 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactiveBench: Benchmarking Proactiveness in Multimodal Large Language Models
Mar 19, 2026Effective collaboration begins with knowing when to ask for help. For example, when trying to identify an occluded object, a human would ask someone to remove the obstruction. Can MLLMs exhibit a similar "proactive" behavior by requesting simple user interventions? To investigate this, we introduce ProactiveBench, a benchmark built from seven repurposed datasets that tests proactiveness across different tasks such as recognizing occluded objects, enhancing image quality, and interpreting coarse sketches. We evaluate 22 MLLMs on ProactiveBench, showing that (i) they generally lack proactiveness; (ii) proactiveness does not correlate with model capacity; (iii) "hinting" at proactiveness yields only marginal gains. Surprisingly, we found that conversation histories and in-context learning introduce negative biases, hindering performance. Finally, we explore a simple fine-tuning strategy based on reinforcement learning: its results suggest that proactiveness can be learned, even generalizing to unseen scenarios. We publicly release ProactiveBench as a first step toward building proactive multimodal models.
Group-robust Machine Unlearning
Mar 12, 2025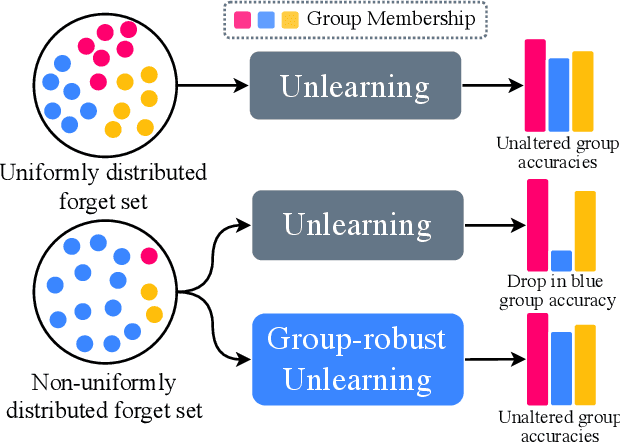
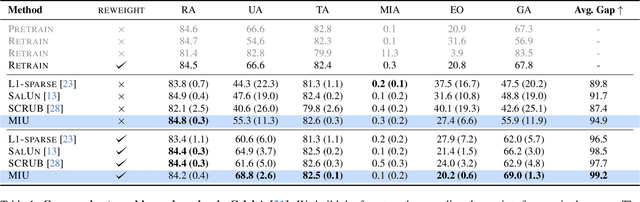
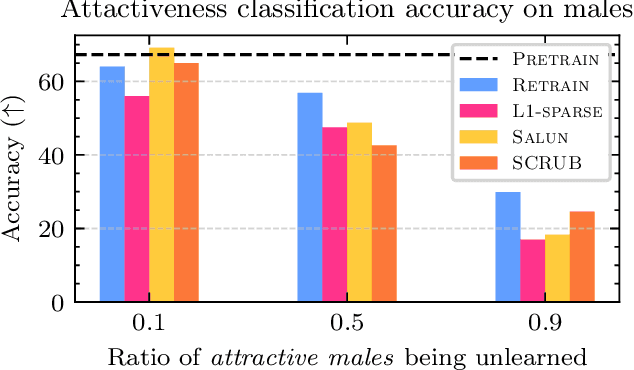
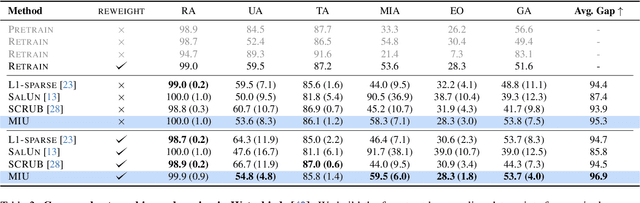
Machine unlearning is an emerging paradigm to remove the influence of specific training data (i.e., the forget set) from a model while preserving its knowledge of the rest of the data (i.e., the retain set). Previous approaches assume the forget data to be uniformly distributed from all training datapoints. However, if the data to unlearn is dominant in one group, we empirically show that performance for this group degrades, leading to fairness issues. This work tackles the overlooked problem of non-uniformly distributed forget sets, which we call group-robust machine unlearning, by presenting a simple, effective strategy that mitigates the performance loss in dominant groups via sample distribution reweighting. Moreover, we present MIU (Mutual Information-aware Machine Unlearning), the first approach for group robustness in approximate machine unlearning. MIU minimizes the mutual information between model features and group information, achieving unlearning while reducing performance degradation in the dominant group of the forget set. Additionally, MIU exploits sample distribution reweighting and mutual information calibration with the original model to preserve group robustness. We conduct experiments on three datasets and show that MIU outperforms standard methods, achieving unlearning without compromising model robustness. Source code available at https://github.com/tdemin16/group-robust_machine_unlearning.
Conditioned Prompt-Optimization for Continual Deepfake Detection
Jul 31, 2024



The rapid advancement of generative models has significantly enhanced the realism and customization of digital content creation. The increasing power of these tools, coupled with their ease of access, fuels the creation of photorealistic fake content, termed deepfakes, that raises substantial concerns about their potential misuse. In response, there has been notable progress in developing detection mechanisms to identify content produced by these advanced systems. However, existing methods often struggle to adapt to the continuously evolving landscape of deepfake generation. This paper introduces Prompt2Guard, a novel solution for exemplar-free continual deepfake detection of images, that leverages Vision-Language Models (VLMs) and domain-specific multimodal prompts. Compared to previous VLM-based approaches that are either bounded by prompt selection accuracy or necessitate multiple forward passes, we leverage a prediction ensembling technique with read-only prompts. Read-only prompts do not interact with VLMs internal representation, mitigating the need for multiple forward passes. Thus, we enhance efficiency and accuracy in detecting generated content. Additionally, our method exploits a text-prompt conditioning tailored to deepfake detection, which we demonstrate is beneficial in our setting. We evaluate Prompt2Guard on CDDB-Hard, a continual deepfake detection benchmark composed of five deepfake detection datasets spanning multiple domains and generators, achieving a new state-of-the-art. Additionally, our results underscore the effectiveness of our approach in addressing the challenges posed by continual deepfake detection, paving the way for more robust and adaptable solutions in deepfake detection.
One-Shot Unlearning of Personal Identities
Jul 16, 2024
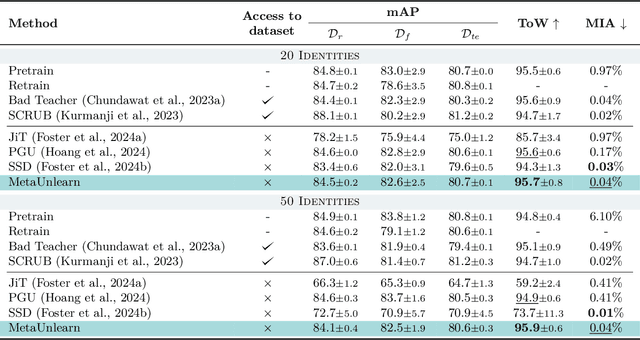
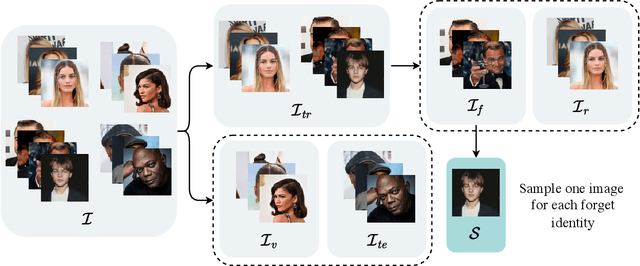
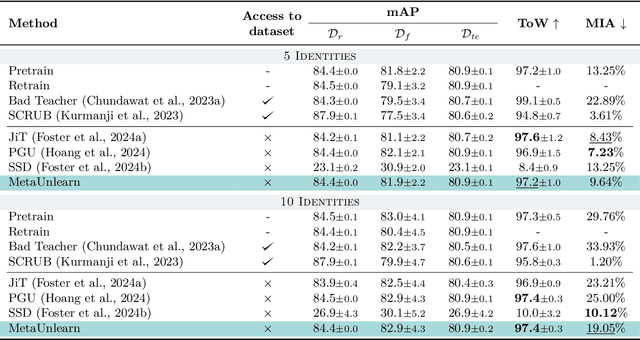
Machine unlearning (MU) aims to erase data from a model as if it never saw them during training. To this extent, existing MU approaches assume complete or partial access to the training data, which can be limited over time due to privacy regulations. However, no setting or benchmark exists to probe the effectiveness of MU methods in such scenarios, i.e. when training data is missing. To fill this gap, we propose a novel task we call One-Shot Unlearning of Personal Identities (O-UPI) that evaluates unlearning models when the training data is not accessible. Specifically, we focus on the identity unlearning case, which is relevant due to current regulations requiring data deletion after training. To cope with data absence, we expect users to provide a portraiting picture to perform unlearning. To evaluate methods in O-UPI, we benchmark the forgetting on CelebA and CelebA-HQ datasets with different unlearning set sizes. We test applicable methods on this challenging benchmark, proposing also an effective method that meta-learns to forget identities from a single image. Our findings indicate that existing approaches struggle when data availability is limited, with greater difficulty when there is dissimilarity between provided samples and data used at training time. We will release the code and benchmark upon acceptance.
Less is more: Summarizing Patch Tokens for efficient Multi-Label Class-Incremental Learning
May 24, 2024Prompt tuning has emerged as an effective rehearsal-free technique for class-incremental learning (CIL) that learns a tiny set of task-specific parameters (or prompts) to instruct a pre-trained transformer to learn on a sequence of tasks. Albeit effective, prompt tuning methods do not lend well in the multi-label class incremental learning (MLCIL) scenario (where an image contains multiple foreground classes) due to the ambiguity in selecting the correct prompt(s) corresponding to different foreground objects belonging to multiple tasks. To circumvent this issue we propose to eliminate the prompt selection mechanism by maintaining task-specific pathways, which allow us to learn representations that do not interact with the ones from the other tasks. Since independent pathways in truly incremental scenarios will result in an explosion of computation due to the quadratically complex multi-head self-attention (MSA) operation in prompt tuning, we propose to reduce the original patch token embeddings into summarized tokens. Prompt tuning is then applied to these fewer summarized tokens to compute the final representation. Our proposed method Multi-Label class incremental learning via summarising pAtch tokeN Embeddings (MULTI-LANE) enables learning disentangled task-specific representations in MLCIL while ensuring fast inference. We conduct experiments in common benchmarks and demonstrate that our MULTI-LANE achieves a new state-of-the-art in MLCIL. Additionally, we show that MULTI-LANE is also competitive in the CIL setting. Source code available at https://github.com/tdemin16/multi-lane
On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision Transformers
Aug 18, 2023



State-of-the-art rehearsal-free continual learning methods exploit the peculiarities of Vision Transformers to learn task-specific prompts, drastically reducing catastrophic forgetting. However, there is a tradeoff between the number of learned parameters and the performance, making such models computationally expensive. In this work, we aim to reduce this cost while maintaining competitive performance. We achieve this by revisiting and extending a simple transfer learning idea: learning task-specific normalization layers. Specifically, we tune the scale and bias parameters of LayerNorm for each continual learning task, selecting them at inference time based on the similarity between task-specific keys and the output of the pre-trained model. To make the classifier robust to incorrect selection of parameters during inference, we introduce a two-stage training procedure, where we first optimize the task-specific parameters and then train the classifier with the same selection procedure of the inference time. Experiments on ImageNet-R and CIFAR-100 show that our method achieves results that are either superior or on par with {the state of the art} while being computationally cheaper.