 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTI-PREGO: Chain of Thought and In-Context Learning for Online Mistake Detection in PRocedural EGOcentric Videos
Nov 04, 2024



Identifying procedural errors online from egocentric videos is a critical yet challenging task across various domains, including manufacturing, healthcare, and skill-based training. The nature of such mistakes is inherently open-set, as unforeseen or novel errors may occur, necessitating robust detection systems that do not rely on prior examples of failure. Currently, however, no technique effectively detects open-set procedural mistakes online. We propose a dual branch architecture to address this problem in an online fashion: one branch continuously performs step recognition from the input egocentric video, while the other anticipates future steps based on the recognition module's output. Mistakes are detected as mismatches between the currently recognized action and the action predicted by the anticipation module. The recognition branch takes input frames, predicts the current action, and aggregates frame-level results into action tokens. The anticipation branch, specifically, leverages the solid pattern-matching capabilities of Large Language Models (LLMs) to predict action tokens based on previously predicted ones. Given the online nature of the task, we also thoroughly benchmark the difficulties associated with per-frame evaluations, particularly the need for accurate and timely predictions in dynamic online scenarios. Extensive experiments on two procedural datasets demonstrate the challenges and opportunities of leveraging a dual-branch architecture for mistake detection, showcasing the effectiveness of our proposed approach. In a thorough evaluation including recognition and anticipation variants and state-of-the-art models, our method reveals its robustness and effectiveness in online applications.
Compositional Entailment Learning for Hyperbolic Vision-Language Models
Oct 09, 2024



Image-text representation learning forms a cornerstone in vision-language models, where pairs of images and textual descriptions are contrastively aligned in a shared embedding space. Since visual and textual concepts are naturally hierarchical, recent work has shown that hyperbolic space can serve as a high-potential manifold to learn vision-language representation with strong downstream performance. In this work, for the first time we show how to fully leverage the innate hierarchical nature of hyperbolic embeddings by looking beyond individual image-text pairs. We propose Compositional Entailment Learning for hyperbolic vision-language models. The idea is that an image is not only described by a sentence but is itself a composition of multiple object boxes, each with their own textual description. Such information can be obtained freely by extracting nouns from sentences and using openly available localized grounding models. We show how to hierarchically organize images, image boxes, and their textual descriptions through contrastive and entailment-based objectives. Empirical evaluation on a hyperbolic vision-language model trained with millions of image-text pairs shows that the proposed compositional learning approach outperforms conventional Euclidean CLIP learning, as well as recent hyperbolic alternatives, with better zero-shot and retrieval generalization and clearly stronger hierarchical performance.
Hyp2Nav: Hyperbolic Planning and Curiosity for Crowd Navigation
Jul 19, 2024



Autonomous robots are increasingly becoming a strong fixture in social environments. Effective crowd navigation requires not only safe yet fast planning, but should also enable interpretability and computational efficiency for working in real-time on embedded devices. In this work, we advocate for hyperbolic learning to enable crowd navigation and we introduce Hyp2Nav. Different from conventional reinforcement learning-based crowd navigation methods, Hyp2Nav leverages the intrinsic properties of hyperbolic geometry to better encode the hierarchical nature of decision-making processes in navigation tasks. We propose a hyperbolic policy model and a hyperbolic curiosity module that results in effective social navigation, best success rates, and returns across multiple simulation settings, using up to 6 times fewer parameters than competitor state-of-the-art models. With our approach, it becomes even possible to obtain policies that work in 2-dimensional embedding spaces, opening up new possibilities for low-resource crowd navigation and model interpretability. Insightfully, the internal hyperbolic representation of Hyp2Nav correlates with how much attention the robot pays to the surrounding crowds, e.g. due to multiple people occluding its pathway or to a few of them showing colliding plans, rather than to its own planned route.
PREGO: online mistake detection in PRocedural EGOcentric videos
Apr 02, 2024



Promptly identifying procedural errors from egocentric videos in an online setting is highly challenging and valuable for detecting mistakes as soon as they happen. This capability has a wide range of applications across various fields, such as manufacturing and healthcare. The nature of procedural mistakes is open-set since novel types of failures might occur, which calls for one-class classifiers trained on correctly executed procedures. However, no technique can currently detect open-set procedural mistakes online. We propose PREGO, the first online one-class classification model for mistake detection in PRocedural EGOcentric videos. PREGO is based on an online action recognition component to model the current action, and a symbolic reasoning module to predict the next actions. Mistake detection is performed by comparing the recognized current action with the expected future one. We evaluate PREGO on two procedural egocentric video datasets, Assembly101 and Epic-tent, which we adapt for online benchmarking of procedural mistake detection to establish suitable benchmarks, thus defining the Assembly101-O and Epic-tent-O datasets, respectively.
Multimodal Motion Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
Jul 14, 2023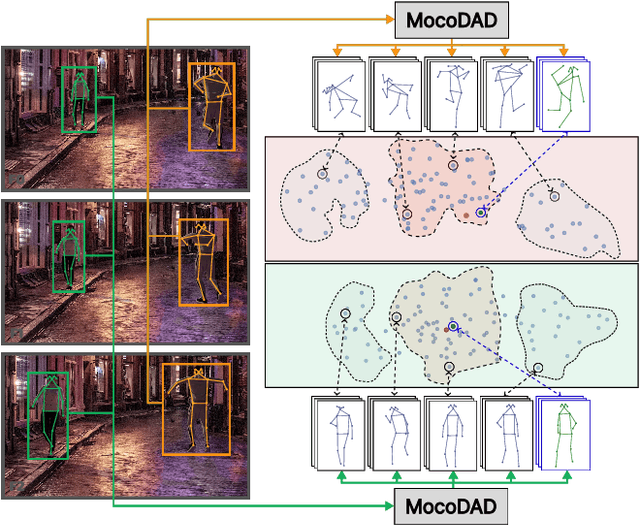
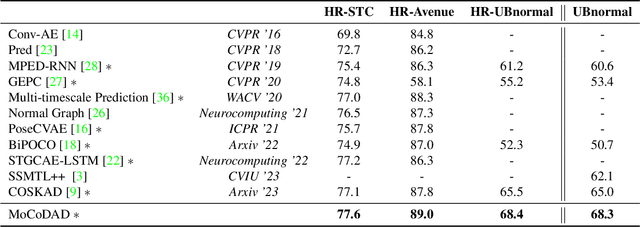
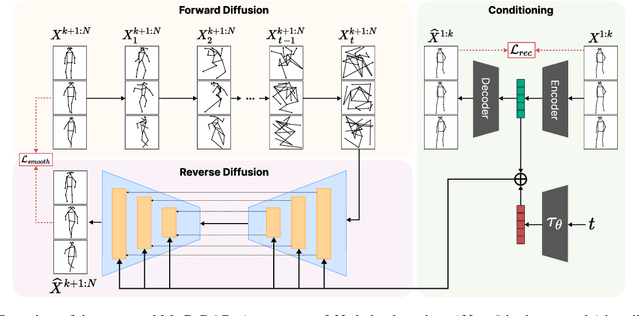
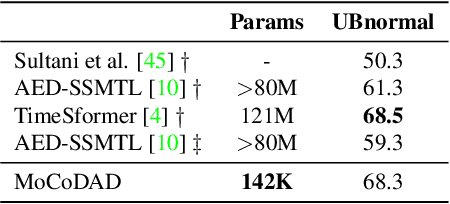
Anomalies are rare and anomaly detection is often therefore framed as One-Class Classification (OCC), i.e. trained solely on normalcy. Leading OCC techniques constrain the latent representations of normal motions to limited volumes and detect as abnormal anything outside, which accounts satisfactorily for the openset'ness of anomalies. But normalcy shares the same openset'ness property, since humans can perform the same action in several ways, which the leading techniques neglect. We propose a novel generative model for video anomaly detection (VAD), which assumes that both normality and abnormality are multimodal. We consider skeletal representations and leverage state-of-the-art diffusion probabilistic models to generate multimodal future human poses. We contribute a novel conditioning on the past motion of people, and exploit the improved mode coverage capabilities of diffusion processes to generate different-but-plausible future motions. Upon the statistical aggregation of future modes, anomaly is detected when the generated set of motions is not pertinent to the actual future. We validate our model on 4 established benchmarks: UBnormal, HR-UBnormal, HR-STC, and HR-Avenue, with extensive experiments surpassing state-of-the-art results.
Best Practices for 2-Body Pose Forecasting
Apr 12, 2023The task of collaborative human pose forecasting stands for predicting the future poses of multiple interacting people, given those in previous frames. Predicting two people in interaction, instead of each separately, promises better performance, due to their body-body motion correlations. But the task has remained so far primarily unexplored. In this paper, we review the progress in human pose forecasting and provide an in-depth assessment of the single-person practices that perform best for 2-body collaborative motion forecasting. Our study confirms the positive impact of frequency input representations, space-time separable and fully-learnable interaction adjacencies for the encoding GCN and FC decoding. Other single-person practices do not transfer to 2-body, so the proposed best ones do not include hierarchical body modeling or attention-based interaction encoding. We further contribute a novel initialization procedure for the 2-body spatial interaction parameters of the encoder, which benefits performance and stability. Altogether, our proposed 2-body pose forecasting best practices yield a performance improvement of 21.9% over the state-of-the-art on the most recent ExPI dataset, whereby the novel initialization accounts for 3.5%. See our project page at https://www.pinlab.org/bestpractices2body
Contracting Skeletal Kinematic Embeddings for Anomaly Detection
Jan 23, 2023



Detecting the anomaly of human behavior is paramount to timely recognizing endangering situations, such as street fights or elderly falls. However, anomaly detection is complex, since anomalous events are rare and because it is an open set recognition task, i.e., what is anomalous at inference has not been observed at training. We propose COSKAD, a novel model which encodes skeletal human motion by an efficient graph convolutional network and learns to COntract SKeletal kinematic embeddings onto a latent hypersphere of minimum volume for Anomaly Detection. We propose and analyze three latent space designs for COSKAD: the commonly-adopted Euclidean, and the new spherical-radial and hyperbolic volumes. All three variants outperform the state-of-the-art, including video-based techniques, on the ShangaiTechCampus, the Avenue, and on the most recent UBnormal dataset, for which we contribute novel skeleton annotations and the selection of human-related videos. The source code and dataset will be released upon acceptance.
Are we certain it's anomalous?
Nov 16, 2022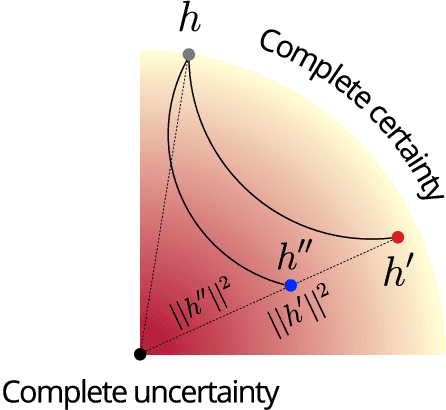

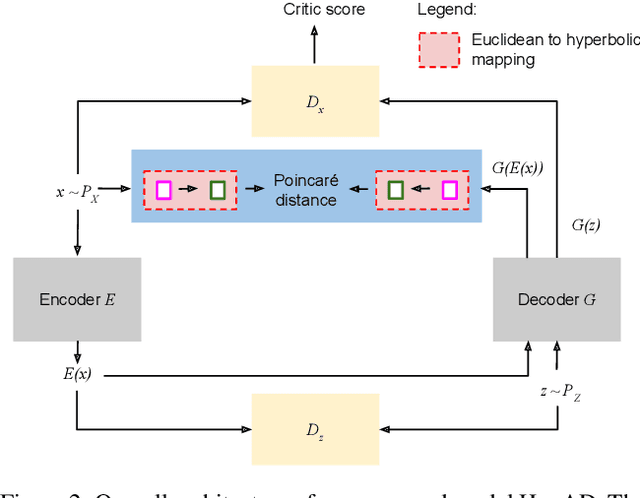

The progress in modelling time series and, more generally, sequences of structured-data has recently revamped research in anomaly detection. The task stands for identifying abnormal behaviours in financial series, IT systems, aerospace measurements, and the medical domain, where anomaly detection may aid in isolating cases of depression and attend the elderly. Anomaly detection in time series is a complex task since anomalies are rare due to highly non-linear temporal correlations and since the definition of anomalous is sometimes subjective. Here we propose the novel use of Hyperbolic uncertainty for Anomaly Detection (HypAD). HypAD learns self-supervisedly to reconstruct the input signal. We adopt best practices from the state-of-the-art to encode the sequence by an LSTM, jointly learnt with a decoder to reconstruct the signal, with the aid of GAN critics. Uncertainty is estimated end-to-end by means of a hyperbolic neural network. By using uncertainty, HypAD may assess whether it is certain about the input signal but it fails to reconstruct it because this is anomalous; or whether the reconstruction error does not necessarily imply anomaly, as the model is uncertain, e.g. a complex but regular input signal. The novel key idea is that a detectable anomaly is one where the model is certain but it predicts wrongly. HypAD outperforms the current state-of-the-art for univariate anomaly detection on established benchmarks based on data from NASA, Yahoo, Numenta, Amazon, Twitter. It also yields state-of-the-art performance on a multivariate dataset of anomaly activities in elderly home residences, and it outperforms the baseline on SWaT. Overall, HypAD yields the lowest false alarms at the best performance rate, thanks to successfully identifying detectable anomalies.
Query-Guided Networks for Few-shot Fine-grained Classification and Person Search
Sep 21, 2022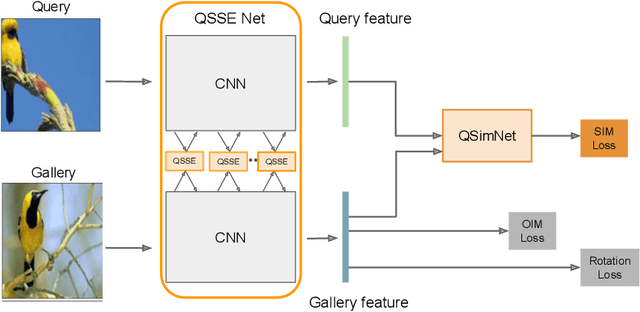
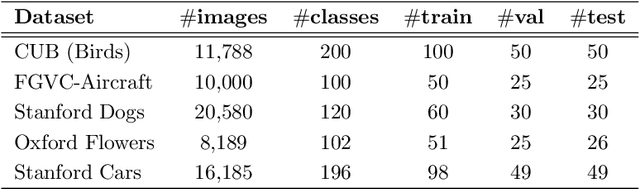
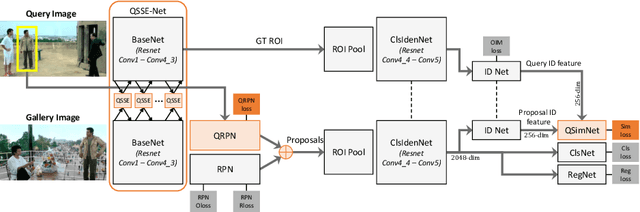
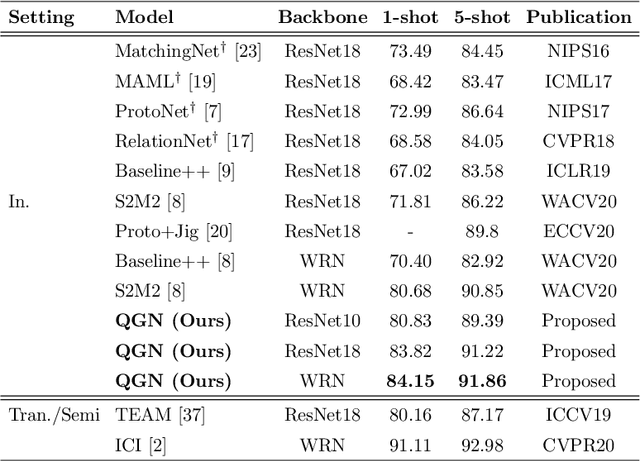
Few-shot fine-grained classification and person search appear as distinct tasks and literature has treated them separately. But a closer look unveils important similarities: both tasks target categories that can only be discriminated by specific object details; and the relevant models should generalize to new categories, not seen during training. We propose a novel unified Query-Guided Network (QGN) applicable to both tasks. QGN consists of a Query-guided Siamese-Squeeze-and-Excitation subnetwork which re-weights both the query and gallery features across all network layers, a Query-guided Region Proposal subnetwork for query-specific localisation, and a Query-guided Similarity subnetwork for metric learning. QGN improves on a few recent few-shot fine-grained datasets, outperforming other techniques on CUB by a large margin. QGN also performs competitively on the person search CUHK-SYSU and PRW datasets, where we perform in-depth analysis.