 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYperbolic Self-Paced Learning for Self-Supervised Skeleton-based Action Representations
Mar 10, 2023Self-paced learning has been beneficial for tasks where some initial knowledge is available, such as weakly supervised learning and domain adaptation, to select and order the training sample sequence, from easy to complex. However its applicability remains unexplored in unsupervised learning, whereby the knowledge of the task matures during training. We propose a novel HYperbolic Self-Paced model (HYSP) for learning skeleton-based action representations. HYSP adopts self-supervision: it uses data augmentations to generate two views of the same sample, and it learns by matching one (named online) to the other (the target). We propose to use hyperbolic uncertainty to determine the algorithmic learning pace, under the assumption that less uncertain samples should be more strongly driving the training, with a larger weight and pace. Hyperbolic uncertainty is a by-product of the adopted hyperbolic neural networks, it matures during training and it comes with no extra cost, compared to the established Euclidean SSL framework counterparts. When tested on three established skeleton-based action recognition datasets, HYSP outperforms the state-of-the-art on PKU-MMD I, as well as on 2 out of 3 downstream tasks on NTU-60 and NTU-120. Additionally, HYSP only uses positive pairs and bypasses therefore the complex and computationally-demanding mining procedures required for the negatives in contrastive techniques. Code is available at https://github.com/paolomandica/HYSP.
Are we certain it's anomalous?
Nov 16, 2022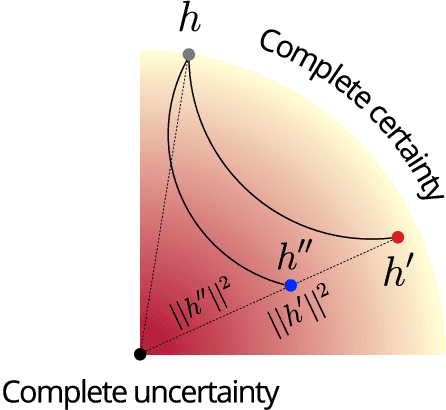

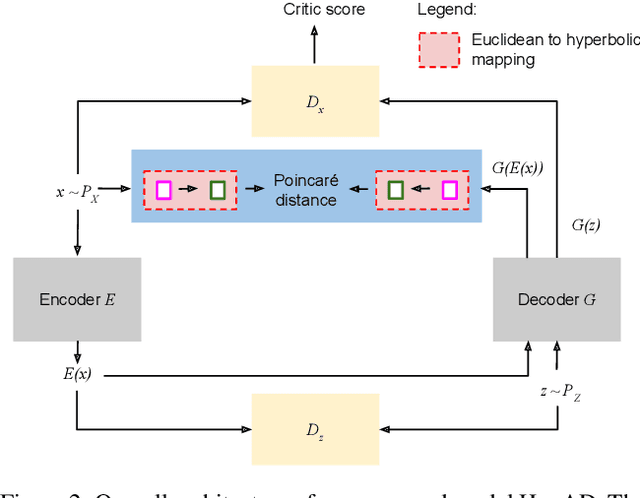

The progress in modelling time series and, more generally, sequences of structured-data has recently revamped research in anomaly detection. The task stands for identifying abnormal behaviours in financial series, IT systems, aerospace measurements, and the medical domain, where anomaly detection may aid in isolating cases of depression and attend the elderly. Anomaly detection in time series is a complex task since anomalies are rare due to highly non-linear temporal correlations and since the definition of anomalous is sometimes subjective. Here we propose the novel use of Hyperbolic uncertainty for Anomaly Detection (HypAD). HypAD learns self-supervisedly to reconstruct the input signal. We adopt best practices from the state-of-the-art to encode the sequence by an LSTM, jointly learnt with a decoder to reconstruct the signal, with the aid of GAN critics. Uncertainty is estimated end-to-end by means of a hyperbolic neural network. By using uncertainty, HypAD may assess whether it is certain about the input signal but it fails to reconstruct it because this is anomalous; or whether the reconstruction error does not necessarily imply anomaly, as the model is uncertain, e.g. a complex but regular input signal. The novel key idea is that a detectable anomaly is one where the model is certain but it predicts wrongly. HypAD outperforms the current state-of-the-art for univariate anomaly detection on established benchmarks based on data from NASA, Yahoo, Numenta, Amazon, Twitter. It also yields state-of-the-art performance on a multivariate dataset of anomaly activities in elderly home residences, and it outperforms the baseline on SWaT. Overall, HypAD yields the lowest false alarms at the best performance rate, thanks to successfully identifying detectable anomalies.
Query-Guided Networks for Few-shot Fine-grained Classification and Person Search
Sep 21, 2022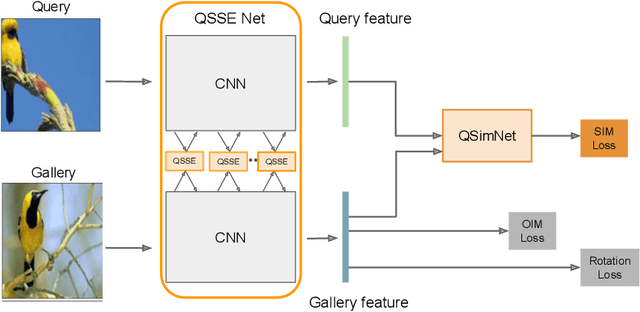
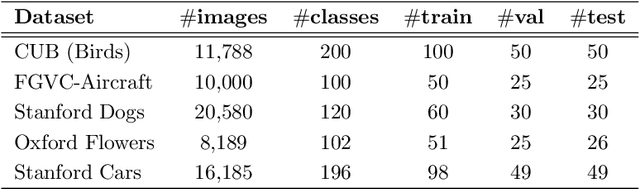
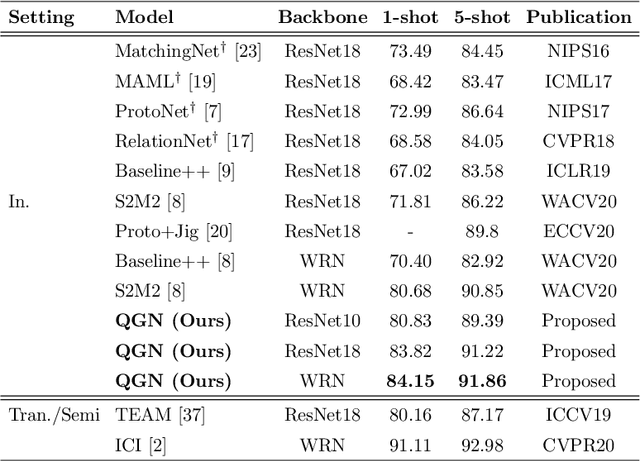
Few-shot fine-grained classification and person search appear as distinct tasks and literature has treated them separately. But a closer look unveils important similarities: both tasks target categories that can only be discriminated by specific object details; and the relevant models should generalize to new categories, not seen during training. We propose a novel unified Query-Guided Network (QGN) applicable to both tasks. QGN consists of a Query-guided Siamese-Squeeze-and-Excitation subnetwork which re-weights both the query and gallery features across all network layers, a Query-guided Region Proposal subnetwork for query-specific localisation, and a Query-guided Similarity subnetwork for metric learning. QGN improves on a few recent few-shot fine-grained datasets, outperforming other techniques on CUB by a large margin. QGN also performs competitively on the person search CUHK-SYSU and PRW datasets, where we perform in-depth analysis.
Class Interference Regularization
Sep 04, 2020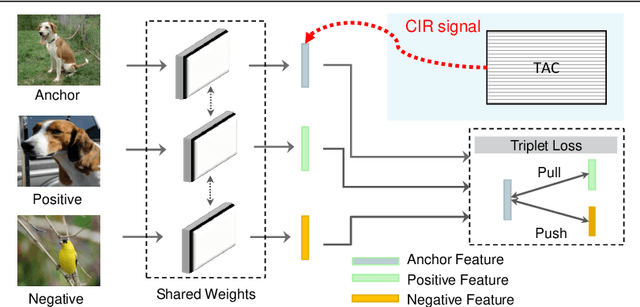
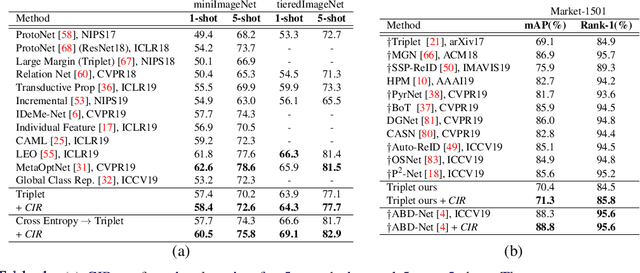

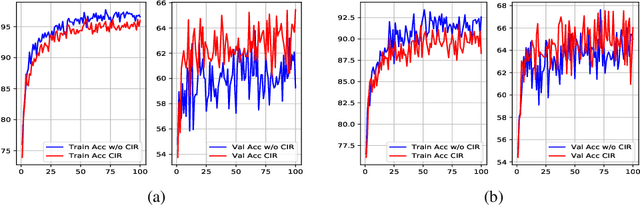
Contrastive losses yield state-of-the-art performance for person re-identification, face verification and few shot learning. They have recently outperformed the cross-entropy loss on classification at the ImageNet scale and outperformed all self-supervision prior results by a large margin (SimCLR). Simple and effective regularization techniques such as label smoothing and self-distillation do not apply anymore, because they act on multinomial label distributions, adopted in cross-entropy losses, and not on tuple comparative terms, which characterize the contrastive losses. Here we propose a novel, simple and effective regularization technique, the Class Interference Regularization (CIR), which applies to cross-entropy losses but is especially effective on contrastive losses. CIR perturbs the output features by randomly moving them towards the average embeddings of the negative classes. To the best of our knowledge, CIR is the first regularization technique to act on the output features. In experimental evaluation, the combination of CIR and a plain Siamese-net with triplet loss yields best few-shot learning performance on the challenging tieredImageNet. CIR also improves the state-of-the-art technique in person re-identification on the Market-1501 dataset, based on triplet loss, and the state-of-the-art technique in person search on the CUHK-SYSU dataset, based on a cross-entropy loss. Finally, on the task of classification CIR performs on par with the popular label smoothing, as demonstrated for CIFAR-10 and -100.
Joint Detection and Tracking in Videos with Identification Features
May 25, 2020
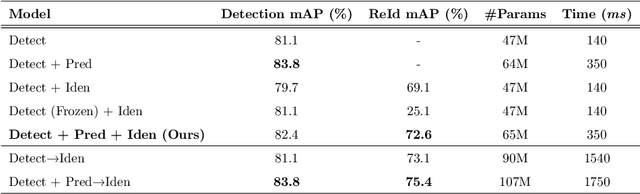
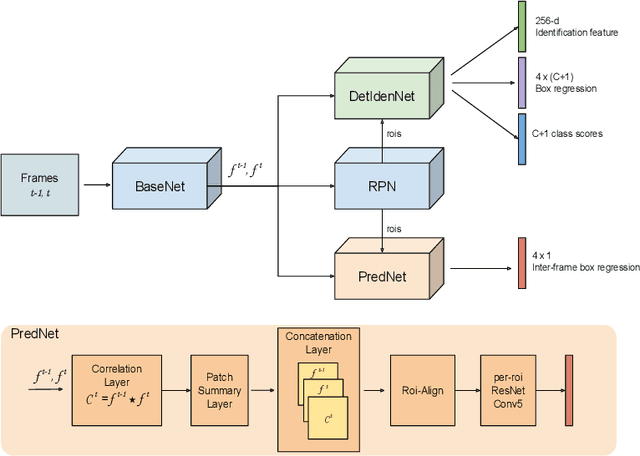
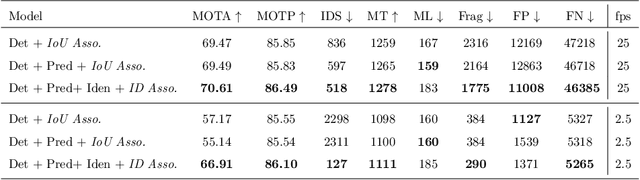
Recent works have shown that combining object detection and tracking tasks, in the case of video data, results in higher performance for both tasks, but they require a high frame-rate as a strict requirement for performance. This is assumption is often violated in real-world applications, when models run on embedded devices, often at only a few frames per second. Videos at low frame-rate suffer from large object displacements. Here re-identification features may support to match large-displaced object detections, but current joint detection and re-identification formulations degrade the detector performance, as these two are contrasting tasks. In the real-world application having separate detector and re-id models is often not feasible, as both the memory and runtime effectively double. Towards robust long-term tracking applicable to reduced-computational-power devices, we propose the first joint optimization of detection, tracking and re-identification features for videos. Notably, our joint optimization maintains the detector performance, a typical multi-task challenge. At inference time, we leverage detections for tracking (tracking-by-detection) when the objects are visible, detectable and slowly moving in the image. We leverage instead re-identification features to match objects which disappeared (e.g. due to occlusion) for several frames or were not tracked due to fast motion (or low-frame-rate videos). Our proposed method reaches the state-of-the-art on MOT, it ranks 1st in the UA-DETRAC'18 tracking challenge among online trackers, and 3rd overall.
Knowledge Distillation for End-to-End Person Search
Sep 05, 2019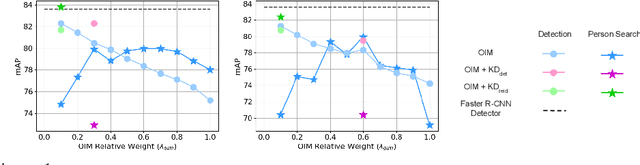
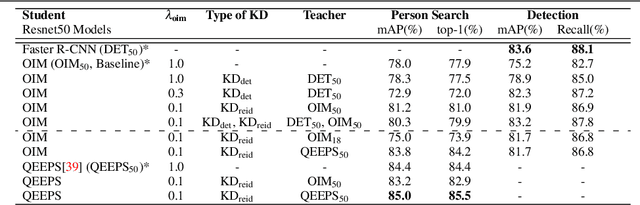
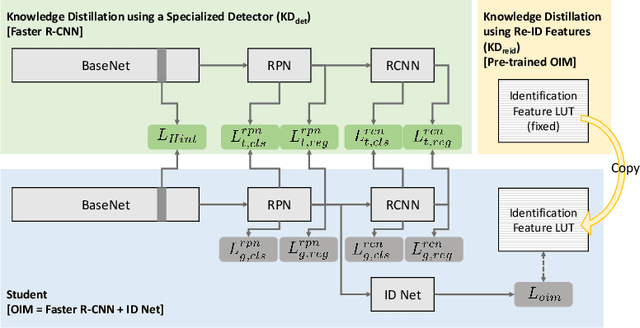

We introduce knowledge distillation for end-to-end person search. End-to-End methods are the current state-of-the-art for person search that solve both detection and re-identification jointly. These approaches for joint optimization show their largest drop in performance due to a sub-optimal detector. We propose two distinct approaches for extra supervision of end-to-end person search methods in a teacher-student setting. The first is adopted from state-of-the-art knowledge distillation in object detection. We employ this to supervise the detector of our person search model at various levels using a specialized detector. The second approach is new, simple and yet considerably more effective. This distills knowledge from a teacher re-identification technique via a pre-computed look-up table of ID features. It relaxes the learning of identification features and allows the student to focus on the detection task. This procedure not only helps fixing the sub-optimal detector training in the joint optimization and simultaneously improving the person search, but also closes the performance gap between the teacher and the student for model compression in this case. Overall, we demonstrate significant improvements for two recent state-of-the-art methods using our proposed knowledge distillation approach on two benchmark datasets. Moreover, on the model compression task our approach brings the performance of smaller models on par with the larger models.
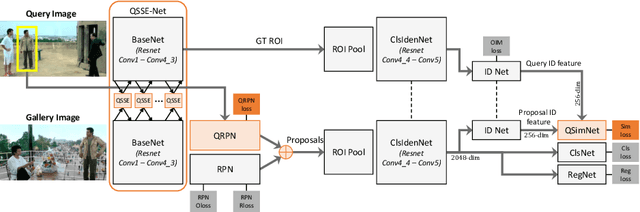
Query-guided End-to-End Person Search
May 03, 2019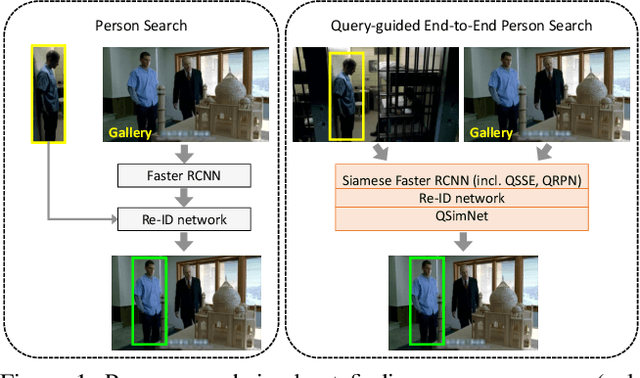
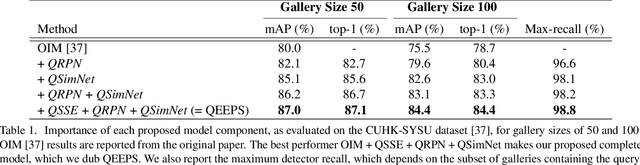
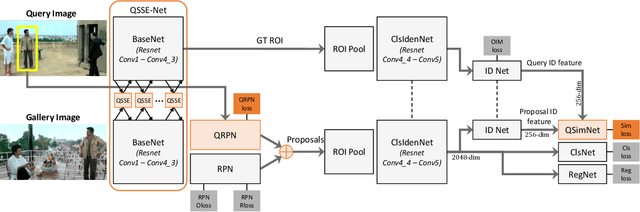
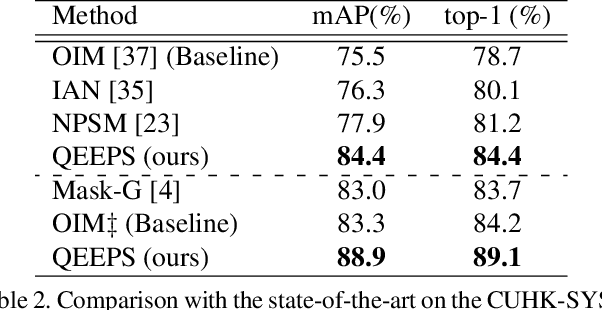
Person search has recently gained attention as the novel task of finding a person, provided as a cropped sample, from a gallery of non-cropped images, whereby several other people are also visible. We believe that i. person detection and re-identification should be pursued in a joint optimization framework and that ii. the person search should leverage the query image extensively (e.g. emphasizing unique query patterns). However, so far, no prior art realizes this. We introduce a novel query-guided end-to-end person search network (QEEPS) to address both aspects. We leverage a most recent joint detector and re-identification work, OIM [37]. We extend this with i. a query-guided Siamese squeeze-and-excitation network (QSSE-Net) that uses global context from both the query and gallery images, ii. a query-guided region proposal network (QRPN) to produce query-relevant proposals, and iii. a query-guided similarity subnetwork (QSimNet), to learn a query-guided reidentification score. QEEPS is the first end-to-end query-guided detection and re-id network. On both the most recent CUHK-SYSU [37] and PRW [46] datasets, we outperform the previous state-of-the-art by a large margin.