 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUTOKD: Automatic Knowledge Distillation Into A Student Architecture Family
Nov 05, 2021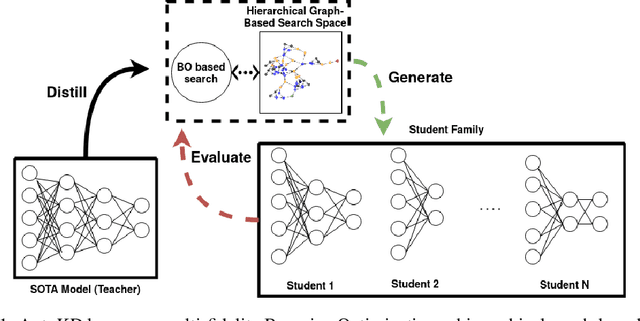

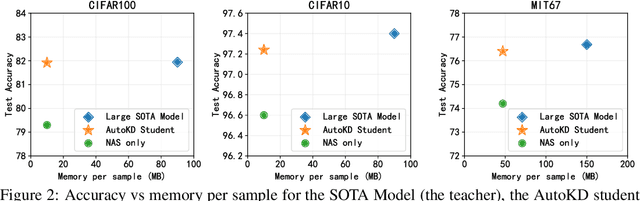
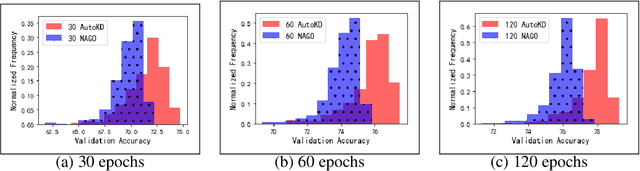
State-of-the-art results in deep learning have been improving steadily, in good part due to the use of larger models. However, widespread use is constrained by device hardware limitations, resulting in a substantial performance gap between state-of-the-art models and those that can be effectively deployed on small devices. While Knowledge Distillation (KD) theoretically enables small student models to emulate larger teacher models, in practice selecting a good student architecture requires considerable human expertise. Neural Architecture Search (NAS) appears as a natural solution to this problem but most approaches can be inefficient, as most of the computation is spent comparing architectures sampled from the same distribution, with negligible differences in performance. In this paper, we propose to instead search for a family of student architectures sharing the property of being good at learning from a given teacher. Our approach AutoKD, powered by Bayesian Optimization, explores a flexible graph-based search space, enabling us to automatically learn the optimal student architecture distribution and KD parameters, while being 20x more sample efficient compared to existing state-of-the-art. We evaluate our method on 3 datasets; on large images specifically, we reach the teacher performance while using 3x less memory and 10x less parameters. Finally, while AutoKD uses the traditional KD loss, it outperforms more advanced KD variants using hand-designed students.
OSOA: One-Shot Online Adaptation of Deep Generative Models for Lossless Compression
Nov 02, 2021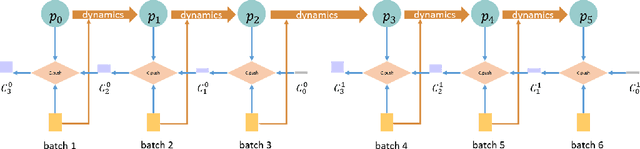

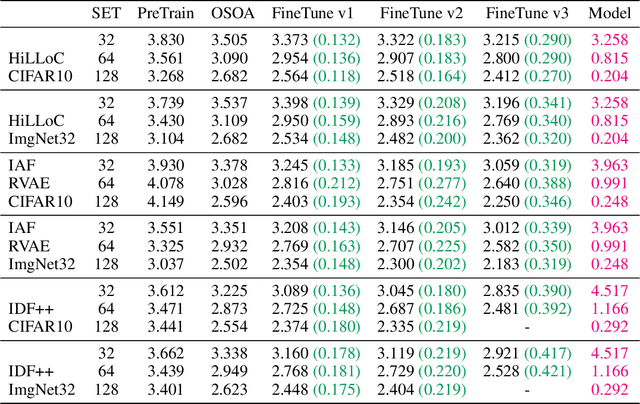
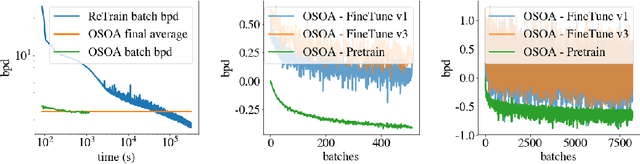
Explicit deep generative models (DGMs), e.g., VAEs and Normalizing Flows, have shown to offer an effective data modelling alternative for lossless compression. However, DGMs themselves normally require large storage space and thus contaminate the advantage brought by accurate data density estimation. To eliminate the requirement of saving separate models for different target datasets, we propose a novel setting that starts from a pretrained deep generative model and compresses the data batches while adapting the model with a dynamical system for only one epoch. We formalise this setting as that of One-Shot Online Adaptation (OSOA) of DGMs for lossless compression and propose a vanilla algorithm under this setting. Experimental results show that vanilla OSOA can save significant time versus training bespoke models and space versus using one model for all targets. With the same adaptation step number or adaptation time, it is shown vanilla OSOA can exhibit better space efficiency, e.g., $47\%$ less space, than fine-tuning the pretrained model and saving the fine-tuned model. Moreover, we showcase the potential of OSOA and motivate more sophisticated OSOA algorithms by showing further space or time efficiency with multiple updates per batch and early stopping.
Adversarial Branch Architecture Search for Unsupervised Domain Adaptation
Mar 04, 2021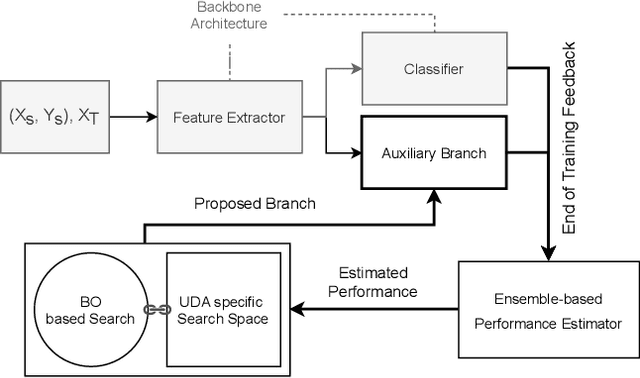
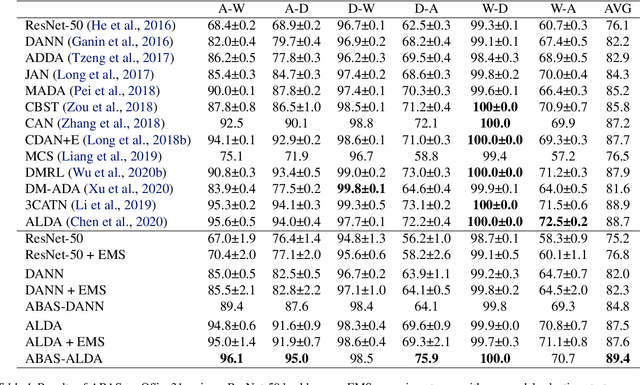
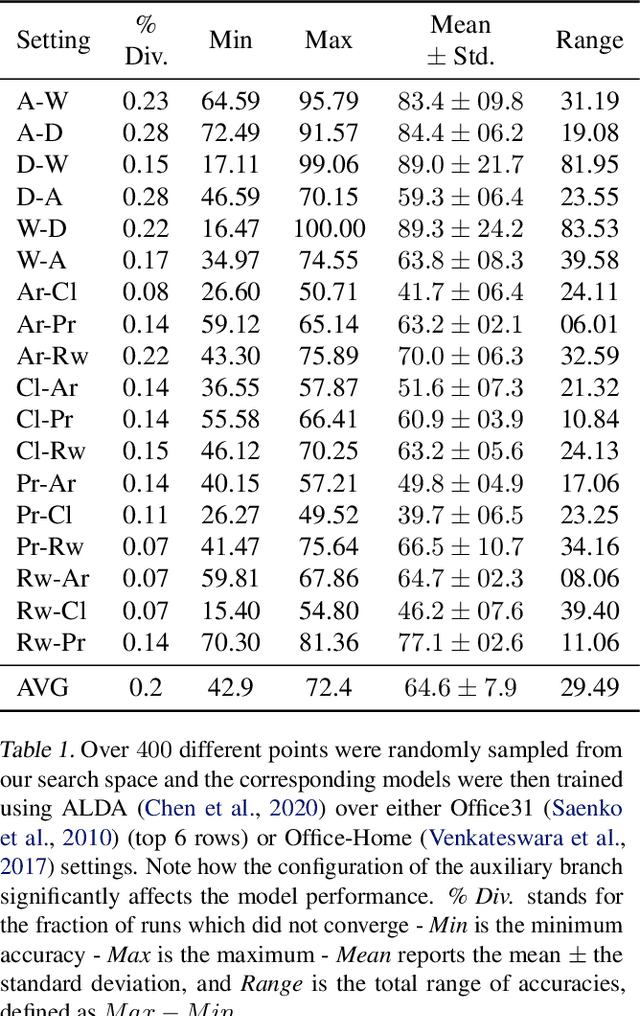
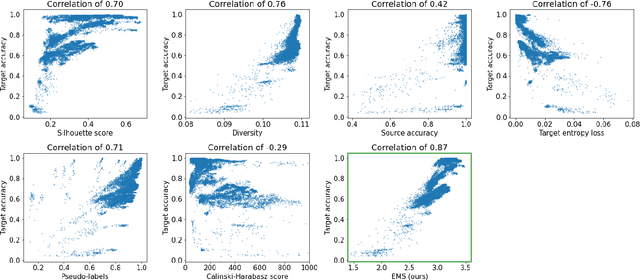
Unsupervised Domain Adaptation (UDA) is a key field in visual recognition, as it enables robust performances across different visual domains. In the deep learning era, the performance of UDA methods has been driven by better losses and by improved network architectures, specifically the addition of auxiliary domain-alignment branches to pre-trained backbones. However, all the neural architectures proposed so far are hand-crafted, which might hinder further progress. The current copious offspring of Neural Architecture Search (NAS) only alleviates hand-crafting so far, as it requires labels for model selection, which are not available in UDA, and is usually applied to the whole architecture, while using pre-trained models is a strict requirement for high performance. No prior work has addressed these aspects in the context of NAS for UDA. Here we propose an Adversarial Branch Architecture Search (ABAS) for UDA, to learn the auxiliary branch network from data without handcrafting. Our main contribution include i. a novel data-driven ensemble approach for model selection, to circumvent the lack of target labels, and ii. a pipeline to automatically search for the best performing auxiliary branch. To the best of our knowledge, ABAS is the first NAS method for UDA to comply with a pre-trained backbone, a strict requirement for high performance. ABAS outputs both the optimal auxiliary branch and its trained parameters. When applied to two modern UDA techniques, DANN and ALDA, it improves performance on three standard CV datasets (Office31, Office-Home and PACS). In all cases, ABAS robustly finds the branch architectures which yield best performances. Code will be released.
Self-Supervised Learning Across Domains
Jul 24, 2020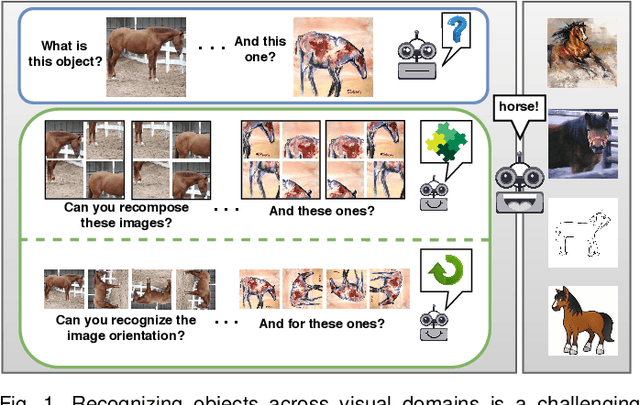
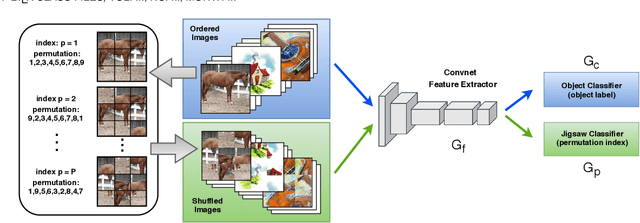
Human adaptability relies crucially on learning and merging knowledge from both supervised and unsupervised tasks: the parents point out few important concepts, but then the children fill in the gaps on their own. This is particularly effective, because supervised learning can never be exhaustive and thus learning autonomously allows to discover invariances and regularities that help to generalize. In this paper we propose to apply a similar approach to the problem of object recognition across domains: our model learns the semantic labels in a supervised fashion, and broadens its understanding of the data by learning from self-supervised signals on the same images. This secondary task helps the network to learn the concepts like spatial orientation and part correlation, while acting as a regularizer for the classification task. Extensive experiments confirm our intuition and show that our multi-task method combining supervised and self-supervised knowledge shows competitive results with respect to more complex domain generalization and adaptation solutions. It also proves its potential in the novel and challenging predictive and partial domain adaptation scenarios.
MANAS: Multi-Agent Neural Architecture Search
Sep 05, 2019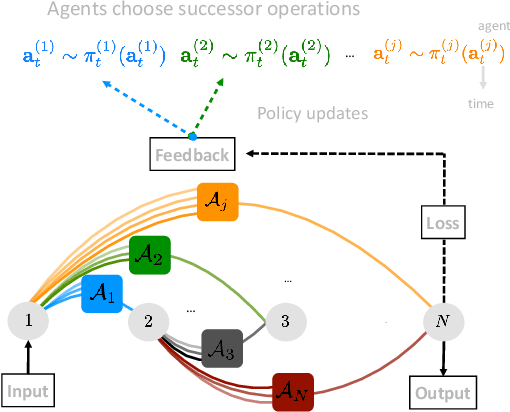
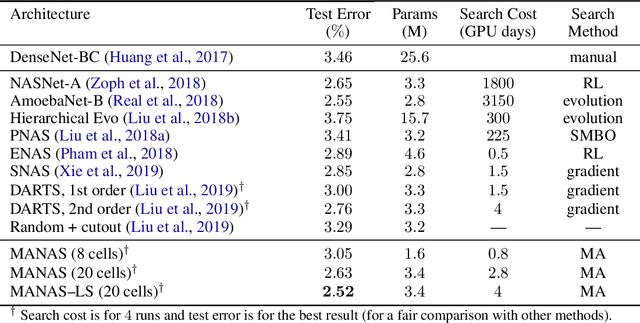
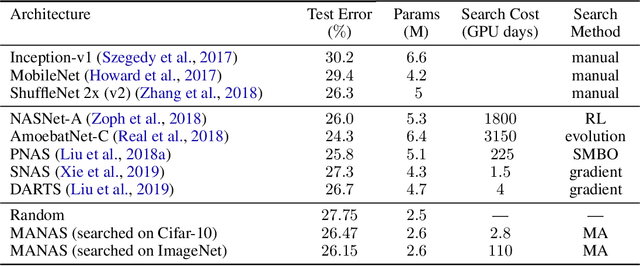
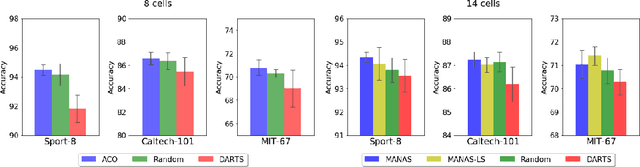
The Neural Architecture Search (NAS) problem is typically formulated as a graph search problem where the goal is to learn the optimal operations over edges in order to maximise a graph-level global objective. Due to the large architecture parameter space, efficiency is a key bottleneck preventing NAS from its practical use. In this paper, we address the issue by framing NAS as a multi-agent problem where agents control a subset of the network and coordinate to reach optimal architectures. We provide two distinct lightweight implementations, with reduced memory requirements (1/8th of state-of-the-art), and performances above those of much more computationally expensive methods. Theoretically, we demonstrate vanishing regrets of the form O(sqrt(T)), with T being the total number of rounds. Finally, aware that random search is an, often ignored, effective baseline we perform additional experiments on 3 alternative datasets and 2 network configurations, and achieve favourable results in comparison.
Domain Generalization by Solving Jigsaw Puzzles
Apr 14, 2019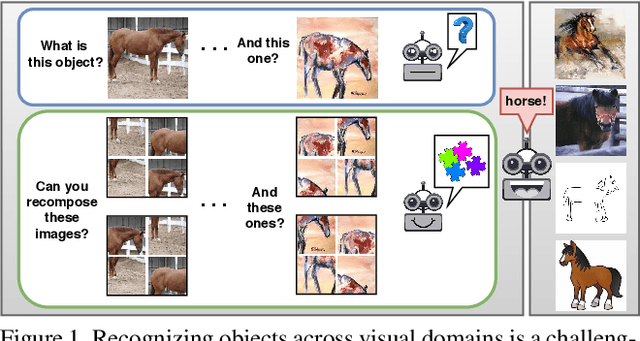
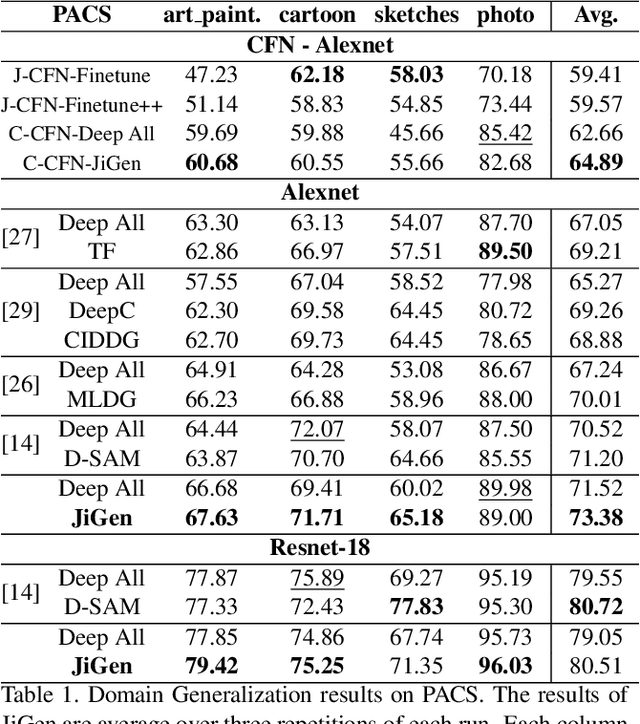
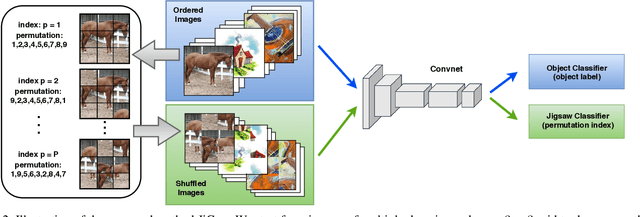
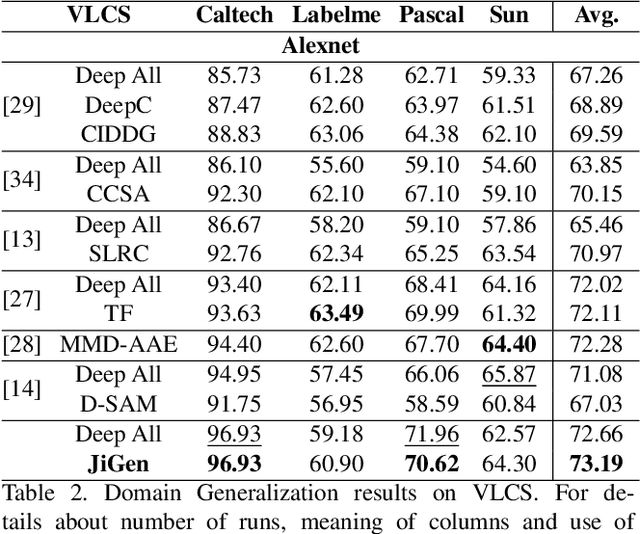
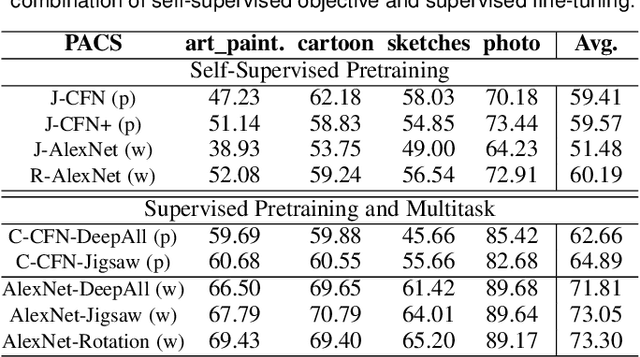
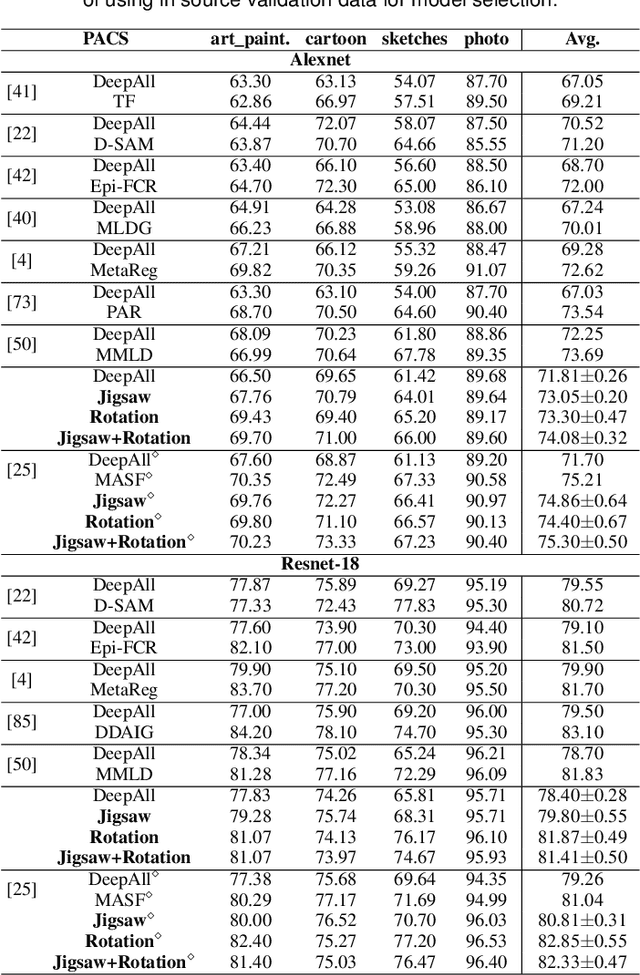
Human adaptability relies crucially on the ability to learn and merge knowledge both from supervised and unsupervised learning: the parents point out few important concepts, but then the children fill in the gaps on their own. This is particularly effective, because supervised learning can never be exhaustive and thus learning autonomously allows to discover invariances and regularities that help to generalize. In this paper we propose to apply a similar approach to the task of object recognition across domains: our model learns the semantic labels in a supervised fashion, and broadens its understanding of the data by learning from self-supervised signals how to solve a jigsaw puzzle on the same images. This secondary task helps the network to learn the concepts of spatial correlation while acting as a regularizer for the classification task. Multiple experiments on the PACS, VLCS, Office-Home and digits datasets confirm our intuition and show that this simple method outperforms previous domain generalization and adaptation solutions. An ablation study further illustrates the inner workings of our approach.
Learning to see across Domains and Modalities
Feb 13, 2019


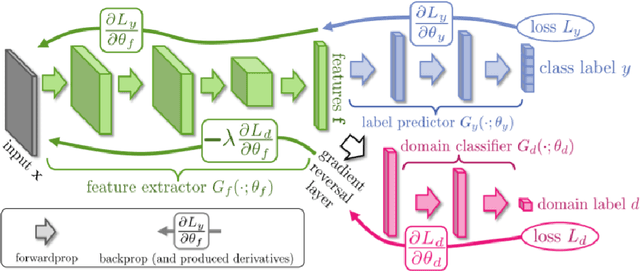
Deep learning has raised hopes and expectations as a general solution for many applications; indeed it has proven effective, but it also showed a strong dependence on large quantities of data. Luckily, it has been shown that, even when data is scarce, a successful model can be trained by reusing prior knowledge. Thus, developing techniques for transfer learning, in its broadest definition, is a crucial element towards the deployment of effective and accurate intelligent systems. This thesis will focus on a family of transfer learning methods applied to the task of visual object recognition, specifically image classification. Transfer learning is a general term, and specific settings have been given specific names: when the learner has only access to unlabeled data from the a target domain and labeled data from a different domain (the source), the problem is known as that of "unsupervised domain adaptation" (DA). The first part of this work will focus on three methods for this setting: one of these methods deals with features, one with images while the third one uses both. The second part will focus on the real life issues of robotic perception, specifically RGB-D recognition. Robotic platforms are usually not limited to color perception; very often they also carry a Depth camera. Unfortunately, the depth modality is rarely used for visual recognition due to the lack of pretrained models from which to transfer and little data to train one on from scratch. Two methods for dealing with this scenario will be presented: one using synthetic data and the other exploiting cross-modality transfer learning.
From source to target and back: symmetric bi-directional adaptive GAN
Nov 29, 2017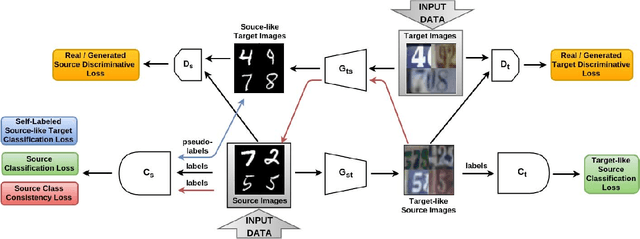
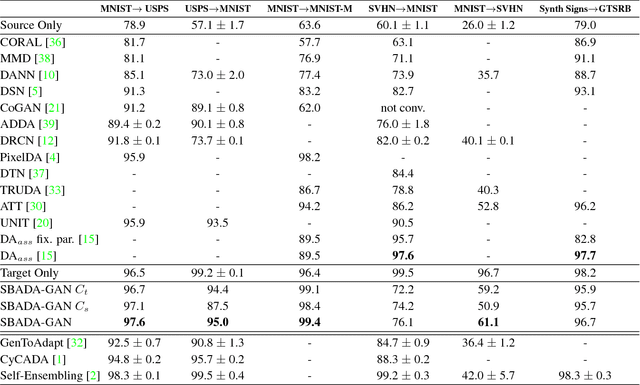
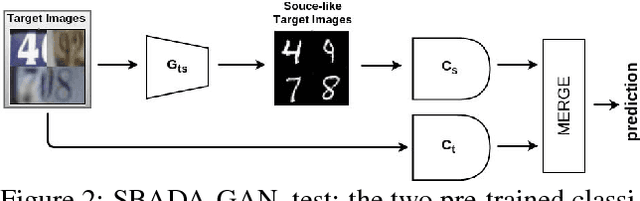
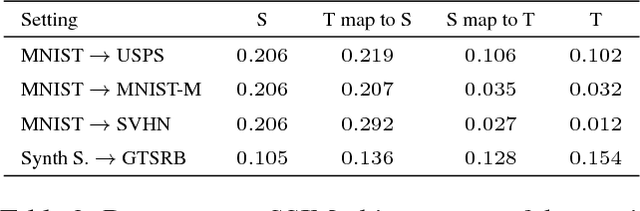
The effectiveness of generative adversarial approaches in producing images according to a specific style or visual domain has recently opened new directions to solve the unsupervised domain adaptation problem. It has been shown that source labeled images can be modified to mimic target samples making it possible to train directly a classifier in the target domain, despite the original lack of annotated data. Inverse mappings from the target to the source domain have also been evaluated but only passing through adapted feature spaces, thus without new image generation. In this paper we propose to better exploit the potential of generative adversarial networks for adaptation by introducing a novel symmetric mapping among domains. We jointly optimize bi-directional image transformations combining them with target self-labeling. Moreover we define a new class consistency loss that aligns the generators in the two directions imposing to conserve the class identity of an image passing through both domain mappings. A detailed qualitative and quantitative analysis of the reconstructed images confirm the power of our approach. By integrating the two domain specific classifiers obtained with our bi-directional network we exceed previous state-of-the-art unsupervised adaptation results on four different benchmark datasets.
AutoDIAL: Automatic DomaIn Alignment Layers
Nov 27, 2017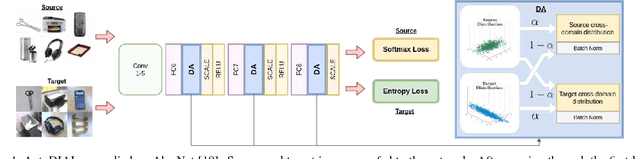
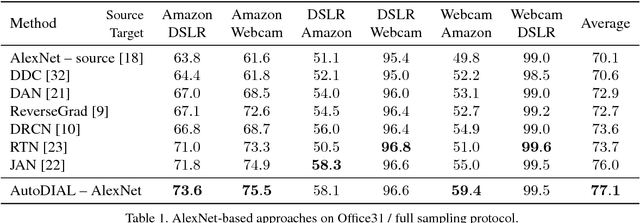
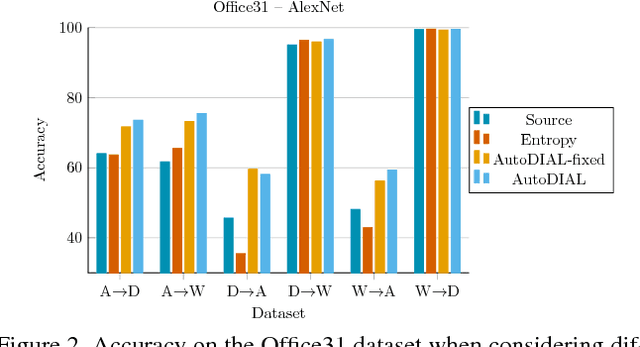
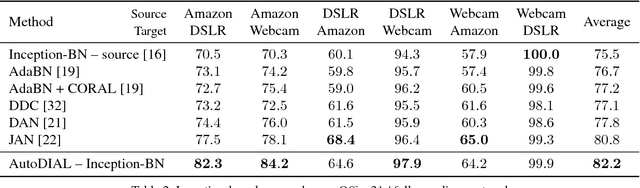
Classifiers trained on given databases perform poorly when tested on data acquired in different settings. This is explained in domain adaptation through a shift among distributions of the source and target domains. Attempts to align them have traditionally resulted in works reducing the domain shift by introducing appropriate loss terms, measuring the discrepancies between source and target distributions, in the objective function. Here we take a different route, proposing to align the learned representations by embedding in any given network specific Domain Alignment Layers, designed to match the source and target feature distributions to a reference one. Opposite to previous works which define a priori in which layers adaptation should be performed, our method is able to automatically learn the degree of feature alignment required at different levels of the deep network. Thorough experiments on different public benchmarks, in the unsupervised setting, confirm the power of our approach.
Bridging between Computer and Robot Vision through Data Augmentation: a Case Study on Object Recognition
May 05, 2017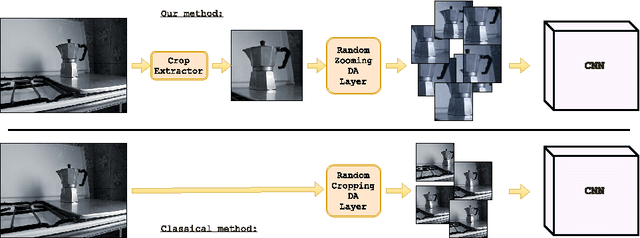
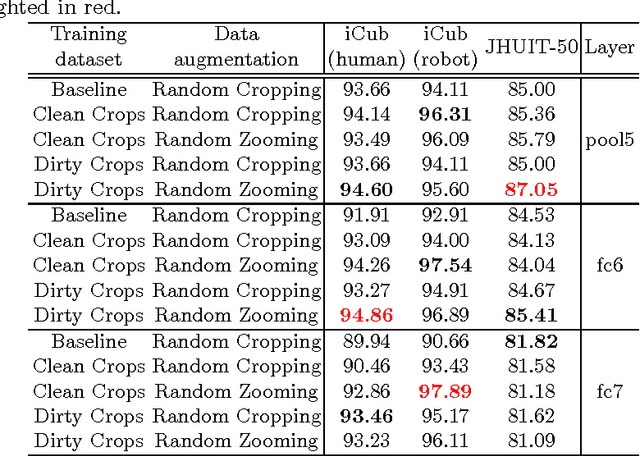

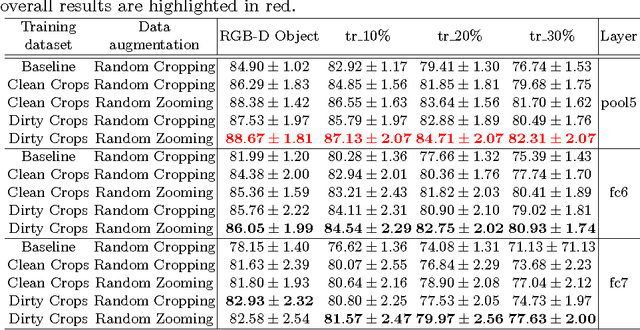
Despite the impressive progress brought by deep network in visual object recognition, robot vision is still far from being a solved problem. The most successful convolutional architectures are developed starting from ImageNet, a large scale collection of images of object categories downloaded from the Web. This kind of images is very different from the situated and embodied visual experience of robots deployed in unconstrained settings. To reduce the gap between these two visual experiences, this paper proposes a simple yet effective data augmentation layer that zooms on the object of interest and simulates the object detection outcome of a robot vision system. The layer, that can be used with any convolutional deep architecture, brings to an increase in object recognition performance of up to 7\%, in experiments performed over three different benchmark databases. Upon acceptance of the paper, our robot data augmentation layer will be made publicly available.