 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANTHROPOS-V: benchmarking the novel task of Crowd Volume Estimation
Jan 03, 2025



We introduce the novel task of Crowd Volume Estimation (CVE), defined as the process of estimating the collective body volume of crowds using only RGB images. Besides event management and public safety, CVE can be instrumental in approximating body weight, unlocking weight sensitive applications such as infrastructure stress assessment, and assuring even weight balance. We propose the first benchmark for CVE, comprising ANTHROPOS-V, a synthetic photorealistic video dataset featuring crowds in diverse urban environments. Its annotations include each person's volume, SMPL shape parameters, and keypoints. Also, we explore metrics pertinent to CVE, define baseline models adapted from Human Mesh Recovery and Crowd Counting domains, and propose a CVE specific methodology that surpasses baselines. Although synthetic, the weights and heights of individuals are aligned with the real-world population distribution across genders, and they transfer to the downstream task of CVE from real images. Benchmark and code are available at github.com/colloroneluca/Crowd-Volume-Estimation.
MoDiPO: text-to-motion alignment via AI-feedback-driven Direct Preference Optimization
May 06, 2024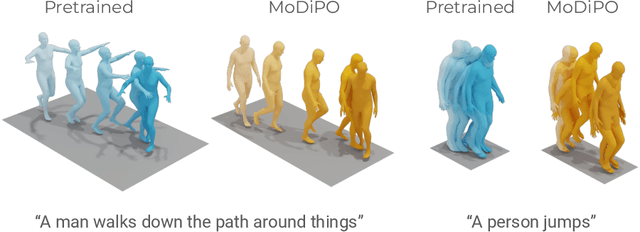
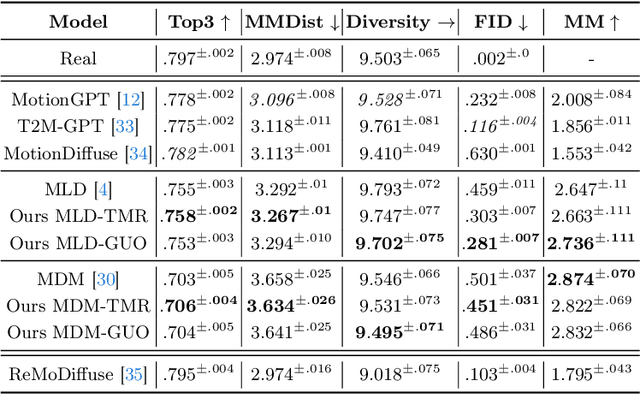
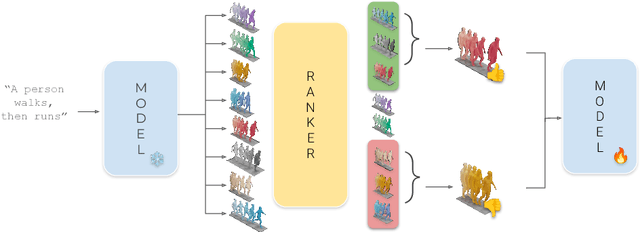
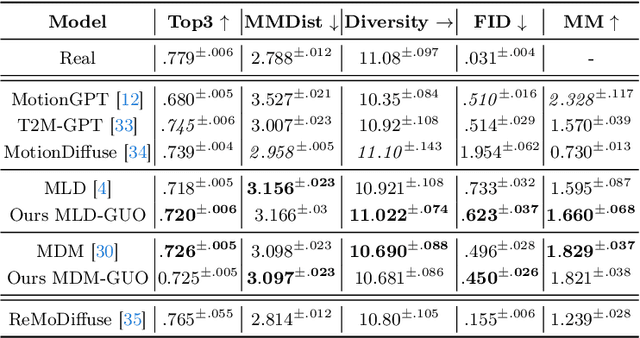
Diffusion Models have revolutionized the field of human motion generation by offering exceptional generation quality and fine-grained controllability through natural language conditioning. Their inherent stochasticity, that is the ability to generate various outputs from a single input, is key to their success. However, this diversity should not be unrestricted, as it may lead to unlikely generations. Instead, it should be confined within the boundaries of text-aligned and realistic generations. To address this issue, we propose MoDiPO (Motion Diffusion DPO), a novel methodology that leverages Direct Preference Optimization (DPO) to align text-to-motion models. We streamline the laborious and expensive process of gathering human preferences needed in DPO by leveraging AI feedback instead. This enables us to experiment with novel DPO strategies, using both online and offline generated motion-preference pairs. To foster future research we contribute with a motion-preference dataset which we dub Pick-a-Move. We demonstrate, both qualitatively and quantitatively, that our proposed method yields significantly more realistic motions. In particular, MoDiPO substantially improves Frechet Inception Distance (FID) while retaining the same RPrecision and Multi-Modality performances.