 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-RECS, a Low-Cost LLM4VIS Recommender with Explanations, Captioning and Suggestions
Paper and Code
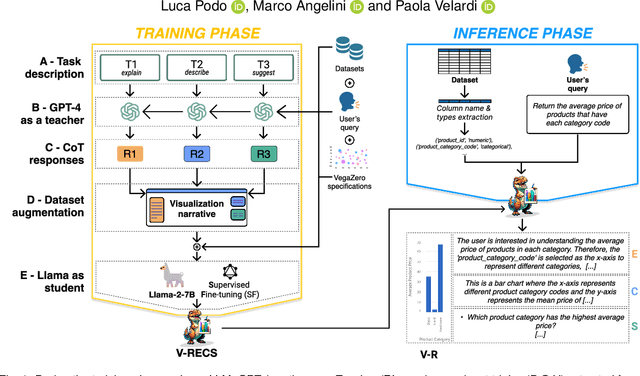



NL2VIS (natural language to visualization) is a promising and recent research area that involves interpreting natural language queries and translating them into visualizations that accurately represent the underlying data. As we navigate the era of big data, NL2VIS holds considerable application potential since it greatly facilitates data exploration by non-expert users. Following the increasingly widespread usage of generative AI in NL2VIS applications, in this paper we present V-RECS, the first LLM-based Visual Recommender augmented with explanations(E), captioning(C), and suggestions(S) for further data exploration. V-RECS' visualization narratives facilitate both response verification and data exploration by non-expert users. Furthermore, our proposed solution mitigates computational, controllability, and cost issues associated with using powerful LLMs by leveraging a methodology to effectively fine-tune small models. To generate insightful visualization narratives, we use Chain-of-Thoughts (CoT), a prompt engineering technique to help LLM identify and generate the logical steps to produce a correct answer. Since CoT is reported to perform poorly with small LLMs, we adopted a strategy in which a large LLM (GPT-4), acting as a Teacher, generates CoT-based instructions to fine-tune a small model, Llama-2-7B, which plays the role of a Student. Extensive experiments-based on a framework for the quantitative evaluation of AI-based visualizations and on manual assessment by a group of participants-show that V-RECS achieves performance scores comparable to GPT-4, at a much lower cost. The efficacy of the V-RECS teacher-student paradigm is also demonstrated by the fact that the un-tuned Llama fails to perform the task in the vast majority of test cases. We release V-RECS for the visualization community to assist visualization designers throughout the entire visualization generation process.