 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeNeDiF-OOD: Semantic Nested Dichotomy Fusion for Out-of-Distribution Detection Methodology in Open-World Classification. A Case Study on Monument Style Classification
Jan 27, 2026Out-of-distribution (OOD) detection is a fundamental requirement for the reliable deployment of artificial intelligence applications in open-world environments. However, addressing the heterogeneous nature of OOD data, ranging from low-level corruption to semantic shifts, remains a complex challenge that single-stage detectors often fail to resolve. To address this issue, we propose SeNeDiF-OOD, a novel methodology based on Semantic Nested Dichotomy Fusion. This framework decomposes the detection task into a hierarchical structure of binary fusion nodes, where each layer is designed to integrate decision boundaries aligned with specific levels of semantic abstraction. To validate the proposed framework, we present a comprehensive case study using MonuMAI, a real-world architectural style recognition system exposed to an open environment. This application faces a diverse range of inputs, including non-monument images, unknown architectural styles, and adversarial attacks, making it an ideal testbed for our proposal. Through extensive experimental evaluation in this domain, results demonstrate that our hierarchical fusion methodology significantly outperforms traditional baselines, effectively filtering these diverse OOD categories while preserving in-distribution performance.
Triadic Fusion of Cognitive, Functional, and Causal Dimensions for Explainable LLMs: The TAXAL Framework
Sep 05, 2025



Large Language Models (LLMs) are increasingly being deployed in high-risk domains where opacity, bias, and instability undermine trust and accountability. Traditional explainability methods, focused on surface outputs, do not capture the reasoning pathways, planning logic, and systemic impacts of agentic LLMs. We introduce TAXAL (Triadic Alignment for eXplainability in Agentic LLMs), a triadic fusion framework that unites three complementary dimensions: cognitive (user understanding), functional (practical utility), and causal (faithful reasoning). TAXAL provides a unified, role-sensitive foundation for designing, evaluating, and deploying explanations in diverse sociotechnical settings. Our analysis synthesizes existing methods, ranging from post-hoc attribution and dialogic interfaces to explanation-aware prompting, and situates them within the TAXAL triadic fusion model. We further demonstrate its applicability through case studies in law, education, healthcare, and public services, showing how explanation strategies adapt to institutional constraints and stakeholder roles. By combining conceptual clarity with design patterns and deployment pathways, TAXAL advances explainability as a technical and sociotechnical practice, supporting trustworthy and context-sensitive LLM applications in the era of agentic AI.
An overview of model uncertainty and variability in LLM-based sentiment analysis. Challenges, mitigation strategies and the role of explainability
Apr 06, 2025

Large Language Models (LLMs) have significantly advanced sentiment analysis, yet their inherent uncertainty and variability pose critical challenges to achieving reliable and consistent outcomes. This paper systematically explores the Model Variability Problem (MVP) in LLM-based sentiment analysis, characterized by inconsistent sentiment classification, polarization, and uncertainty arising from stochastic inference mechanisms, prompt sensitivity, and biases in training data. We analyze the core causes of MVP, presenting illustrative examples and a case study to highlight its impact. In addition, we investigate key challenges and mitigation strategies, paying particular attention to the role of temperature as a driver of output randomness and emphasizing the crucial role of explainability in improving transparency and user trust. By providing a structured perspective on stability, reproducibility, and trustworthiness, this study helps develop more reliable, explainable, and robust sentiment analysis models, facilitating their deployment in high-stakes domains such as finance, healthcare, and policymaking, among others.
Small data deep learning methodology for in-field disease detection
Sep 25, 2024
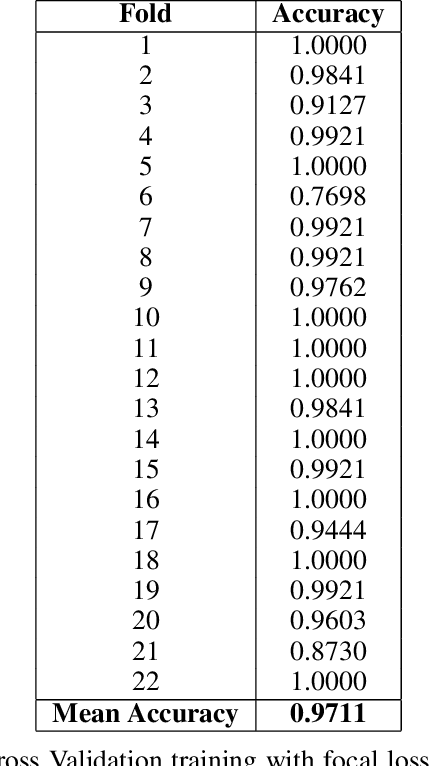


Early detection of diseases in crops is essential to prevent harvest losses and improve the quality of the final product. In this context, the combination of machine learning and proximity sensors is emerging as a technique capable of achieving this detection efficiently and effectively. For example, this machine learning approach has been applied to potato crops -- to detect late blight (Phytophthora infestans) -- and grapevine crops -- to detect downy mildew. However, most of these AI models found in the specialised literature have been developed using leaf-by-leaf images taken in the lab, which does not represent field conditions and limits their applicability. In this study, we present the first machine learning model capable of detecting mild symptoms of late blight in potato crops through the analysis of high-resolution RGB images captured directly in the field, overcoming the limitations of other publications in the literature and presenting real-world applicability. Our proposal exploits the availability of high-resolution images via the concept of patching, and is based on deep convolutional neural networks with a focal loss function, which makes the model to focus on the complex patterns that arise in field conditions. Additionally, we present a data augmentation scheme that facilitates the training of these neural networks with few high-resolution images, which allows for development of models under the small data paradigm. Our model correctly detects all cases of late blight in the test dataset, demonstrating a high level of accuracy and effectiveness in identifying early symptoms. These promising results reinforce the potential use of machine learning for the early detection of diseases and pests in agriculture, enabling better treatment and reducing their impact on crops.
Deep Learning methodology for the identification of wood species using high-resolution macroscopic images
Jun 17, 2024
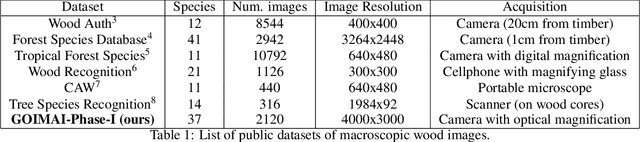


Significant advancements in the field of wood species identification are needed worldwide to support sustainable timber trade. In this work we contribute to automate the identification of wood species via high-resolution macroscopic images of timber. The main challenge of this problem is that fine-grained patterns in timber are crucial in order to accurately identify wood species, and these patterns are not properly learned by traditional convolutional neural networks (CNNs) trained on low/medium resolution images. We propose a Timber Deep Learning Identification with Patch-based Inference Voting methodology, abbreviated TDLI-PIV methodology. Our proposal exploits the concept of patching and the availability of high-resolution macroscopic images of timber in order to overcome the inherent challenges that CNNs face in timber identification. The TDLI-PIV methodology is able to capture fine-grained patterns in timber and, moreover, boosts robustness and prediction accuracy via a collaborative voting inference process. In this work we also introduce a new data set of marcroscopic images of timber, called GOIMAI-Phase-I, which has been obtained using optical magnification in order to capture fine-grained details, which contrasts to the other datasets that are publicly available. More concretely, images in GOIMAI-Phase-I are taken with a smartphone with a 24x magnifying lens attached to the camera. Our data set contains 2120 images of timber and covers 37 legally protected wood species. Our experiments have assessed the performance of the TDLI-PIV methodology, involving the comparison with other methodologies available in the literature, exploration of data augmentation methods and the effect that the dataset size has on the accuracy of TDLI-PIV.
Large language models for crowd decision making based on prompt design strategies using ChatGPT: models, analysis and challenges
Mar 22, 2024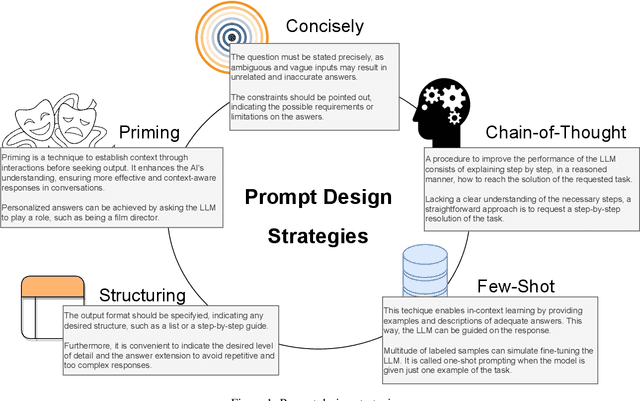



Social Media and Internet have the potential to be exploited as a source of opinion to enrich Decision Making solutions. Crowd Decision Making (CDM) is a methodology able to infer opinions and decisions from plain texts, such as reviews published in social media platforms, by means of Sentiment Analysis. Currently, the emergence and potential of Large Language Models (LLMs) lead us to explore new scenarios of automatically understand written texts, also known as natural language processing. This paper analyzes the use of ChatGPT based on prompt design strategies to assist in CDM processes to extract opinions and make decisions. We integrate ChatGPT in CDM processes as a flexible tool that infer the opinions expressed in texts, providing numerical or linguistic evaluations where the decision making models are based on the prompt design strategies. We include a multi-criteria decision making scenario with a category ontology for criteria. We also consider ChatGPT as an end-to-end CDM model able to provide a general opinion and score on the alternatives. We conduct empirical experiments on real data extracted from TripAdvisor, the TripR-2020Large dataset. The analysis of results show a promising branch for developing quality decision making models using ChatGPT. Finally, we discuss the challenges of consistency, sensitivity and explainability associated to the use of LLMs in CDM processes, raising open questions for future studies.
Design and consensus content validity of the questionnaire for b-learning education: A 2-Tuple Fuzzy Linguistic Delphi based Decision Support Tool
Feb 01, 2024Classic Delphi and Fuzzy Delphi methods are used to test content validity of data collection tools such as questionnaires. Fuzzy Delphi takes the opinion issued by judges from a linguistic perspective reducing ambiguity in opinions by using fuzzy numbers. We propose an extension named 2-Tuple Fuzzy Linguistic Delphi method to deal with scenarios in which judges show different expertise degrees by using fuzzy multigranular semantics of the linguistic terms and to obtain intermediate and final results expressed by 2-tuple linguistic values. The key idea of our proposal is to validate the full questionnaire by means of the evaluation of its parts, defining the validity of each item as a Decision Making problem. Taking the opinion of experts, we measure the degree of consensus, the degree of consistency, and the linguistic score of each item, in order to detect those items that affect, positively or negatively, the quality of the instrument. Considering the real need to evaluate a b-learning educational experience with a consensual questionnaire, we present a Decision Making model for questionnaire validation that solves it. Additionally, we contribute to this consensus reaching problem by developing an online tool under GPL v3 license. The software visualizes the collective valuations for each iteration and assists to determine which parts of the questionnaire should be modified to reach a consensual solution.
* 47 pages, 7 figures
EXplainable Neural-Symbolic Learning (X-NeSyL) methodology to fuse deep learning representations with expert knowledge graphs: the MonuMAI cultural heritage use case
Apr 24, 2021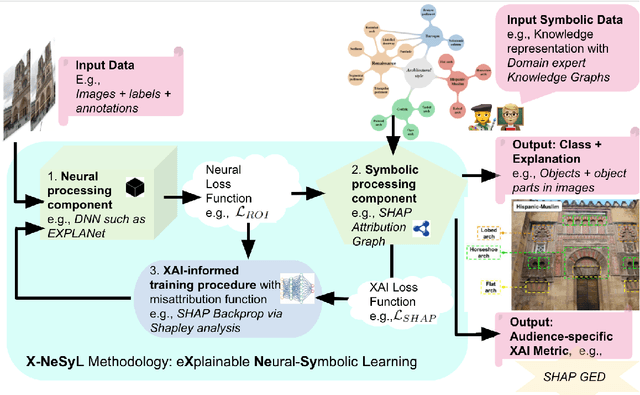
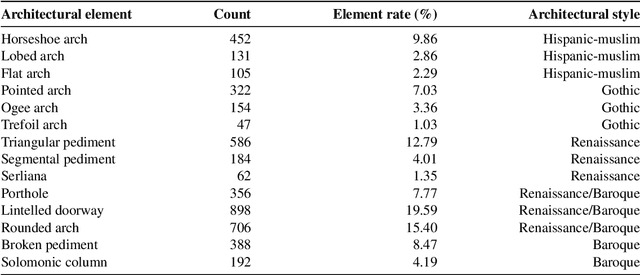


The latest Deep Learning (DL) models for detection and classification have achieved an unprecedented performance over classical machine learning algorithms. However, DL models are black-box methods hard to debug, interpret, and certify. DL alone cannot provide explanations that can be validated by a non technical audience. In contrast, symbolic AI systems that convert concepts into rules or symbols -- such as knowledge graphs -- are easier to explain. However, they present lower generalisation and scaling capabilities. A very important challenge is to fuse DL representations with expert knowledge. One way to address this challenge, as well as the performance-explainability trade-off is by leveraging the best of both streams without obviating domain expert knowledge. We tackle such problem by considering the symbolic knowledge is expressed in form of a domain expert knowledge graph. We present the eXplainable Neural-symbolic learning (X-NeSyL) methodology, designed to learn both symbolic and deep representations, together with an explainability metric to assess the level of alignment of machine and human expert explanations. The ultimate objective is to fuse DL representations with expert domain knowledge during the learning process to serve as a sound basis for explainability. X-NeSyL methodology involves the concrete use of two notions of explanation at inference and training time respectively: 1) EXPLANet: Expert-aligned eXplainable Part-based cLAssifier NETwork Architecture, a compositional CNN that makes use of symbolic representations, and 2) SHAP-Backprop, an explainable AI-informed training procedure that guides the DL process to align with such symbolic representations in form of knowledge graphs. We showcase X-NeSyL methodology using MonuMAI dataset for monument facade image classification, and demonstrate that our approach improves explainability and performance.