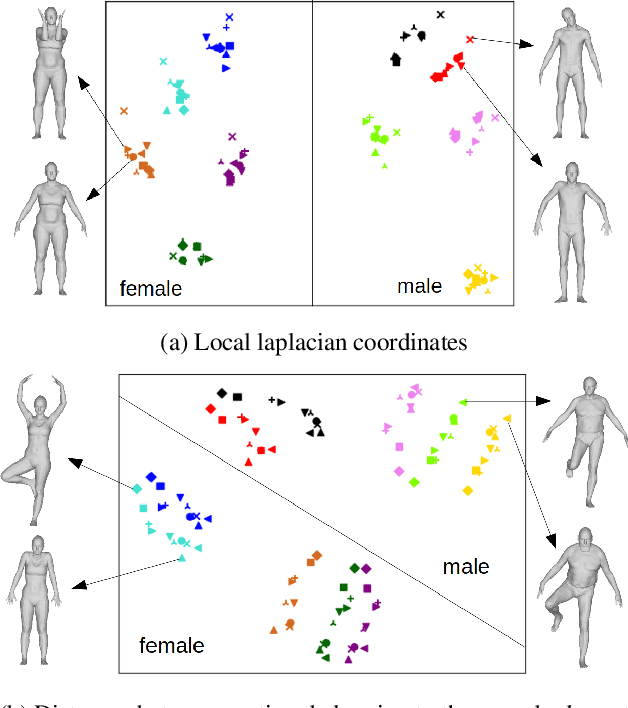
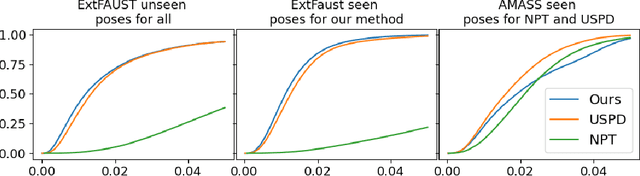
We consider the problem of human deformation transfer, where the goal is to retarget poses between different characters. Traditional methods that tackle this problem require a clear definition of the pose, and use this definition to transfer poses between characters. In this work, we take a different approach and transform the identity of a character into a new identity without modifying the character's pose. This offers the advantage of not having to define equivalences between 3D human poses, which is not straightforward as poses tend to change depending on the identity of the character performing them, and as their meaning is highly contextual. To achieve the deformation transfer, we propose a neural encoder-decoder architecture where only identity information is encoded and where the decoder is conditioned on the pose. We use pose independent representations, such as isometry-invariant shape characteristics, to represent identity features. Our model uses these features to supervise the prediction of offsets from the deformed pose to the result of the transfer. We show experimentally that our method outperforms state-of-the-art methods both quantitatively and qualitatively, and generalises better to poses not seen during training. We also introduce a fine-tuning step that allows to obtain competitive results for extreme identities, and allows to transfer simple clothing.