 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Learning Visual Voice Activity Detection with an Automatically Annotated Dataset
Oct 16, 2020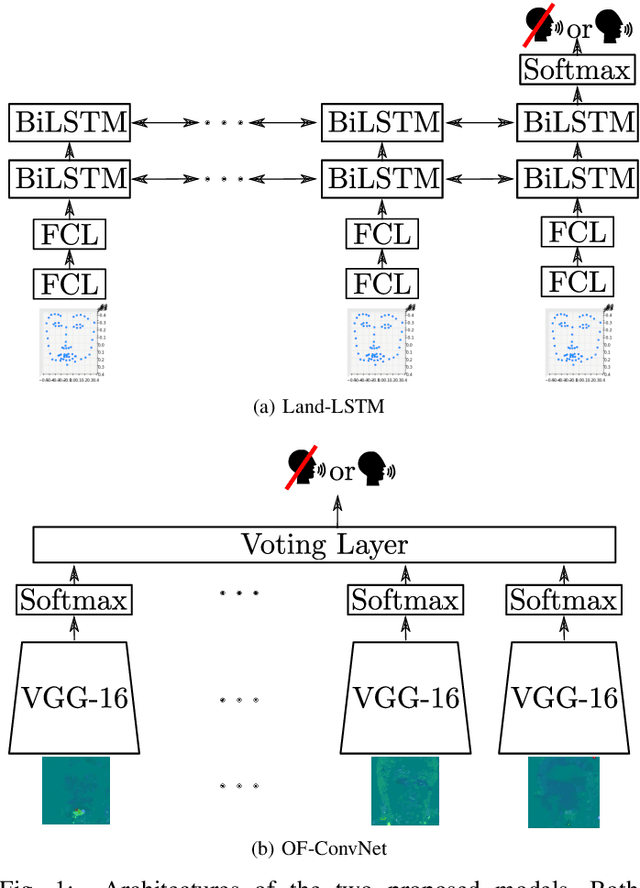
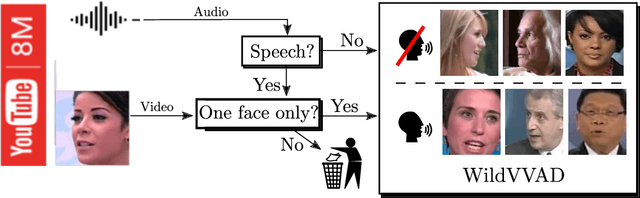


Visual voice activity detection (V-VAD) uses visual features to predict whether a person is speaking or not. V-VAD is useful whenever audio VAD (A-VAD) is inefficient either because the acoustic signal is difficult to analyze or because it is simply missing. We propose two deep architectures for V-VAD, one based on facial landmarks and one based on optical flow. Moreover, available datasets, used for learning and for testing V-VAD, lack content variability. We introduce a novel methodology to automatically create and annotate very large datasets in-the-wild -- WildVVAD -- based on combining A-VAD with face detection and tracking. A thorough empirical evaluation shows the advantage of training the proposed deep V-VAD models with this dataset.
Unsupervised Performance Analysis of 3D Face Alignment
Apr 14, 2020

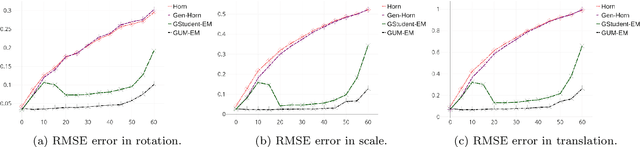

We address the problem of analyzing the performance of 3D face alignment (3DFA) algorithms. Traditionally, performance analysis relies on carefully annotated datasets. Here, these annotations correspond to the 3D coordinates of a set of pre-defined facial landmarks. However, this annotation process, be it manual or automatic, is rarely error-free, which strongly biases the analysis. In contrast, we propose a fully unsupervised methodology based on robust statistics and a parametric confidence test. We revisit the problem of robust estimation of the rigid transformation between two point sets and we describe two algorithms, one based on a mixture between a Gaussian and a uniform distribution, and another one based on the generalized Student's t-distribution. We show that these methods are robust to up to 50\% outliers, which makes them suitable for mapping a face, from an unknown pose to a frontal pose, in the presence of facial expressions and occlusions. Using these methods in conjunction with large datasets of face images, we build a statistical frontal facial model and an associated parametric confidence metric, eventually used for performance analysis. We empirically show that the proposed pipeline is neither method-biased nor data-biased, and that it can be used to assess both the performance of 3DFA algorithms and the accuracy of annotations of face datasets.