 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-RECS, a Low-Cost LLM4VIS Recommender with Explanations, Captioning and Suggestions
Jun 21, 2024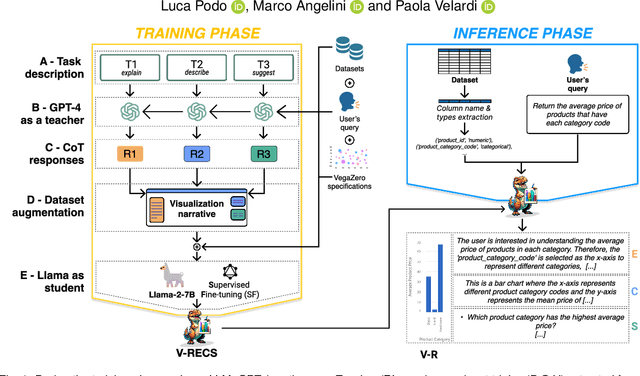



NL2VIS (natural language to visualization) is a promising and recent research area that involves interpreting natural language queries and translating them into visualizations that accurately represent the underlying data. As we navigate the era of big data, NL2VIS holds considerable application potential since it greatly facilitates data exploration by non-expert users. Following the increasingly widespread usage of generative AI in NL2VIS applications, in this paper we present V-RECS, the first LLM-based Visual Recommender augmented with explanations(E), captioning(C), and suggestions(S) for further data exploration. V-RECS' visualization narratives facilitate both response verification and data exploration by non-expert users. Furthermore, our proposed solution mitigates computational, controllability, and cost issues associated with using powerful LLMs by leveraging a methodology to effectively fine-tune small models. To generate insightful visualization narratives, we use Chain-of-Thoughts (CoT), a prompt engineering technique to help LLM identify and generate the logical steps to produce a correct answer. Since CoT is reported to perform poorly with small LLMs, we adopted a strategy in which a large LLM (GPT-4), acting as a Teacher, generates CoT-based instructions to fine-tune a small model, Llama-2-7B, which plays the role of a Student. Extensive experiments-based on a framework for the quantitative evaluation of AI-based visualizations and on manual assessment by a group of participants-show that V-RECS achieves performance scores comparable to GPT-4, at a much lower cost. The efficacy of the V-RECS teacher-student paradigm is also demonstrated by the fact that the un-tuned Llama fails to perform the task in the vast majority of test cases. We release V-RECS for the visualization community to assist visualization designers throughout the entire visualization generation process.
Viva LLM! A Conceptual Stack for Evaluating and Interpreting Generative AI-based Visualizations
Feb 03, 2024



The automatic generation of visualizations is an old task that, through the years, has shown more and more interest from the research and practitioner communities. Recently, large language models (LLM) have become an interesting option for supporting generative tasks related to visualization, demonstrating initial promising results. At the same time, several pitfalls, like the multiple ways of instructing an LLM to generate the desired result, the different perspectives leading the generation (code-based, image-based, grammar-based), and the presence of hallucinations even for the visualization generation task, make their usage less affordable than expected. Following similar initiatives for benchmarking LLMs, this paper copes with the problem of modeling the evaluation of a generated visualization through an LLM. We propose a theoretical evaluation stack, EvaLLM, that decomposes the evaluation effort in its atomic components, characterizes their nature, and provides an overview of how to implement and interpret them. We also designed and implemented an evaluation platform that provides a benchmarking resource for the visualization generation task. The platform supports automatic and manual scoring conducted by multiple assessors to support a fine-grained and semantic evaluation based on the EvaLLM stack. Two case studies on GPT3.5-turbo with Code Interpreter and Llama2-70-b models show the benefits of EvaLLM and illustrate interesting results on the current state-of-the-art LLM-generated visualizations.
Machine Learning for Visualization Recommendation Systems: Open Challenges and Future Directions
Feb 01, 2023Visualization Recommendation Systems (VRS) are a novel and challenging field of study, whose aim is to automatically generate insightful visualizations from data, to support non-expert users in the process of information discovery. Despite its enormous application potential in the era of big data, progress in this area of research is being held back by several obstacles among which are the absence of standardized datasets to train recommendation algorithms, and the difficulty in defining quantitative criteria to assess the effectiveness of the generated plots. In this paper, we aim not only to summarize the state-of-the-art of VRS, but also to outline promising future research directions.
Are we certain it's anomalous?
Nov 16, 2022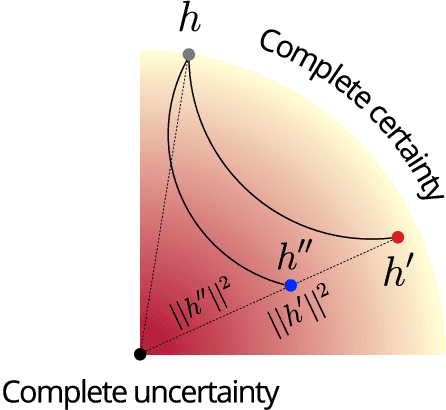

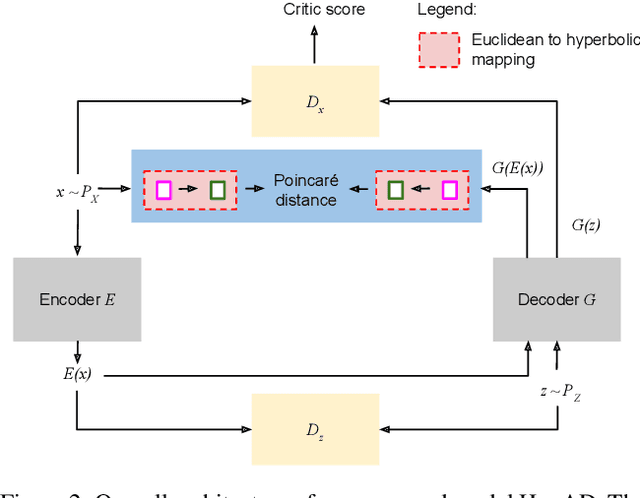

The progress in modelling time series and, more generally, sequences of structured-data has recently revamped research in anomaly detection. The task stands for identifying abnormal behaviours in financial series, IT systems, aerospace measurements, and the medical domain, where anomaly detection may aid in isolating cases of depression and attend the elderly. Anomaly detection in time series is a complex task since anomalies are rare due to highly non-linear temporal correlations and since the definition of anomalous is sometimes subjective. Here we propose the novel use of Hyperbolic uncertainty for Anomaly Detection (HypAD). HypAD learns self-supervisedly to reconstruct the input signal. We adopt best practices from the state-of-the-art to encode the sequence by an LSTM, jointly learnt with a decoder to reconstruct the signal, with the aid of GAN critics. Uncertainty is estimated end-to-end by means of a hyperbolic neural network. By using uncertainty, HypAD may assess whether it is certain about the input signal but it fails to reconstruct it because this is anomalous; or whether the reconstruction error does not necessarily imply anomaly, as the model is uncertain, e.g. a complex but regular input signal. The novel key idea is that a detectable anomaly is one where the model is certain but it predicts wrongly. HypAD outperforms the current state-of-the-art for univariate anomaly detection on established benchmarks based on data from NASA, Yahoo, Numenta, Amazon, Twitter. It also yields state-of-the-art performance on a multivariate dataset of anomaly activities in elderly home residences, and it outperforms the baseline on SWaT. Overall, HypAD yields the lowest false alarms at the best performance rate, thanks to successfully identifying detectable anomalies.