 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysTalk: Language-driven Real-time Physics in 3D Gaussian Scenes
Dec 31, 2025Realistic visual simulations are omnipresent, yet their creation requires computing time, rendering, and expert animation knowledge. Open-vocabulary visual effects generation from text inputs emerges as a promising solution that can unlock immense creative potential. However, current pipelines lack both physical realism and effective language interfaces, requiring slow offline optimization. In contrast, PhysTalk takes a 3D Gaussian Splatting (3DGS) scene as input and translates arbitrary user prompts into real time, physics based, interactive 4D animations. A large language model (LLM) generates executable code that directly modifies 3DGS parameters through lightweight proxies and particle dynamics. Notably, PhysTalk is the first framework to couple 3DGS directly with a physics simulator without relying on time consuming mesh extraction. While remaining open vocabulary, this design enables interactive 3D Gaussian animation via collision aware, physics based manipulation of arbitrary, multi material objects. Finally, PhysTalk is train-free and computationally lightweight: this makes 4D animation broadly accessible and shifts these workflows from a "render and wait" paradigm toward an interactive dialogue with a modern, physics-informed pipeline.
Video Unlearning via Low-Rank Refusal Vector
Jun 09, 2025
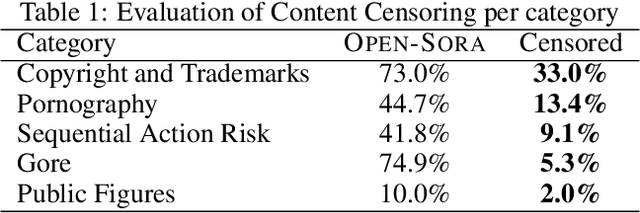
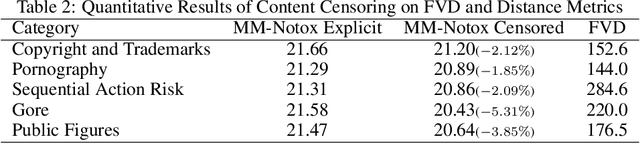

Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the biases and harmful concepts embedded within their web-scale training data. This inheritance creates a significant risk, as users can readily generate undesirable and even illegal content. This work introduces the first unlearning technique tailored explicitly for video diffusion models to address this critical issue. Our method requires 5 multi-modal prompt pairs only. Each pair contains a "safe" and an "unsafe" example that differ only by the target concept. Averaging their per-layer latent differences produces a "refusal vector", which, once subtracted from the model parameters, neutralizes the unsafe concept. We introduce a novel low-rank factorization approach on the covariance difference of embeddings that yields robust refusal vectors. This isolates the target concept while minimizing collateral unlearning of other semantics, thus preserving the visual quality of the generated video. Our method preserves the model's generation quality while operating without retraining or access to the original training data. By embedding the refusal direction directly into the model's weights, the suppression mechanism becomes inherently more robust against adversarial bypass attempts compared to surface-level input-output filters. In a thorough qualitative and quantitative evaluation, we show that we can neutralize a variety of harmful contents, including explicit nudity, graphic violence, copyrights, and trademarks. Project page: https://www.pinlab.org/video-unlearning.
Human Motion Unlearning
Mar 24, 2025We introduce the task of human motion unlearning to prevent the synthesis of toxic animations while preserving the general text-to-motion generative performance. Unlearning toxic motions is challenging as those can be generated from explicit text prompts and from implicit toxic combinations of safe motions (e.g., ``kicking" is ``loading and swinging a leg"). We propose the first motion unlearning benchmark by filtering toxic motions from the large and recent text-to-motion datasets of HumanML3D and Motion-X. We propose baselines, by adapting state-of-the-art image unlearning techniques to process spatio-temporal signals. Finally, we propose a novel motion unlearning model based on Latent Code Replacement, which we dub LCR. LCR is training-free and suitable to the discrete latent spaces of state-of-the-art text-to-motion diffusion models. LCR is simple and consistently outperforms baselines qualitatively and quantitatively. Project page: \href{https://www.pinlab.org/hmu}{https://www.pinlab.org/hmu}.
Social EgoMesh Estimation
Nov 07, 2024
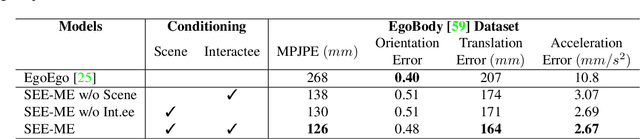
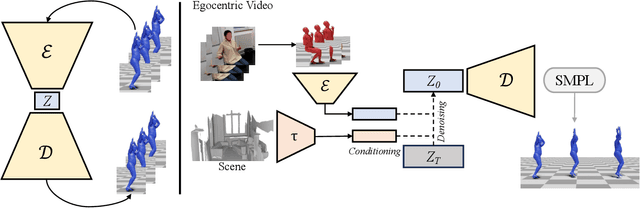
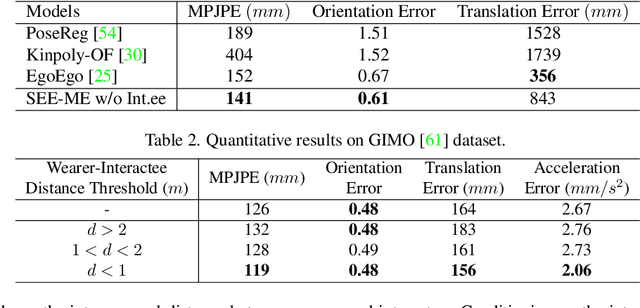
Accurately estimating the 3D pose of the camera wearer in egocentric video sequences is crucial to modeling human behavior in virtual and augmented reality applications. The task presents unique challenges due to the limited visibility of the user's body caused by the front-facing camera mounted on their head. Recent research has explored the utilization of the scene and ego-motion, but it has overlooked humans' interactive nature. We propose a novel framework for Social Egocentric Estimation of body MEshes (SEE-ME). Our approach is the first to estimate the wearer's mesh using only a latent probabilistic diffusion model, which we condition on the scene and, for the first time, on the social wearer-interactee interactions. Our in-depth study sheds light on when social interaction matters most for ego-mesh estimation; it quantifies the impact of interpersonal distance and gaze direction. Overall, SEE-ME surpasses the current best technique, reducing the pose estimation error (MPJPE) by 53%. The code is available at https://github.com/L-Scofano/SEEME.
OVOSE: Open-Vocabulary Semantic Segmentation in Event-Based Cameras
Aug 18, 2024



Event cameras, known for low-latency operation and superior performance in challenging lighting conditions, are suitable for sensitive computer vision tasks such as semantic segmentation in autonomous driving. However, challenges arise due to limited event-based data and the absence of large-scale segmentation benchmarks. Current works are confined to closed-set semantic segmentation, limiting their adaptability to other applications. In this paper, we introduce OVOSE, the first Open-Vocabulary Semantic Segmentation algorithm for Event cameras. OVOSE leverages synthetic event data and knowledge distillation from a pre-trained image-based foundation model to an event-based counterpart, effectively preserving spatial context and transferring open-vocabulary semantic segmentation capabilities. We evaluate the performance of OVOSE on two driving semantic segmentation datasets DDD17, and DSEC-Semantic, comparing it with existing conventional image open-vocabulary models adapted for event-based data. Similarly, we compare OVOSE with state-of-the-art methods designed for closed-set settings in unsupervised domain adaptation for event-based semantic segmentation. OVOSE demonstrates superior performance, showcasing its potential for real-world applications. The code is available at https://github.com/ram95d/OVOSE.
Length-Aware Motion Synthesis via Latent Diffusion
Jul 16, 2024The target duration of a synthesized human motion is a critical attribute that requires modeling control over the motion dynamics and style. Speeding up an action performance is not merely fast-forwarding it. However, state-of-the-art techniques for human behavior synthesis have limited control over the target sequence length. We introduce the problem of generating length-aware 3D human motion sequences from textual descriptors, and we propose a novel model to synthesize motions of variable target lengths, which we dub "Length-Aware Latent Diffusion" (LADiff). LADiff consists of two new modules: 1) a length-aware variational auto-encoder to learn motion representations with length-dependent latent codes; 2) a length-conforming latent diffusion model to generate motions with a richness of details that increases with the required target sequence length. LADiff significantly improves over the state-of-the-art across most of the existing motion synthesis metrics on the two established benchmarks of HumanML3D and KIT-ML.
MoDiPO: text-to-motion alignment via AI-feedback-driven Direct Preference Optimization
May 06, 2024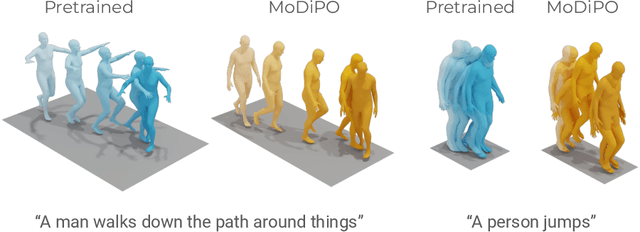
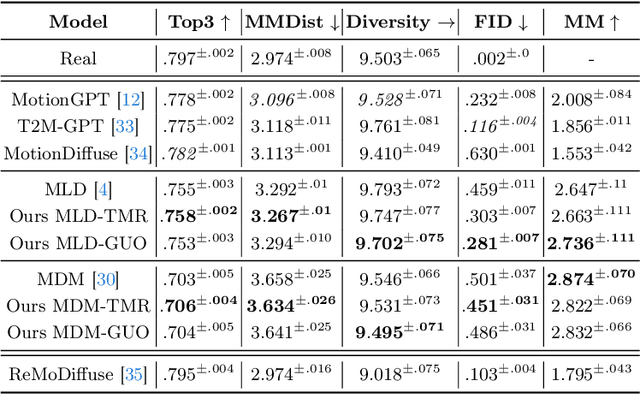
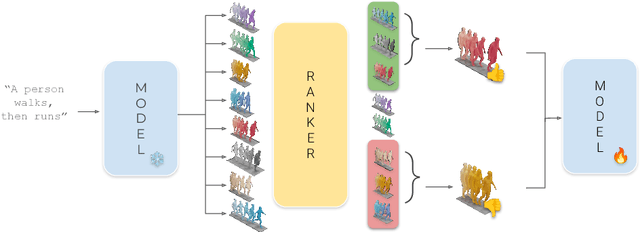
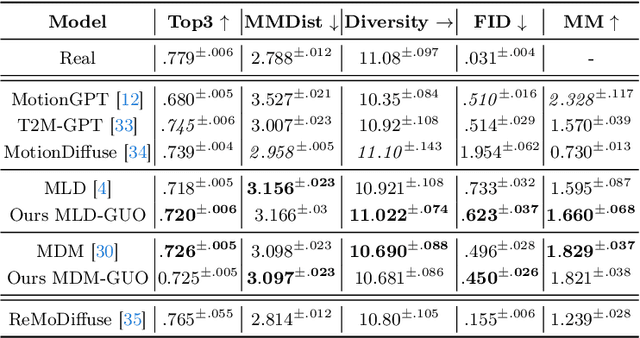
Diffusion Models have revolutionized the field of human motion generation by offering exceptional generation quality and fine-grained controllability through natural language conditioning. Their inherent stochasticity, that is the ability to generate various outputs from a single input, is key to their success. However, this diversity should not be unrestricted, as it may lead to unlikely generations. Instead, it should be confined within the boundaries of text-aligned and realistic generations. To address this issue, we propose MoDiPO (Motion Diffusion DPO), a novel methodology that leverages Direct Preference Optimization (DPO) to align text-to-motion models. We streamline the laborious and expensive process of gathering human preferences needed in DPO by leveraging AI feedback instead. This enables us to experiment with novel DPO strategies, using both online and offline generated motion-preference pairs. To foster future research we contribute with a motion-preference dataset which we dub Pick-a-Move. We demonstrate, both qualitatively and quantitatively, that our proposed method yields significantly more realistic motions. In particular, MoDiPO substantially improves Frechet Inception Distance (FID) while retaining the same RPrecision and Multi-Modality performances.
Following the Human Thread in Social Navigation
Apr 17, 2024


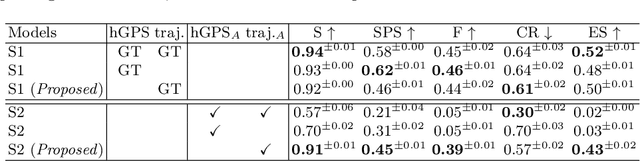
The success of collaboration between humans and robots in shared environments relies on the robot's real-time adaptation to human motion. Specifically, in Social Navigation, the agent should be close enough to assist but ready to back up to let the human move freely, avoiding collisions. Human trajectories emerge as crucial cues in Social Navigation, but they are partially observable from the robot's egocentric view and computationally complex to process. We propose the first Social Dynamics Adaptation model (SDA) based on the robot's state-action history to infer the social dynamics. We propose a two-stage Reinforcement Learning framework: the first learns to encode the human trajectories into social dynamics and learns a motion policy conditioned on this encoded information, the current status, and the previous action. Here, the trajectories are fully visible, i.e., assumed as privileged information. In the second stage, the trained policy operates without direct access to trajectories. Instead, the model infers the social dynamics solely from the history of previous actions and statuses in real-time. Tested on the novel Habitat 3.0 platform, SDA sets a novel state of the art (SoA) performance in finding and following humans.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024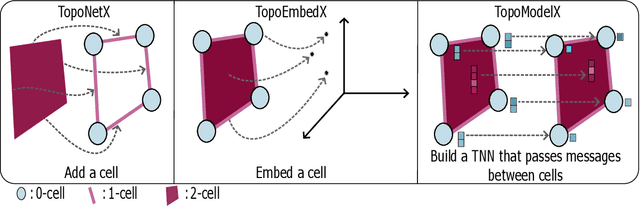
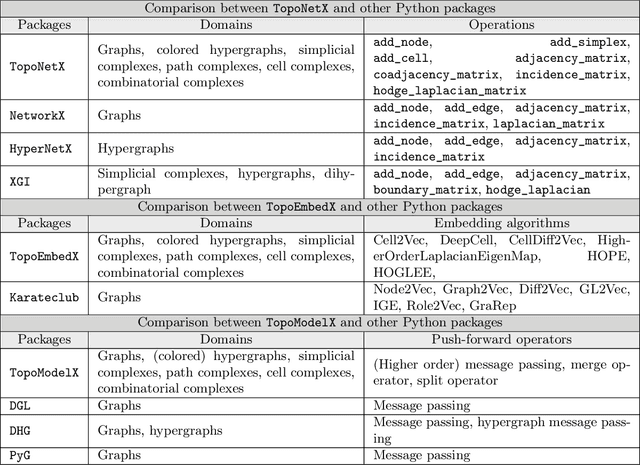
We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.
Adaptive Point Transformer
Jan 26, 2024The recent surge in 3D data acquisition has spurred the development of geometric deep learning models for point cloud processing, boosted by the remarkable success of transformers in natural language processing. While point cloud transformers (PTs) have achieved impressive results recently, their quadratic scaling with respect to the point cloud size poses a significant scalability challenge for real-world applications. To address this issue, we propose the Adaptive Point Cloud Transformer (AdaPT), a standard PT model augmented by an adaptive token selection mechanism. AdaPT dynamically reduces the number of tokens during inference, enabling efficient processing of large point clouds. Furthermore, we introduce a budget mechanism to flexibly adjust the computational cost of the model at inference time without the need for retraining or fine-tuning separate models. Our extensive experimental evaluation on point cloud classification tasks demonstrates that AdaPT significantly reduces computational complexity while maintaining competitive accuracy compared to standard PTs. The code for AdaPT is made publicly available.