 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow I Met Your Bias: Investigating Bias Amplification in Diffusion Models
Dec 23, 2025Diffusion-based generative models demonstrate state-of-the-art performance across various image synthesis tasks, yet their tendency to replicate and amplify dataset biases remains poorly understood. Although previous research has viewed bias amplification as an inherent characteristic of diffusion models, this work provides the first analysis of how sampling algorithms and their hyperparameters influence bias amplification. We empirically demonstrate that samplers for diffusion models -- commonly optimized for sample quality and speed -- have a significant and measurable effect on bias amplification. Through controlled studies with models trained on Biased MNIST, Multi-Color MNIST and BFFHQ, and with Stable Diffusion, we show that sampling hyperparameters can induce both bias reduction and amplification, even when the trained model is fixed. Source code is available at https://github.com/How-I-met-your-bias/how_i_met_your_bias.
Specify and Edit: Overcoming Ambiguity in Text-Based Image Editing
Jul 29, 2024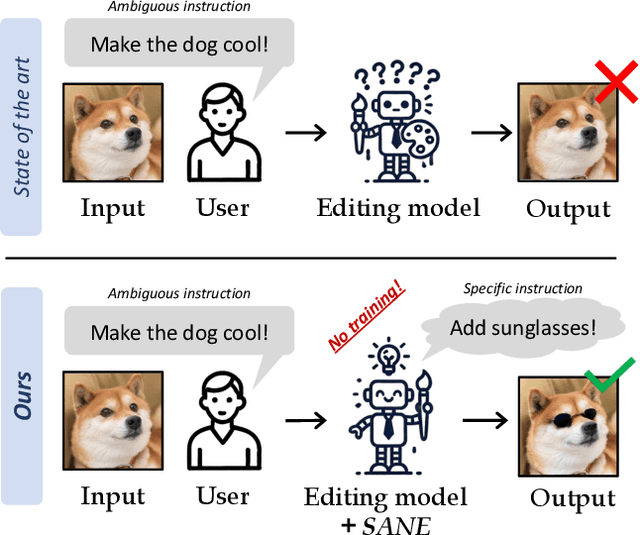
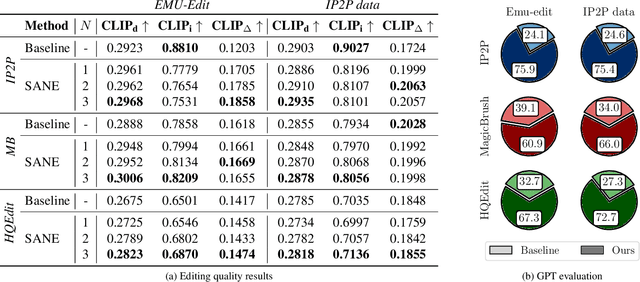
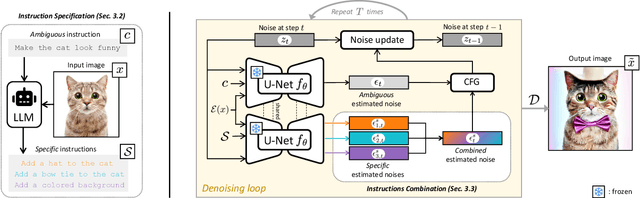

Text-based editing diffusion models exhibit limited performance when the user's input instruction is ambiguous. To solve this problem, we propose $\textit{Specify ANd Edit}$ (SANE), a zero-shot inference pipeline for diffusion-based editing systems. We use a large language model (LLM) to decompose the input instruction into specific instructions, i.e. well-defined interventions to apply to the input image to satisfy the user's request. We benefit from the LLM-derived instructions along the original one, thanks to a novel denoising guidance strategy specifically designed for the task. Our experiments with three baselines and on two datasets demonstrate the benefits of SANE in all setups. Moreover, our pipeline improves the interpretability of editing models, and boosts the output diversity. We also demonstrate that our approach can be applied to any edit, whether ambiguous or not. Our code is public at https://github.com/fabvio/SANE.
Multi-Domain Learning with Modulation Adapters
Jul 17, 2023

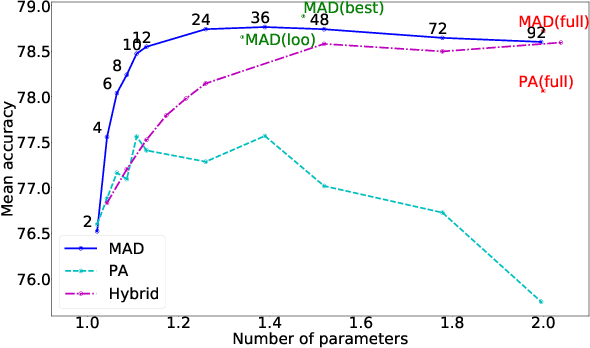

Deep convolutional networks are ubiquitous in computer vision, due to their excellent performance across different tasks for various domains. Models are, however, often trained in isolation for each task, failing to exploit relatedness between tasks and domains to learn more compact models that generalise better in low-data regimes. Multi-domain learning aims to handle related tasks, such as image classification across multiple domains, simultaneously. Previous work on this problem explored the use of a pre-trained and fixed domain-agnostic base network, in combination with smaller learnable domain-specific adaptation modules. In this paper, we introduce Modulation Adapters, which update the convolutional filter weights of the model in a multiplicative manner for each task. Parameterising these adaptation weights in a factored manner allows us to scale the number of per-task parameters in a flexible manner, and to strike different parameter-accuracy trade-offs. We evaluate our approach on the Visual Decathlon challenge, composed of ten image classification tasks across different domains, and on the ImageNet-to-Sketch benchmark, which consists of six image classification tasks. Our approach yields excellent results, with accuracies that are comparable to or better than those of existing state-of-the-art approaches.
Meta-Learning with Shared Amortized Variational Inference
Aug 27, 2020We propose a novel amortized variational inference scheme for an empirical Bayes meta-learning model, where model parameters are treated as latent variables. We learn the prior distribution over model parameters conditioned on limited training data using a variational autoencoder approach. Our framework proposes sharing the same amortized inference network between the conditional prior and variational posterior distributions over the model parameters. While the posterior leverages both the labeled support and query data, the conditional prior is based only on the labeled support data. We show that in earlier work, relying on Monte-Carlo approximation, the conditional prior collapses to a Dirac delta function. In contrast, our variational approach prevents this collapse and preserves uncertainty over the model parameters. We evaluate our approach on the miniImageNet, CIFAR-FS and FC100 datasets, and present results demonstrating its advantages over previous work.