 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTAvatar: Bridging Gaussian Splatting and Texture Mapping for Relightable and Editable Gaussian Avatars
Dec 09, 2025



Recent advancements in Gaussian Splatting have enabled increasingly accurate reconstruction of photorealistic head avatars, opening the door to numerous applications in visual effects, videoconferencing, and virtual reality. This, however, comes with the lack of intuitive editability offered by traditional triangle mesh-based methods. In contrast, we propose a method that combines the accuracy and fidelity of 2D Gaussian Splatting with the intuitiveness of UV texture mapping. By embedding each canonical Gaussian primitive's local frame into a patch in the UV space of a template mesh in a computationally efficient manner, we reconstruct continuous editable material head textures from a single monocular video on a conventional UV domain. Furthermore, we leverage an efficient physically based reflectance model to enable relighting and editing of these intrinsic material maps. Through extensive comparisons with state-of-the-art methods, we demonstrate the accuracy of our reconstructions, the quality of our relighting results, and the ability to provide intuitive controls for modifying an avatar's appearance and geometry via texture mapping without additional optimization.
SPARK: Self-supervised Personalized Real-time Monocular Face Capture
Sep 12, 2024
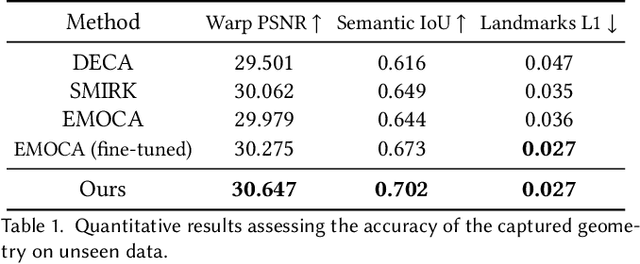
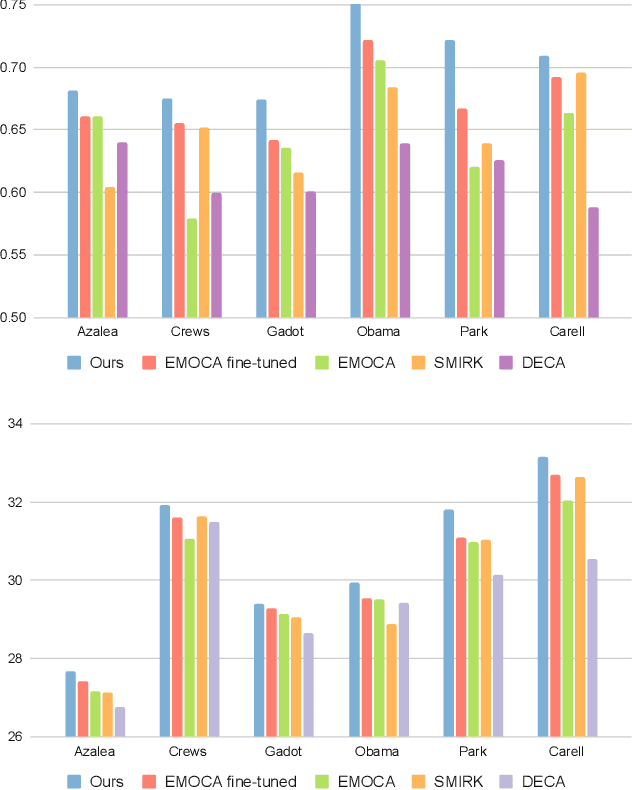
Feedforward monocular face capture methods seek to reconstruct posed faces from a single image of a person. Current state of the art approaches have the ability to regress parametric 3D face models in real-time across a wide range of identities, lighting conditions and poses by leveraging large image datasets of human faces. These methods however suffer from clear limitations in that the underlying parametric face model only provides a coarse estimation of the face shape, thereby limiting their practical applicability in tasks that require precise 3D reconstruction (aging, face swapping, digital make-up, ...). In this paper, we propose a method for high-precision 3D face capture taking advantage of a collection of unconstrained videos of a subject as prior information. Our proposal builds on a two stage approach. We start with the reconstruction of a detailed 3D face avatar of the person, capturing both precise geometry and appearance from a collection of videos. We then use the encoder from a pre-trained monocular face reconstruction method, substituting its decoder with our personalized model, and proceed with transfer learning on the video collection. Using our pre-estimated image formation model, we obtain a more precise self-supervision objective, enabling improved expression and pose alignment. This results in a trained encoder capable of efficiently regressing pose and expression parameters in real-time from previously unseen images, which combined with our personalized geometry model yields more accurate and high fidelity mesh inference. Through extensive qualitative and quantitative evaluation, we showcase the superiority of our final model as compared to state-of-the-art baselines, and demonstrate its generalization ability to unseen pose, expression and lighting.
* SIGGRAPH Asia 2024 Conference Paper. Project page: https://kelianb.github.io/SPARK/
FaceTuneGAN: Face Autoencoder for Convolutional Expression Transfer Using Neural Generative Adversarial Networks
Dec 01, 2021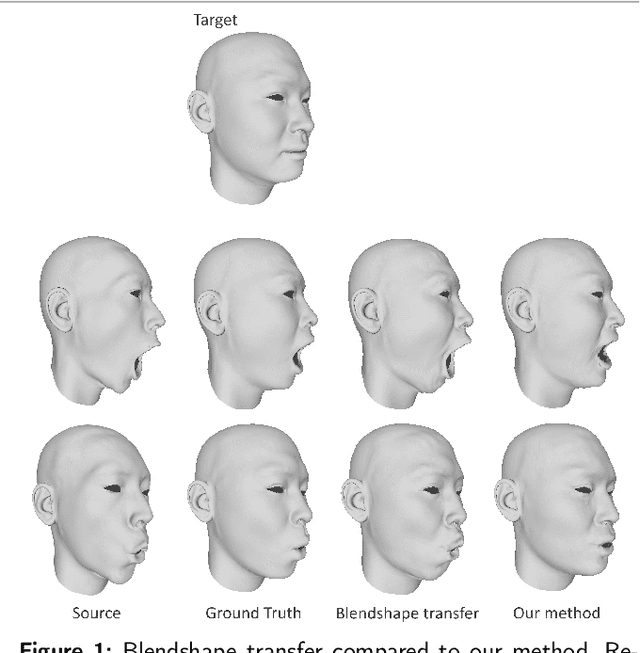

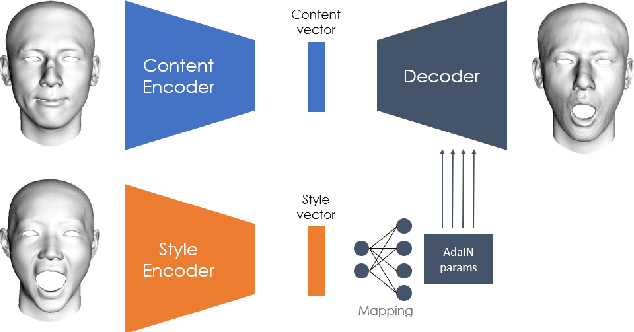
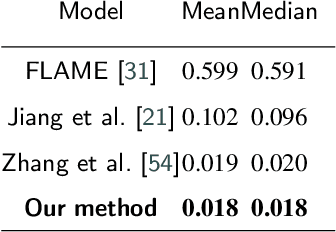
In this paper, we present FaceTuneGAN, a new 3D face model representation decomposing and encoding separately facial identity and facial expression. We propose a first adaptation of image-to-image translation networks, that have successfully been used in the 2D domain, to 3D face geometry. Leveraging recently released large face scan databases, a neural network has been trained to decouple factors of variations with a better knowledge of the face, enabling facial expressions transfer and neutralization of expressive faces. Specifically, we design an adversarial architecture adapting the base architecture of FUNIT and using SpiralNet++ for our convolutional and sampling operations. Using two publicly available datasets (FaceScape and CoMA), FaceTuneGAN has a better identity decomposition and face neutralization than state-of-the-art techniques. It also outperforms classical deformation transfer approach by predicting blendshapes closer to ground-truth data and with less of undesired artifacts due to too different facial morphologies between source and target.