 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability in Context: A Multilevel Framework Aligning AI Explanations with Stakeholder with LLMs
Jun 06, 2025The growing application of artificial intelligence in sensitive domains has intensified the demand for systems that are not only accurate but also explainable and trustworthy. Although explainable AI (XAI) methods have proliferated, many do not consider the diverse audiences that interact with AI systems: from developers and domain experts to end-users and society. This paper addresses how trust in AI is influenced by the design and delivery of explanations and proposes a multilevel framework that aligns explanations with the epistemic, contextual, and ethical expectations of different stakeholders. The framework consists of three layers: algorithmic and domain-based, human-centered, and social explainability. We highlight the emerging role of Large Language Models (LLMs) in enhancing the social layer by generating accessible, natural language explanations. Through illustrative case studies, we demonstrate how this approach facilitates technical fidelity, user engagement, and societal accountability, reframing XAI as a dynamic, trust-building process.
STOOD-X methodology: using statistical nonparametric test for OOD Detection Large-Scale datasets enhanced with explainability
Apr 03, 2025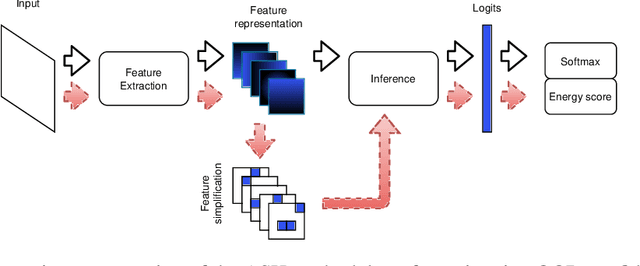

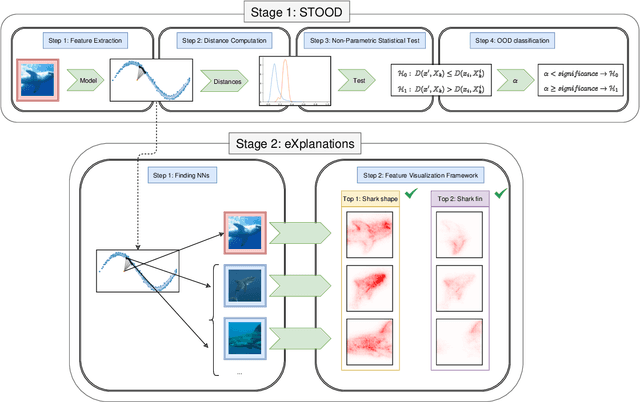

Out-of-Distribution (OOD) detection is a critical task in machine learning, particularly in safety-sensitive applications where model failures can have serious consequences. However, current OOD detection methods often suffer from restrictive distributional assumptions, limited scalability, and a lack of interpretability. To address these challenges, we propose STOOD-X, a two-stage methodology that combines a Statistical nonparametric Test for OOD Detection with eXplainability enhancements. In the first stage, STOOD-X uses feature-space distances and a Wilcoxon-Mann-Whitney test to identify OOD samples without assuming a specific feature distribution. In the second stage, it generates user-friendly, concept-based visual explanations that reveal the features driving each decision, aligning with the BLUE XAI paradigm. Through extensive experiments on benchmark datasets and multiple architectures, STOOD-X achieves competitive performance against state-of-the-art post hoc OOD detectors, particularly in high-dimensional and complex settings. In addition, its explainability framework enables human oversight, bias detection, and model debugging, fostering trust and collaboration between humans and AI systems. The STOOD-X methodology therefore offers a robust, explainable, and scalable solution for real-world OOD detection tasks.
SHIELD: A regularization technique for eXplainable Artificial Intelligence
Apr 03, 2024



As Artificial Intelligence systems become integral across domains, the demand for explainability grows. While the effort by the scientific community is focused on obtaining a better explanation for the model, it is important not to ignore the potential of this explanation process to improve training as well. While existing efforts primarily focus on generating and evaluating explanations for black-box models, there remains a critical gap in directly enhancing models through these evaluations. This paper introduces SHIELD (Selective Hidden Input Evaluation for Learning Dynamics), a regularization technique for explainable artificial intelligence designed to improve model quality by concealing portions of input data and assessing the resulting discrepancy in predictions. In contrast to conventional approaches, SHIELD regularization seamlessly integrates into the objective function, enhancing model explainability while also improving performance. Experimental validation on benchmark datasets underscores SHIELD's effectiveness in improving Artificial Intelligence model explainability and overall performance. This establishes SHIELD regularization as a promising pathway for developing transparent and reliable Artificial Intelligence regularization techniques.
REVEL Framework to measure Local Linear Explanations for black-box models: Deep Learning Image Classification case of study
Nov 11, 2022Explainable artificial intelligence is proposed to provide explanations for reasoning performed by an Artificial Intelligence. There is no consensus on how to evaluate the quality of these explanations, since even the definition of explanation itself is not clear in the literature. In particular, for the widely known Local Linear Explanations, there are qualitative proposals for the evaluation of explanations, although they suffer from theoretical inconsistencies. The case of image is even more problematic, where a visual explanation seems to explain a decision while detecting edges is what it really does. There are a large number of metrics in the literature specialized in quantitatively measuring different qualitative aspects so we should be able to develop metrics capable of measuring in a robust and correct way the desirable aspects of the explanations. In this paper, we propose a procedure called REVEL to evaluate different aspects concerning the quality of explanations with a theoretically coherent development. This procedure has several advances in the state of the art: it standardizes the concepts of explanation and develops a series of metrics not only to be able to compare between them but also to obtain absolute information regarding the explanation itself. The experiments have been carried out on image four datasets as benchmark where we show REVEL's descriptive and analytical power.