 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to see across Domains and Modalities
Paper and Code



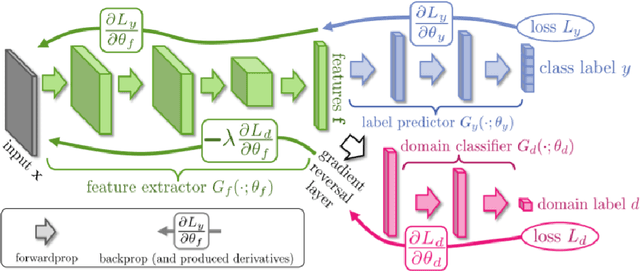
Deep learning has raised hopes and expectations as a general solution for many applications; indeed it has proven effective, but it also showed a strong dependence on large quantities of data. Luckily, it has been shown that, even when data is scarce, a successful model can be trained by reusing prior knowledge. Thus, developing techniques for transfer learning, in its broadest definition, is a crucial element towards the deployment of effective and accurate intelligent systems. This thesis will focus on a family of transfer learning methods applied to the task of visual object recognition, specifically image classification. Transfer learning is a general term, and specific settings have been given specific names: when the learner has only access to unlabeled data from the a target domain and labeled data from a different domain (the source), the problem is known as that of "unsupervised domain adaptation" (DA). The first part of this work will focus on three methods for this setting: one of these methods deals with features, one with images while the third one uses both. The second part will focus on the real life issues of robotic perception, specifically RGB-D recognition. Robotic platforms are usually not limited to color perception; very often they also carry a Depth camera. Unfortunately, the depth modality is rarely used for visual recognition due to the lack of pretrained models from which to transfer and little data to train one on from scratch. Two methods for dealing with this scenario will be presented: one using synthetic data and the other exploiting cross-modality transfer learning.