 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShedding Light on Depth: Explainability Assessment in Monocular Depth Estimation
Sep 19, 2025
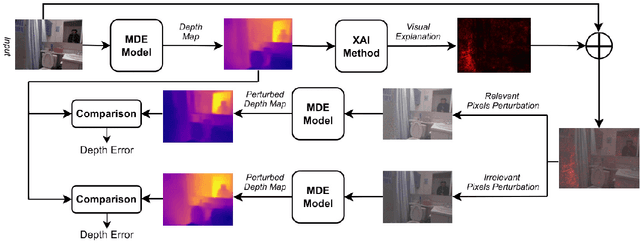

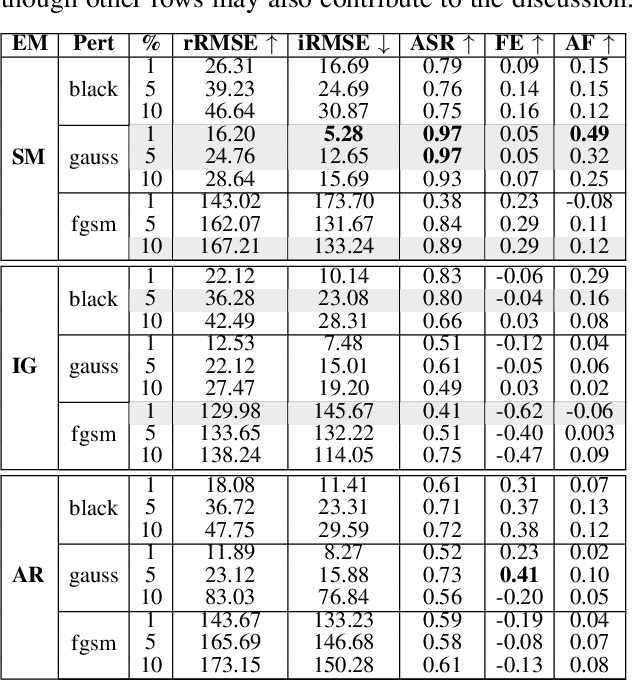
Explainable artificial intelligence is increasingly employed to understand the decision-making process of deep learning models and create trustworthiness in their adoption. However, the explainability of Monocular Depth Estimation (MDE) remains largely unexplored despite its wide deployment in real-world applications. In this work, we study how to analyze MDE networks to map the input image to the predicted depth map. More in detail, we investigate well-established feature attribution methods, Saliency Maps, Integrated Gradients, and Attention Rollout on different computationally complex models for MDE: METER, a lightweight network, and PixelFormer, a deep network. We assess the quality of the generated visual explanations by selectively perturbing the most relevant and irrelevant pixels, as identified by the explainability methods, and analyzing the impact of these perturbations on the model's output. Moreover, since existing evaluation metrics can have some limitations in measuring the validity of visual explanations for MDE, we additionally introduce the Attribution Fidelity. This metric evaluates the reliability of the feature attribution by assessing their consistency with the predicted depth map. Experimental results demonstrate that Saliency Maps and Integrated Gradients have good performance in highlighting the most important input features for MDE lightweight and deep models, respectively. Furthermore, we show that Attribution Fidelity effectively identifies whether an explainability method fails to produce reliable visual maps, even in scenarios where conventional metrics might suggest satisfactory results.
A survey on efficient vision transformers: algorithms, techniques, and performance benchmarking
Sep 05, 2023



Vision Transformer (ViT) architectures are becoming increasingly popular and widely employed to tackle computer vision applications. Their main feature is the capacity to extract global information through the self-attention mechanism, outperforming earlier convolutional neural networks. However, ViT deployment and performance have grown steadily with their size, number of trainable parameters, and operations. Furthermore, self-attention's computational and memory cost quadratically increases with the image resolution. Generally speaking, it is challenging to employ these architectures in real-world applications due to many hardware and environmental restrictions, such as processing and computational capabilities. Therefore, this survey investigates the most efficient methodologies to ensure sub-optimal estimation performances. More in detail, four efficient categories will be analyzed: compact architecture, pruning, knowledge distillation, and quantization strategies. Moreover, a new metric called Efficient Error Rate has been introduced in order to normalize and compare models' features that affect hardware devices at inference time, such as the number of parameters, bits, FLOPs, and model size. Summarizing, this paper firstly mathematically defines the strategies used to make Vision Transformer efficient, describes and discusses state-of-the-art methodologies, and analyzes their performances over different application scenarios. Toward the end of this paper, we also discuss open challenges and promising research directions.
DANAE: a denoising autoencoder for underwater attitude estimation
Nov 13, 2020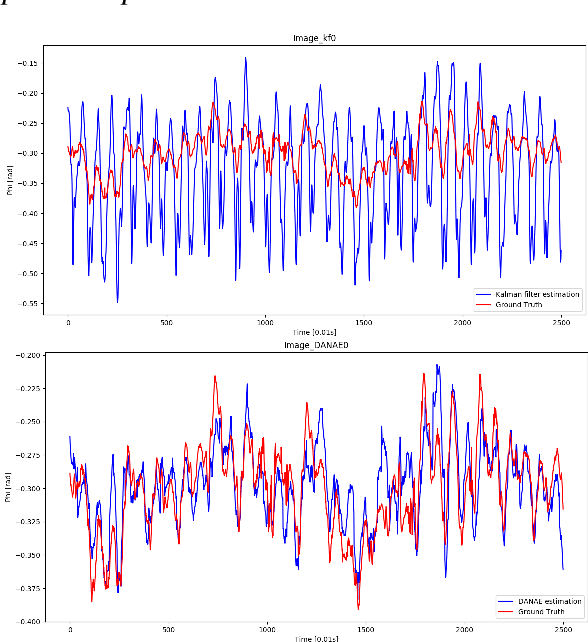
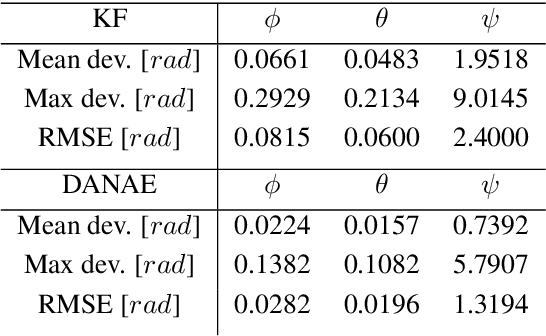

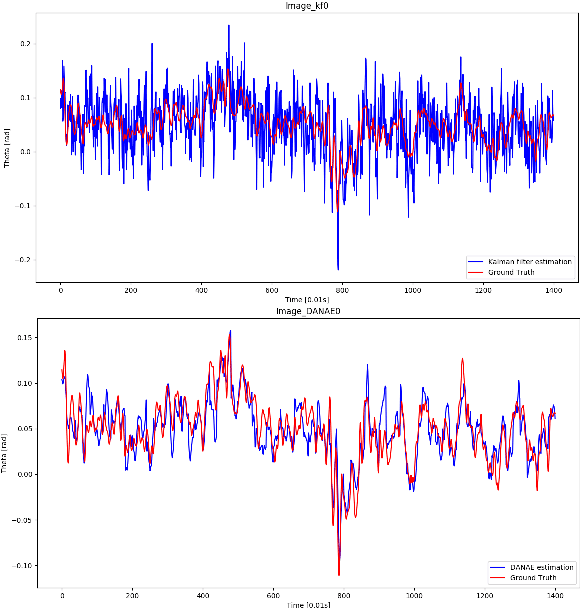
One of the main issues for underwater robots navigation is their accurate positioning, which heavily depends on the orientation estimation phase. The systems employed to this scope are affected by different noise typologies, mainly related to the sensors and to the irregular noise of the underwater environment. Filtering algorithms can reduce their effect if opportunely configured, but this process usually requires fine techniques and time. In this paper we propose DANAE, a deep Denoising AutoeNcoder for Attitude Estimation which works on Kalman filter IMU/AHRS data integration with the aim of reducing any kind of noise, independently of its nature. This deep learning-based architecture showed to be robust and reliable, significantly improving the Kalman filter results. Further tests could make this method suitable for real-time applications on navigation tasks.
Agnostic Domain Generalization
Aug 03, 2018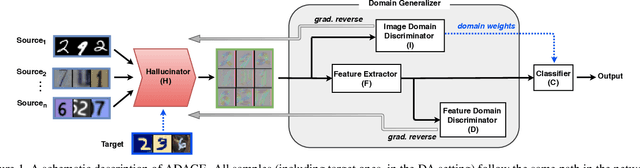
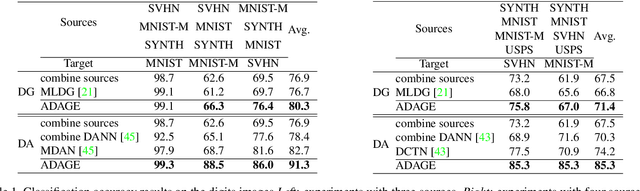

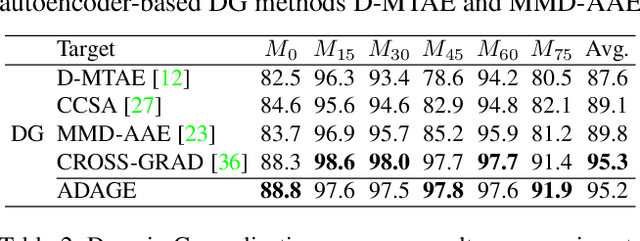
The ability to generalize across visual domains is crucial for the robustness of visual recognition systems in the wild. Several works have been dedicated to close the gap between a single labeled source domain and a target domain with transductive access to its data. In this paper we focus on the wider domain generalization task involving multiple sources and seamlessly extending to unsupervised domain adaptation when unlabeled target samples are available at training time. We propose a hybrid architecture that we name ADAGE: it gracefully maps different source data towards an agnostic visual domain through pixel-adaptation based on a novel incremental architecture, and closes the remaining domain gap through feature adaptation. Both the adaptive processes are guided by adversarial learning. Extensive experiments show remarkable improvements compared to the state of the art.
From source to target and back: symmetric bi-directional adaptive GAN
Nov 29, 2017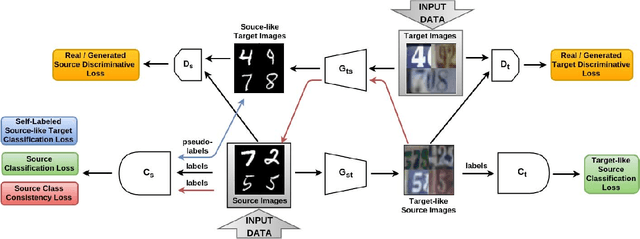
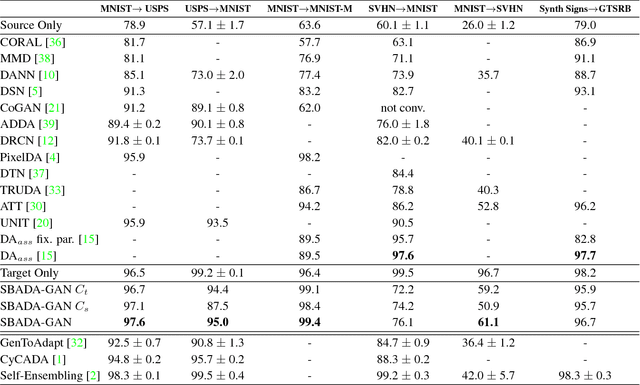
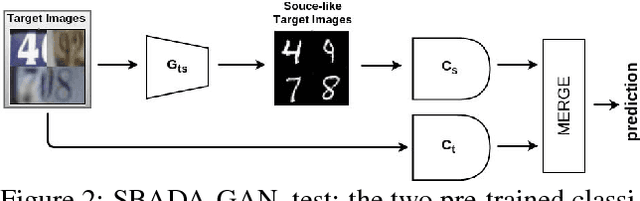
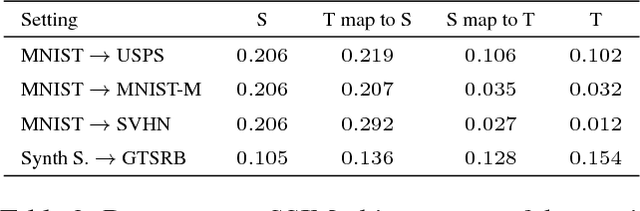
The effectiveness of generative adversarial approaches in producing images according to a specific style or visual domain has recently opened new directions to solve the unsupervised domain adaptation problem. It has been shown that source labeled images can be modified to mimic target samples making it possible to train directly a classifier in the target domain, despite the original lack of annotated data. Inverse mappings from the target to the source domain have also been evaluated but only passing through adapted feature spaces, thus without new image generation. In this paper we propose to better exploit the potential of generative adversarial networks for adaptation by introducing a novel symmetric mapping among domains. We jointly optimize bi-directional image transformations combining them with target self-labeling. Moreover we define a new class consistency loss that aligns the generators in the two directions imposing to conserve the class identity of an image passing through both domain mappings. A detailed qualitative and quantitative analysis of the reconstructed images confirm the power of our approach. By integrating the two domain specific classifiers obtained with our bi-directional network we exceed previous state-of-the-art unsupervised adaptation results on four different benchmark datasets.
A deep representation for depth images from synthetic data
Sep 30, 2016



Convolutional Neural Networks (CNNs) trained on large scale RGB databases have become the secret sauce in the majority of recent approaches for object categorization from RGB-D data. Thanks to colorization techniques, these methods exploit the filters learned from 2D images to extract meaningful representations in 2.5D. Still, the perceptual signature of these two kind of images is very different, with the first usually strongly characterized by textures, and the second mostly by silhouettes of objects. Ideally, one would like to have two CNNs, one for RGB and one for depth, each trained on a suitable data collection, able to capture the perceptual properties of each channel for the task at hand. This has not been possible so far, due to the lack of a suitable depth database. This paper addresses this issue, proposing to opt for synthetically generated images rather than collecting by hand a 2.5D large scale database. While being clearly a proxy for real data, synthetic images allow to trade quality for quantity, making it possible to generate a virtually infinite amount of data. We show that the filters learned from such data collection, using the very same architecture typically used on visual data, learns very different filters, resulting in depth features (a) able to better characterize the different facets of depth images, and (b) complementary with respect to those derived from CNNs pre-trained on 2D datasets. Experiments on two publicly available databases show the power of our approach.
Learning the Roots of Visual Domain Shift
Jul 20, 2016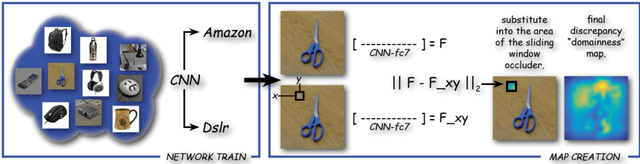
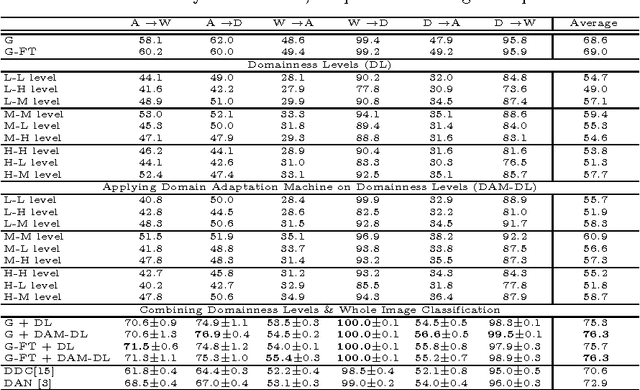
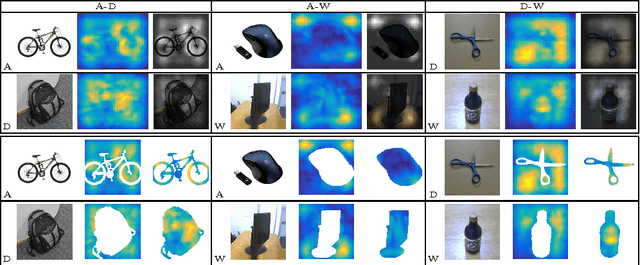
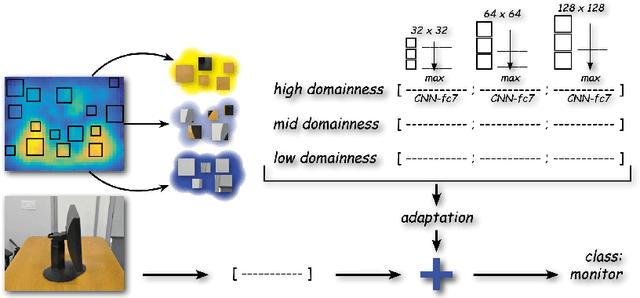
In this paper we focus on the spatial nature of visual domain shift, attempting to learn where domain adaptation originates in each given image of the source and target set. We borrow concepts and techniques from the CNN visualization literature, and learn domainnes maps able to localize the degree of domain specificity in images. We derive from these maps features related to different domainnes levels, and we show that by considering them as a preprocessing step for a domain adaptation algorithm, the final classification performance is strongly improved. Combined with the whole image representation, these features provide state of the art results on the Office dataset.