 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Attention Mechanism: Boosting the Transformer Architecture for Long-Sequence Time Series Forecasting
Paper and Code


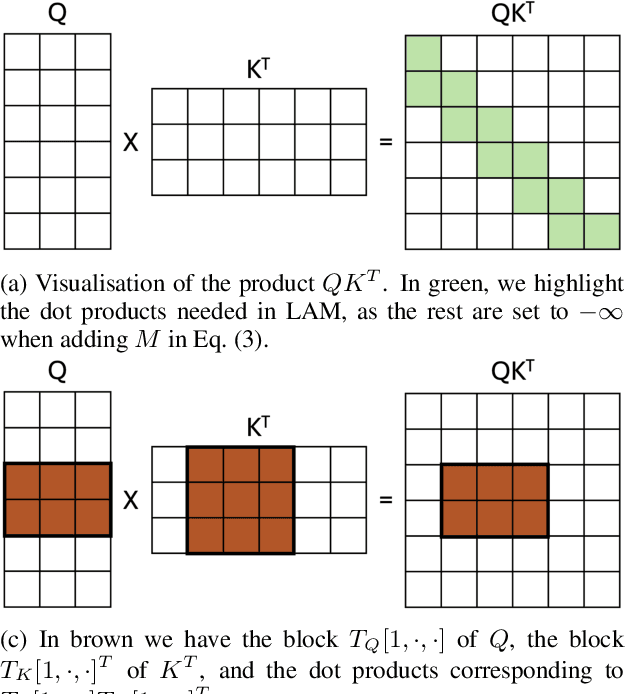

Transformers have become the leading choice in natural language processing over other deep learning architectures. This trend has also permeated the field of time series analysis, especially for long-horizon forecasting, showcasing promising results both in performance and running time. In this paper, we introduce Local Attention Mechanism (LAM), an efficient attention mechanism tailored for time series analysis. This mechanism exploits the continuity properties of time series to reduce the number of attention scores computed. We present an algorithm for implementing LAM in tensor algebra that runs in time and memory O(nlogn), significantly improving upon the O(n^2) time and memory complexity of traditional attention mechanisms. We also note the lack of proper datasets to evaluate long-horizon forecast models. Thus, we propose a novel set of datasets to improve the evaluation of models addressing long-horizon forecasting challenges. Our experimental analysis demonstrates that the vanilla transformer architecture magnified with LAM surpasses state-of-the-art models, including the vanilla attention mechanism. These results confirm the effectiveness of our approach and highlight a range of future challenges in long-sequence time series forecasting.