 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrue (VIS) Lies: Analyzing How Generative AI Recognizes Intentionality, Rhetoric, and Misleadingness in Visualization Lies
Apr 01, 2026This study investigates the ability of multimodal Large Language Models (LLMs) to identify and interpret misleading visualizations, and recognize these observations along with their underlying causes and potential intentionality. Our analysis leverages concepts from visualization rhetoric and a newly developed taxonomy of authorial intents as explanatory lenses. We formulated three research questions and addressed them experimentally using a dataset of 2,336 COVID-19-related tweets, half of which contain misleading visualizations, and supplemented it with real-world examples of perceptual, cognitive, and conceptual errors drawn from VisLies, the IEEE VIS community event dedicated to showcasing deceptive and misleading visualizations. To ensure broad coverage of the current LLM landscape, we evaluated 16 state-of-the-art models. Among them, 15 are open-weight models, spanning a wide range of model sizes, architectural families, and reasoning capabilities. The selection comprises small models, namely Nemotron-Nano-V2-VL (12B parameters), Mistral-Small-3.2 (24B), DeepSeek-VL2 (27B), Gemma3 (27B), and GTA1 (32B); medium-sized models, namely Qianfan-VL (70B), Molmo (72B), GLM-4.5V (108B), LLaVA-NeXT (110B), and Pixtral-Large (124B); and large models, namely Qwen3-VL (235B), InternVL3.5 (241B), Step3 (321B), Llama-4-Maverick (400B), and Kimi-K2.5 (1000B). In addition, we employed OpenAI GPT-5.4, a frontier proprietary model. To establish a human perspective on these tasks, we also conducted a user study with visualization experts to assess how people perceive rhetorical techniques and the authorial intentions behind the same misleading visualizations. This allows comparison between model and expert behavior, revealing similarities and differences that provide insights into where LLMs align with human judgment and where they diverge.
Cyri: A Conversational AI-based Assistant for Supporting the Human User in Detecting and Responding to Phishing Attacks
Feb 09, 2025This work introduces Cyri, an AI-powered conversational assistant designed to support a human user in detecting and analyzing phishing emails by leveraging Large Language Models. Cyri has been designed to scrutinize emails for semantic features used in phishing attacks, such as urgency, and undesirable consequences, using an approach that unifies features already established in the literature with others by Cyri features extraction methodology. Cyri can be directly plugged into a client mail or webmail, ensuring seamless integration with the user's email workflow while maintaining data privacy through local processing. By performing analyses on the user's machine, Cyri eliminates the need to transmit sensitive email data over the internet, reducing associated security risks. The Cyri user interface has been designed to reduce habituation effects and enhance user engagement. It employs dynamic visual cues and context-specific explanations to keep users alert and informed while using emails. Additionally, it allows users to explore identified malicious semantic features both through conversation with the agent and visual exploration, obtaining the advantages of both modalities for expert or non-expert users. It also allows users to keep track of the conversation, supports the user in solving additional questions on both computed features or new parts of the mail, and applies its detection on demand. To evaluate Cyri, we crafted a comprehensive dataset of 420 phishing emails and 420 legitimate emails. Results demonstrate high effectiveness in identifying critical phishing semantic features fundamental to phishing detection. A user study involving 10 participants, both experts and non-experts, evaluated Cyri's effectiveness and usability. Results indicated that Cyri significantly aided users in identifying phishing emails and enhanced their understanding of phishing tactics.
V-RECS, a Low-Cost LLM4VIS Recommender with Explanations, Captioning and Suggestions
Jun 21, 2024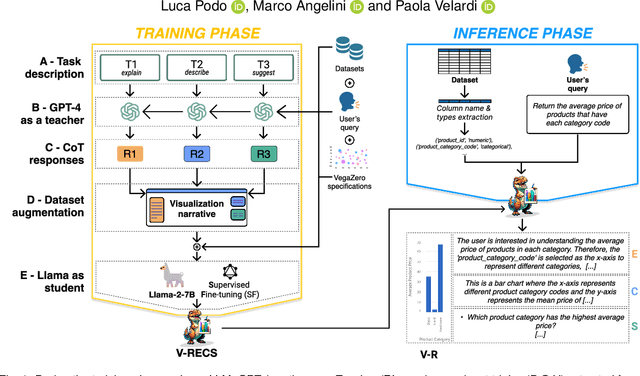



NL2VIS (natural language to visualization) is a promising and recent research area that involves interpreting natural language queries and translating them into visualizations that accurately represent the underlying data. As we navigate the era of big data, NL2VIS holds considerable application potential since it greatly facilitates data exploration by non-expert users. Following the increasingly widespread usage of generative AI in NL2VIS applications, in this paper we present V-RECS, the first LLM-based Visual Recommender augmented with explanations(E), captioning(C), and suggestions(S) for further data exploration. V-RECS' visualization narratives facilitate both response verification and data exploration by non-expert users. Furthermore, our proposed solution mitigates computational, controllability, and cost issues associated with using powerful LLMs by leveraging a methodology to effectively fine-tune small models. To generate insightful visualization narratives, we use Chain-of-Thoughts (CoT), a prompt engineering technique to help LLM identify and generate the logical steps to produce a correct answer. Since CoT is reported to perform poorly with small LLMs, we adopted a strategy in which a large LLM (GPT-4), acting as a Teacher, generates CoT-based instructions to fine-tune a small model, Llama-2-7B, which plays the role of a Student. Extensive experiments-based on a framework for the quantitative evaluation of AI-based visualizations and on manual assessment by a group of participants-show that V-RECS achieves performance scores comparable to GPT-4, at a much lower cost. The efficacy of the V-RECS teacher-student paradigm is also demonstrated by the fact that the un-tuned Llama fails to perform the task in the vast majority of test cases. We release V-RECS for the visualization community to assist visualization designers throughout the entire visualization generation process.
Viva LLM! A Conceptual Stack for Evaluating and Interpreting Generative AI-based Visualizations
Feb 03, 2024



The automatic generation of visualizations is an old task that, through the years, has shown more and more interest from the research and practitioner communities. Recently, large language models (LLM) have become an interesting option for supporting generative tasks related to visualization, demonstrating initial promising results. At the same time, several pitfalls, like the multiple ways of instructing an LLM to generate the desired result, the different perspectives leading the generation (code-based, image-based, grammar-based), and the presence of hallucinations even for the visualization generation task, make their usage less affordable than expected. Following similar initiatives for benchmarking LLMs, this paper copes with the problem of modeling the evaluation of a generated visualization through an LLM. We propose a theoretical evaluation stack, EvaLLM, that decomposes the evaluation effort in its atomic components, characterizes their nature, and provides an overview of how to implement and interpret them. We also designed and implemented an evaluation platform that provides a benchmarking resource for the visualization generation task. The platform supports automatic and manual scoring conducted by multiple assessors to support a fine-grained and semantic evaluation based on the EvaLLM stack. Two case studies on GPT3.5-turbo with Code Interpreter and Llama2-70-b models show the benefits of EvaLLM and illustrate interesting results on the current state-of-the-art LLM-generated visualizations.