 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysTalk: Language-driven Real-time Physics in 3D Gaussian Scenes
Dec 31, 2025Realistic visual simulations are omnipresent, yet their creation requires computing time, rendering, and expert animation knowledge. Open-vocabulary visual effects generation from text inputs emerges as a promising solution that can unlock immense creative potential. However, current pipelines lack both physical realism and effective language interfaces, requiring slow offline optimization. In contrast, PhysTalk takes a 3D Gaussian Splatting (3DGS) scene as input and translates arbitrary user prompts into real time, physics based, interactive 4D animations. A large language model (LLM) generates executable code that directly modifies 3DGS parameters through lightweight proxies and particle dynamics. Notably, PhysTalk is the first framework to couple 3DGS directly with a physics simulator without relying on time consuming mesh extraction. While remaining open vocabulary, this design enables interactive 3D Gaussian animation via collision aware, physics based manipulation of arbitrary, multi material objects. Finally, PhysTalk is train-free and computationally lightweight: this makes 4D animation broadly accessible and shifts these workflows from a "render and wait" paradigm toward an interactive dialogue with a modern, physics-informed pipeline.
ANTHROPOS-V: benchmarking the novel task of Crowd Volume Estimation
Jan 03, 2025



We introduce the novel task of Crowd Volume Estimation (CVE), defined as the process of estimating the collective body volume of crowds using only RGB images. Besides event management and public safety, CVE can be instrumental in approximating body weight, unlocking weight sensitive applications such as infrastructure stress assessment, and assuring even weight balance. We propose the first benchmark for CVE, comprising ANTHROPOS-V, a synthetic photorealistic video dataset featuring crowds in diverse urban environments. Its annotations include each person's volume, SMPL shape parameters, and keypoints. Also, we explore metrics pertinent to CVE, define baseline models adapted from Human Mesh Recovery and Crowd Counting domains, and propose a CVE specific methodology that surpasses baselines. Although synthetic, the weights and heights of individuals are aligned with the real-world population distribution across genders, and they transfer to the downstream task of CVE from real images. Benchmark and code are available at github.com/colloroneluca/Crowd-Volume-Estimation.
MoDiPO: text-to-motion alignment via AI-feedback-driven Direct Preference Optimization
May 06, 2024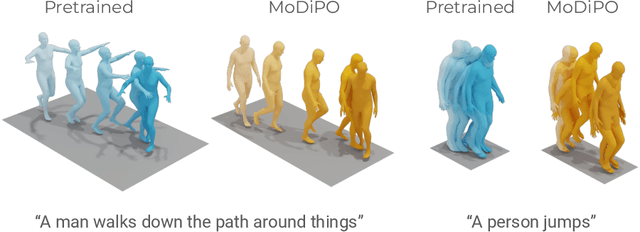
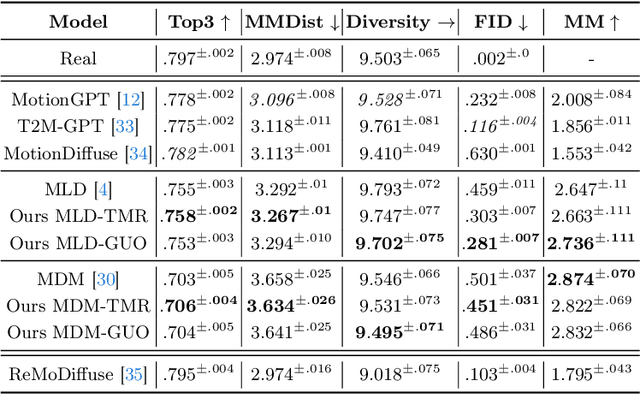
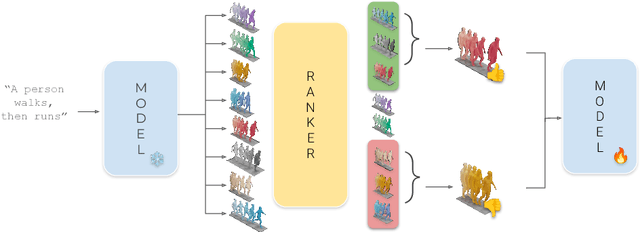
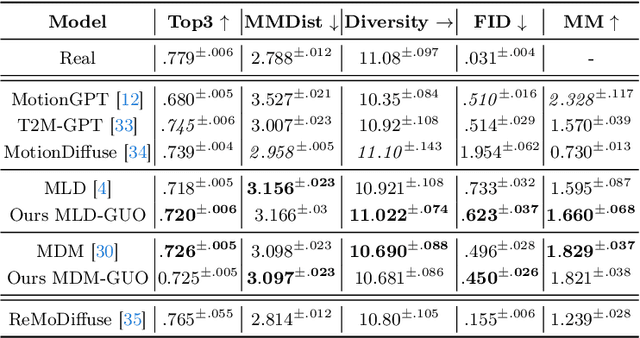
Diffusion Models have revolutionized the field of human motion generation by offering exceptional generation quality and fine-grained controllability through natural language conditioning. Their inherent stochasticity, that is the ability to generate various outputs from a single input, is key to their success. However, this diversity should not be unrestricted, as it may lead to unlikely generations. Instead, it should be confined within the boundaries of text-aligned and realistic generations. To address this issue, we propose MoDiPO (Motion Diffusion DPO), a novel methodology that leverages Direct Preference Optimization (DPO) to align text-to-motion models. We streamline the laborious and expensive process of gathering human preferences needed in DPO by leveraging AI feedback instead. This enables us to experiment with novel DPO strategies, using both online and offline generated motion-preference pairs. To foster future research we contribute with a motion-preference dataset which we dub Pick-a-Move. We demonstrate, both qualitatively and quantitatively, that our proposed method yields significantly more realistic motions. In particular, MoDiPO substantially improves Frechet Inception Distance (FID) while retaining the same RPrecision and Multi-Modality performances.
Multimodal Motion Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
Jul 14, 2023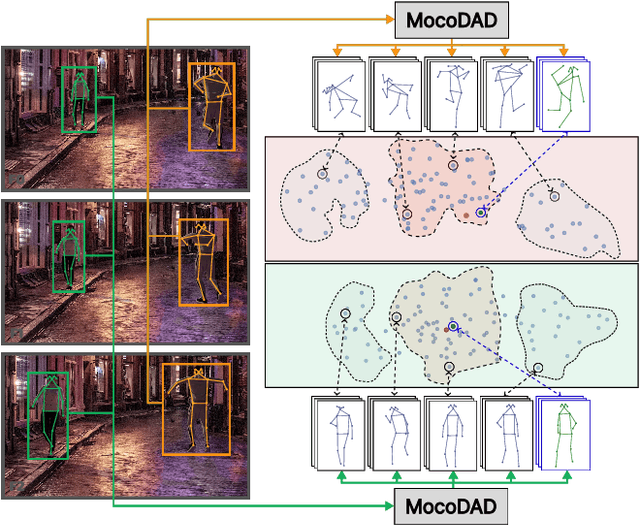
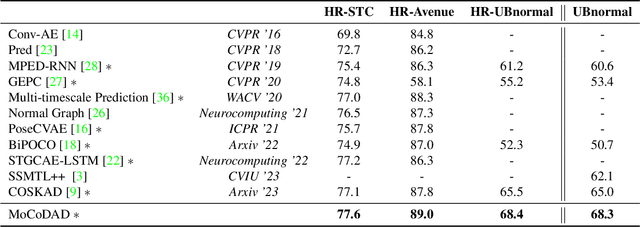
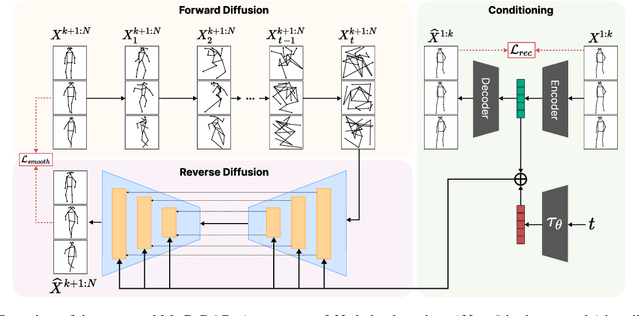
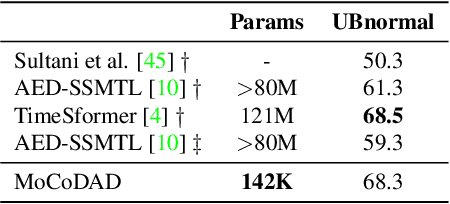
Anomalies are rare and anomaly detection is often therefore framed as One-Class Classification (OCC), i.e. trained solely on normalcy. Leading OCC techniques constrain the latent representations of normal motions to limited volumes and detect as abnormal anything outside, which accounts satisfactorily for the openset'ness of anomalies. But normalcy shares the same openset'ness property, since humans can perform the same action in several ways, which the leading techniques neglect. We propose a novel generative model for video anomaly detection (VAD), which assumes that both normality and abnormality are multimodal. We consider skeletal representations and leverage state-of-the-art diffusion probabilistic models to generate multimodal future human poses. We contribute a novel conditioning on the past motion of people, and exploit the improved mode coverage capabilities of diffusion processes to generate different-but-plausible future motions. Upon the statistical aggregation of future modes, anomaly is detected when the generated set of motions is not pertinent to the actual future. We validate our model on 4 established benchmarks: UBnormal, HR-UBnormal, HR-STC, and HR-Avenue, with extensive experiments surpassing state-of-the-art results.