 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECAM: A Contrastive Learning Approach to Avoid Environmental Collision in Trajectory Forecasting
Jun 11, 2025



Human trajectory forecasting is crucial in applications such as autonomous driving, robotics and surveillance. Accurate forecasting requires models to consider various factors, including social interactions, multi-modal predictions, pedestrian intention and environmental context. While existing methods account for these factors, they often overlook the impact of the environment, which leads to collisions with obstacles. This paper introduces ECAM (Environmental Collision Avoidance Module), a contrastive learning-based module to enhance collision avoidance ability with the environment. The proposed module can be integrated into existing trajectory forecasting models, improving their ability to generate collision-free predictions. We evaluate our method on the ETH/UCY dataset and quantitatively and qualitatively demonstrate its collision avoidance capabilities. Our experiments show that state-of-the-art methods significantly reduce (-40/50%) the collision rate when integrated with the proposed module. The code is available at https://github.com/CVML-CFU/ECAM.
OVOSE: Open-Vocabulary Semantic Segmentation in Event-Based Cameras
Aug 18, 2024



Event cameras, known for low-latency operation and superior performance in challenging lighting conditions, are suitable for sensitive computer vision tasks such as semantic segmentation in autonomous driving. However, challenges arise due to limited event-based data and the absence of large-scale segmentation benchmarks. Current works are confined to closed-set semantic segmentation, limiting their adaptability to other applications. In this paper, we introduce OVOSE, the first Open-Vocabulary Semantic Segmentation algorithm for Event cameras. OVOSE leverages synthetic event data and knowledge distillation from a pre-trained image-based foundation model to an event-based counterpart, effectively preserving spatial context and transferring open-vocabulary semantic segmentation capabilities. We evaluate the performance of OVOSE on two driving semantic segmentation datasets DDD17, and DSEC-Semantic, comparing it with existing conventional image open-vocabulary models adapted for event-based data. Similarly, we compare OVOSE with state-of-the-art methods designed for closed-set settings in unsupervised domain adaptation for event-based semantic segmentation. OVOSE demonstrates superior performance, showcasing its potential for real-world applications. The code is available at https://github.com/ram95d/OVOSE.
Best Practices for 2-Body Pose Forecasting
Apr 12, 2023



The task of collaborative human pose forecasting stands for predicting the future poses of multiple interacting people, given those in previous frames. Predicting two people in interaction, instead of each separately, promises better performance, due to their body-body motion correlations. But the task has remained so far primarily unexplored. In this paper, we review the progress in human pose forecasting and provide an in-depth assessment of the single-person practices that perform best for 2-body collaborative motion forecasting. Our study confirms the positive impact of frequency input representations, space-time separable and fully-learnable interaction adjacencies for the encoding GCN and FC decoding. Other single-person practices do not transfer to 2-body, so the proposed best ones do not include hierarchical body modeling or attention-based interaction encoding. We further contribute a novel initialization procedure for the 2-body spatial interaction parameters of the encoder, which benefits performance and stability. Altogether, our proposed 2-body pose forecasting best practices yield a performance improvement of 21.9% over the state-of-the-art on the most recent ExPI dataset, whereby the novel initialization accounts for 3.5%. See our project page at https://www.pinlab.org/bestpractices2body
Adversarial Branch Architecture Search for Unsupervised Domain Adaptation
Mar 04, 2021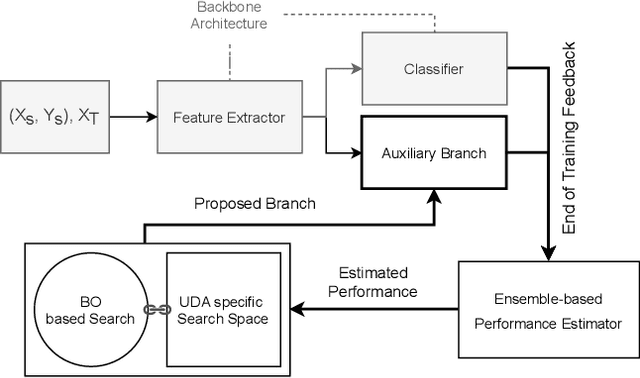
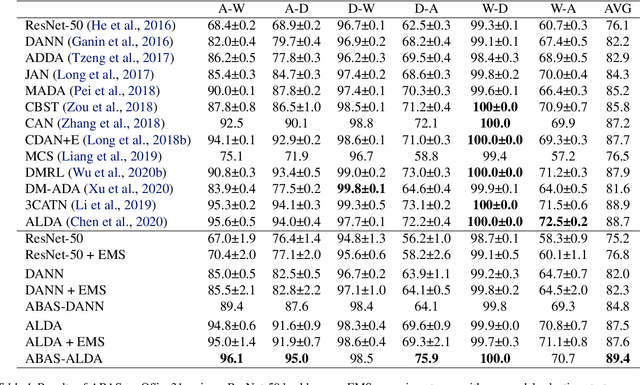
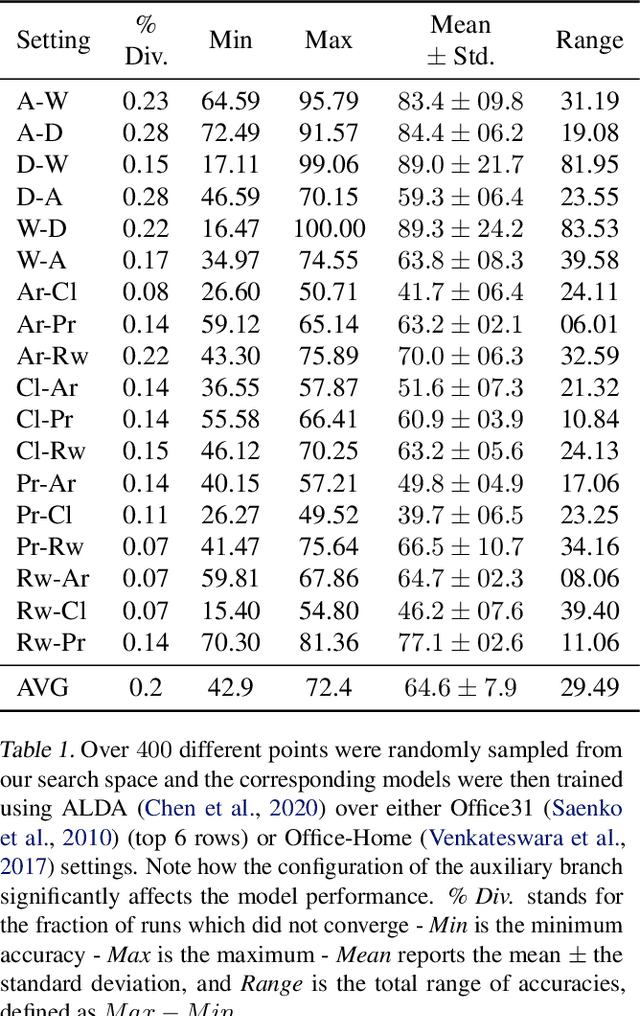
Unsupervised Domain Adaptation (UDA) is a key field in visual recognition, as it enables robust performances across different visual domains. In the deep learning era, the performance of UDA methods has been driven by better losses and by improved network architectures, specifically the addition of auxiliary domain-alignment branches to pre-trained backbones. However, all the neural architectures proposed so far are hand-crafted, which might hinder further progress. The current copious offspring of Neural Architecture Search (NAS) only alleviates hand-crafting so far, as it requires labels for model selection, which are not available in UDA, and is usually applied to the whole architecture, while using pre-trained models is a strict requirement for high performance. No prior work has addressed these aspects in the context of NAS for UDA. Here we propose an Adversarial Branch Architecture Search (ABAS) for UDA, to learn the auxiliary branch network from data without handcrafting. Our main contribution include i. a novel data-driven ensemble approach for model selection, to circumvent the lack of target labels, and ii. a pipeline to automatically search for the best performing auxiliary branch. To the best of our knowledge, ABAS is the first NAS method for UDA to comply with a pre-trained backbone, a strict requirement for high performance. ABAS outputs both the optimal auxiliary branch and its trained parameters. When applied to two modern UDA techniques, DANN and ALDA, it improves performance on three standard CV datasets (Office31, Office-Home and PACS). In all cases, ABAS robustly finds the branch architectures which yield best performances. Code will be released.