 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScoreCAM GNN: une explication optimale des réseaux profonds sur graphes
Jul 26, 2022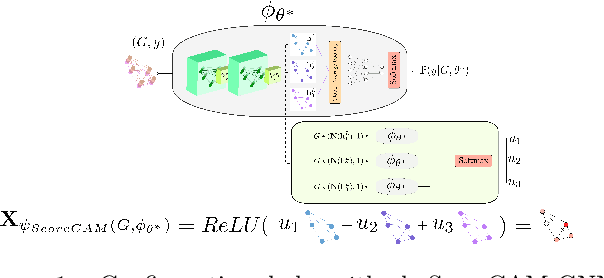
The explainability of deep networks is becoming a central issue in the deep learning community. It is the same for learning on graphs, a data structure present in many real world problems. In this paper, we propose a method that is more optimal, lighter, consistent and better exploits the topology of the evaluated graph than the state-of-the-art methods.
EiX-GNN : Concept-level eigencentrality explainer for graph neural networks
Jun 07, 2022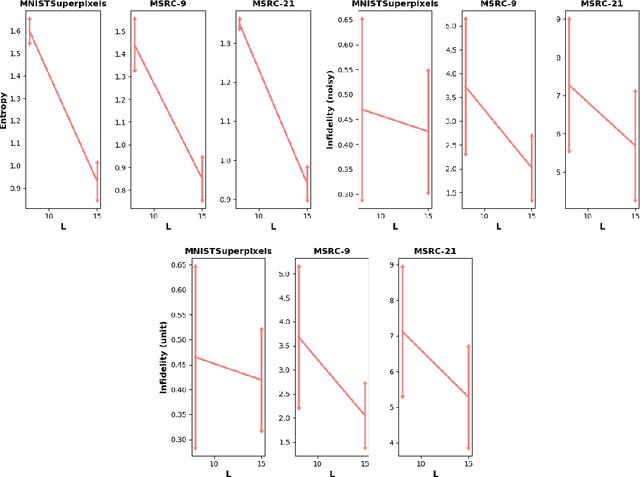
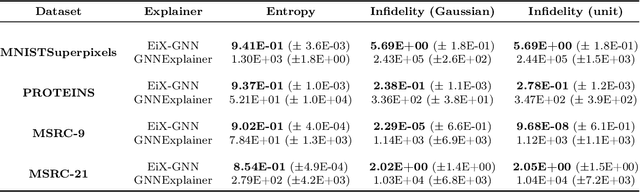

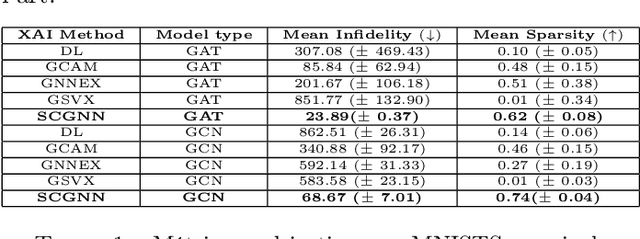
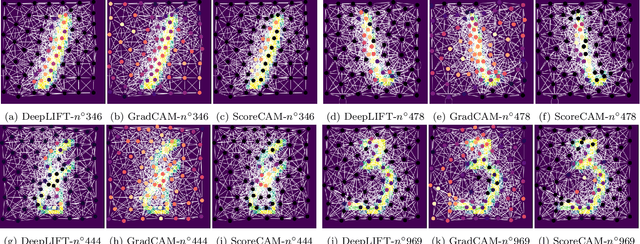
Explaining is a human knowledge transfer process regarding a phenomenon between an explainer and an explainee. Each word used to explain this phenomenon must be carefully selected by the explainer in accordance with the current explainee phenomenon-related knowledge level and the phenomenon itself in order to have a high understanding from the explainee of the phenomenon. Nowadays, deep models, especially graph neural networks, have a major place in daily life even in critical applications. In such context, those models need to have a human high interpretability also referred as being explainable, in order to improve usage trustability of them in sensitive cases. Explaining is also a human dependent task and methods that explain deep model behavior must include these social-related concerns for providing profitable and quality explanations. Current explaining methods often occlude such social aspect for providing their explanations and only focus on the signal aspect of the question. In this contribution we propose a reliable social-aware explaining method suited for graph neural network that includes this social feature as a modular concept generator and by both leveraging signal and graph domain aspect thanks to an eigencentrality concept ordering approach. Besides our method takes into account the human-dependent aspect underlying any explanation process, we also reach high score regarding state-of-the-art objective metrics assessing explanation methods for graph neural networks models.
Unsupervised Performance Analysis of 3D Face Alignment
Apr 14, 2020

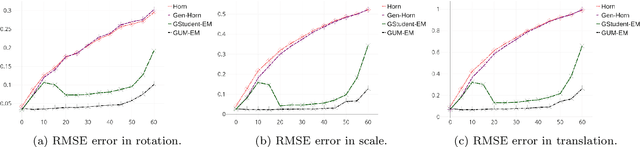

We address the problem of analyzing the performance of 3D face alignment (3DFA) algorithms. Traditionally, performance analysis relies on carefully annotated datasets. Here, these annotations correspond to the 3D coordinates of a set of pre-defined facial landmarks. However, this annotation process, be it manual or automatic, is rarely error-free, which strongly biases the analysis. In contrast, we propose a fully unsupervised methodology based on robust statistics and a parametric confidence test. We revisit the problem of robust estimation of the rigid transformation between two point sets and we describe two algorithms, one based on a mixture between a Gaussian and a uniform distribution, and another one based on the generalized Student's t-distribution. We show that these methods are robust to up to 50\% outliers, which makes them suitable for mapping a face, from an unknown pose to a frontal pose, in the presence of facial expressions and occlusions. Using these methods in conjunction with large datasets of face images, we build a statistical frontal facial model and an associated parametric confidence metric, eventually used for performance analysis. We empirically show that the proposed pipeline is neither method-biased nor data-biased, and that it can be used to assess both the performance of 3DFA algorithms and the accuracy of annotations of face datasets.