 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Paradox of Success in Evolutionary and Bioinspired Optimization: Revisiting Critical Issues, Key Studies, and Methodological Pathways
Jan 13, 2025
Evolutionary and bioinspired computation are crucial for efficiently addressing complex optimization problems across diverse application domains. By mimicking processes observed in nature, like evolution itself, these algorithms offer innovative solutions beyond the reach of traditional optimization methods. They excel at finding near-optimal solutions in large, complex search spaces, making them invaluable in numerous fields. However, both areas are plagued by challenges at their core, including inadequate benchmarking, problem-specific overfitting, insufficient theoretical grounding, and superfluous proposals justified only by their biological metaphor. This overview recapitulates and analyzes in depth the criticisms concerning the lack of innovation and rigor in experimental studies within the field. To this end, we examine the judgmental positions of the existing literature in an informed attempt to guide the research community toward directions of solid contribution and advancement in these areas. We summarize guidelines for the design of evolutionary and bioinspired optimizers, the development of experimental comparisons, and the derivation of novel proposals that take a step further in the field. We provide a brief note on automating the process of creating these algorithms, which may help align metaheuristic optimization research with its primary objective (solving real-world problems), provided that our identified pathways are followed. Our conclusions underscore the need for a sustained push towards innovation and the enforcement of methodological rigor in prospective studies to fully realize the potential of these advanced computational techniques.
A Tutorial on the Design, Experimentation and Application of Metaheuristic Algorithms to Real-World Optimization Problems
Oct 04, 2024



In the last few years, the formulation of real-world optimization problems and their efficient solution via metaheuristic algorithms has been a catalyst for a myriad of research studies. In spite of decades of historical advancements on the design and use of metaheuristics, large difficulties still remain in regards to the understandability, algorithmic design uprightness, and performance verifiability of new technical achievements. A clear example stems from the scarce replicability of works dealing with metaheuristics used for optimization, which is often infeasible due to ambiguity and lack of detail in the presentation of the methods to be reproduced. Additionally, in many cases, there is a questionable statistical significance of their reported results. This work aims at providing the audience with a proposal of good practices which should be embraced when conducting studies about metaheuristics methods used for optimization in order to provide scientific rigor, value and transparency. To this end, we introduce a step by step methodology covering every research phase that should be followed when addressing this scientific field. Specifically, frequently overlooked yet crucial aspects and useful recommendations will be discussed in regards to the formulation of the problem, solution encoding, implementation of search operators, evaluation metrics, design of experiments, and considerations for real-world performance, among others. Finally, we will outline important considerations, challenges, and research directions for the success of newly developed optimization metaheuristics in their deployment and operation over real-world application environments.
General Purpose Artificial Intelligence Systems (GPAIS): Properties, Definition, Taxonomy, Open Challenges and Implications
Jul 26, 2023



Most applications of Artificial Intelligence (AI) are designed for a confined and specific task. However, there are many scenarios that call for a more general AI, capable of solving a wide array of tasks without being specifically designed for them. The term General-Purpose Artificial Intelligence Systems (GPAIS) has been defined to refer to these AI systems. To date, the possibility of an Artificial General Intelligence, powerful enough to perform any intellectual task as if it were human, or even improve it, has remained an aspiration, fiction, and considered a risk for our society. Whilst we might still be far from achieving that, GPAIS is a reality and sitting at the forefront of AI research. This work discusses existing definitions for GPAIS and proposes a new definition that allows for a gradual differentiation among types of GPAIS according to their properties and limitations. We distinguish between closed-world and open-world GPAIS, characterising their degree of autonomy and ability based on several factors such as adaptation to new tasks, competence in domains not intentionally trained for, ability to learn from few data, or proactive acknowledgment of their own limitations. We then propose a taxonomy of approaches to realise GPAIS, describing research trends such as the use of AI techniques to improve another AI or foundation models. As a prime example, we delve into generative AI, aligning them with the terms and concepts presented in the taxonomy. Through the proposed definition and taxonomy, our aim is to facilitate research collaboration across different areas that are tackling general-purpose tasks, as they share many common aspects. Finally, we discuss the current state of GPAIS, its challenges and prospects, implications for our society, and the need for responsible and trustworthy AI systems and regulation, with the goal of providing a holistic view of GPAIS.
Multiobjective Evolutionary Pruning of Deep Neural Networks with Transfer Learning for improving their Performance and Robustness
Feb 20, 2023



Evolutionary Computation algorithms have been used to solve optimization problems in relation with architectural, hyper-parameter or training configuration, forging the field known today as Neural Architecture Search. These algorithms have been combined with other techniques such as the pruning of Neural Networks, which reduces the complexity of the network, and the Transfer Learning, which lets the import of knowledge from another problem related to the one at hand. The usage of several criteria to evaluate the quality of the evolutionary proposals is also a common case, in which the performance and complexity of the network are the most used criteria. This work proposes MO-EvoPruneDeepTL, a multi-objective evolutionary pruning algorithm. \proposal uses Transfer Learning to adapt the last layers of Deep Neural Networks, by replacing them with sparse layers evolved by a genetic algorithm, which guides the evolution based in the performance, complexity and robustness of the network, being the robustness a great quality indicator for the evolved models. We carry out different experiments with several datasets to assess the benefits of our proposal. Results show that our proposal achieves promising results in all the objectives, and direct relation are presented among them. The experiments also show that the most influential neurons help us explain which parts of the input images are the most relevant for the prediction of the pruned neural network. Lastly, by virtue of the diversity within the Pareto front of pruning patterns produced by the proposal, it is shown that an ensemble of differently pruned models improves the overall performance and robustness of the trained networks.
EvoPruneDeepTL: An Evolutionary Pruning Model for Transfer Learning based Deep Neural Networks
Feb 08, 2022



In recent years, Deep Learning models have shown a great performance in complex optimization problems. They generally require large training datasets, which is a limitation in most practical cases. Transfer learning allows importing the first layers of a pre-trained architecture and connecting them to fully-connected layers to adapt them to a new problem. Consequently, the configuration of the these layers becomes crucial for the performance of the model. Unfortunately, the optimization of these models is usually a computationally demanding task. One strategy to optimize Deep Learning models is the pruning scheme. Pruning methods are focused on reducing the complexity of the network, assuming an expected performance penalty of the model once pruned. However, the pruning could potentially be used to improve the performance, using an optimization algorithm to identify and eventually remove unnecessary connections among neurons. This work proposes EvoPruneDeepTL, an evolutionary pruning model for Transfer Learning based Deep Neural Networks which replaces the last fully-connected layers with sparse layers optimized by a genetic algorithm. Depending on its solution encoding strategy, our proposed model can either perform optimized pruning or feature selection over the densely connected part of the neural network. We carry out different experiments with several datasets to assess the benefits of our proposal. Results show the contribution of EvoPruneDeepTL and feature selection to the overall computational efficiency of the network as a result of the optimization process. In particular, the accuracy is improved reducing at the same time the number of active neurons in the final layers.
Lights and Shadows in Evolutionary Deep Learning: Taxonomy, Critical Methodological Analysis, Cases of Study, Learned Lessons, Recommendations and Challenges
Aug 09, 2020
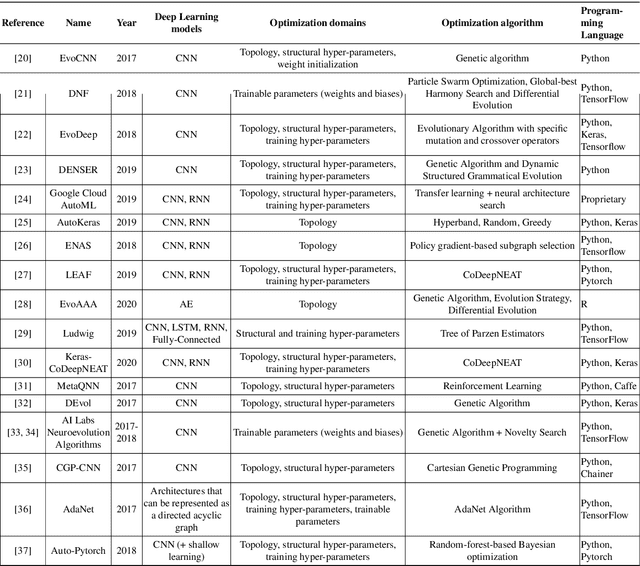
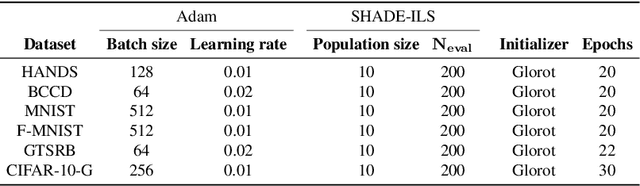
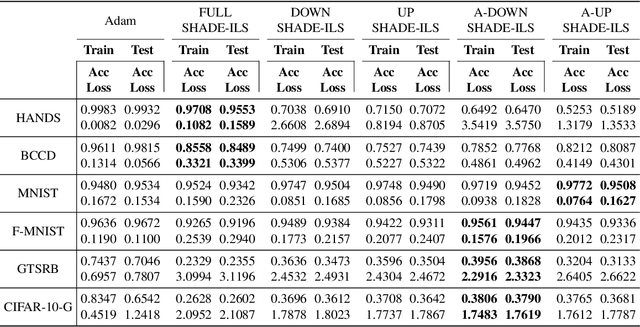
Much has been said about the fusion of bio-inspired optimization algorithms and Deep Learning models for several purposes: from the discovery of network topologies and hyper-parametric configurations with improved performance for a given task, to the optimization of the model's parameters as a replacement for gradient-based solvers. Indeed, the literature is rich in proposals showcasing the application of assorted nature-inspired approaches for these tasks. In this work we comprehensively review and critically examine contributions made so far based on three axes, each addressing a fundamental question in this research avenue: a) optimization and taxonomy (Why?), including a historical perspective, definitions of optimization problems in Deep Learning, and a taxonomy associated with an in-depth analysis of the literature, b) critical methodological analysis (How?), which together with two case studies, allows us to address learned lessons and recommendations for good practices following the analysis of the literature, and c) challenges and new directions of research (What can be done, and what for?). In summary, three axes - optimization and taxonomy, critical analysis, and challenges - which outline a complete vision of a merger of two technologies drawing up an exciting future for this area of fusion research.
Fairness in Bio-inspired Optimization Research: A Prescription of Methodological Guidelines for Comparing Meta-heuristics
Apr 19, 2020
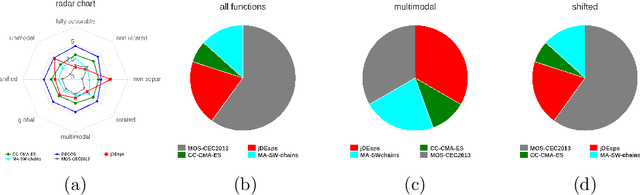
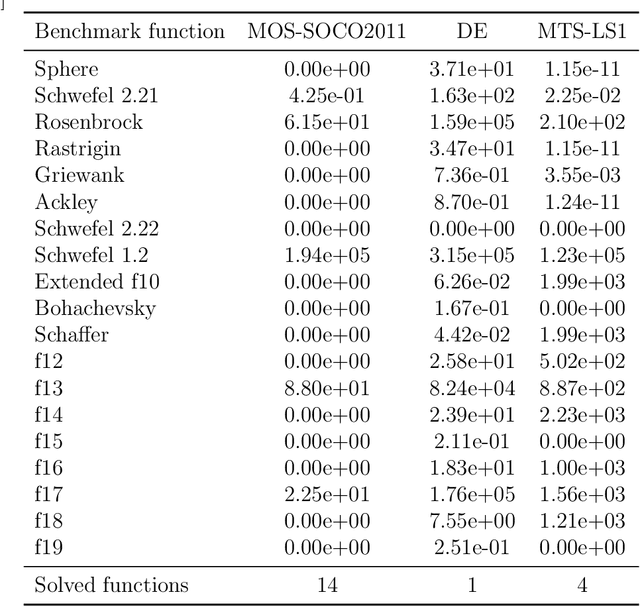
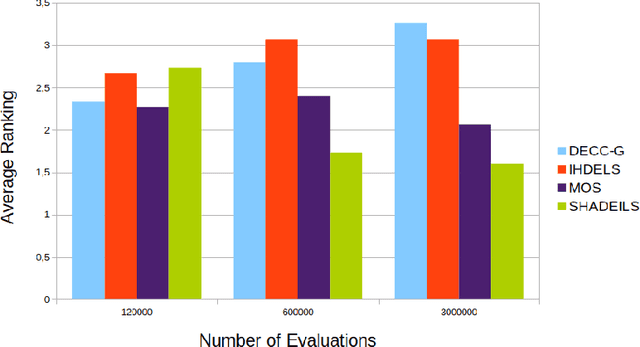
Bio-inspired optimization (including Evolutionary Computation and Swarm Intelligence) is a growing research topic with many competitive bio-inspired algorithms being proposed every year. In such an active area, preparing a successful proposal of a new bio-inspired algorithm is not an easy task. Given the maturity of this research field, proposing a new optimization technique with innovative elements is no longer enough. Apart from the novelty, results reported by the authors should be proven to achieve a significant advance over previous outcomes from the state of the art. Unfortunately, not all new proposals deal with this requirement properly. Some of them fail to select an appropriate benchmark or reference algorithms to compare with. In other cases, the validation process carried out is not defined in a principled way (or is even not done at all). Consequently, the significance of the results presented in such studies cannot be guaranteed. In this work we review several recommendations in the literature and propose methodological guidelines to prepare a successful proposal, taking all these issues into account. We expect these guidelines to be useful not only for authors, but also for reviewers and editors along their assessment of new contributions to the field.
Comprehensive Taxonomies of Nature- and Bio-inspired Optimization: Inspiration versus Algorithmic Behavior, Critical Analysis and Recommendations
Feb 20, 2020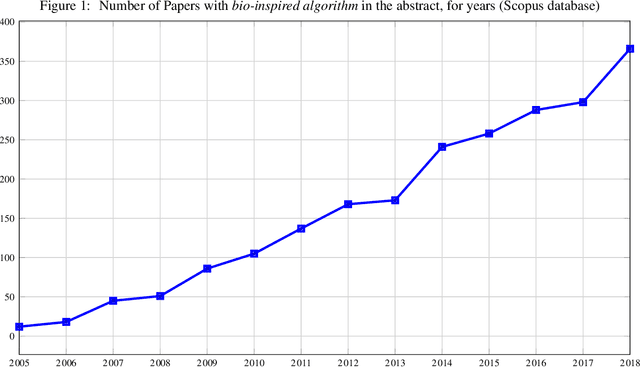
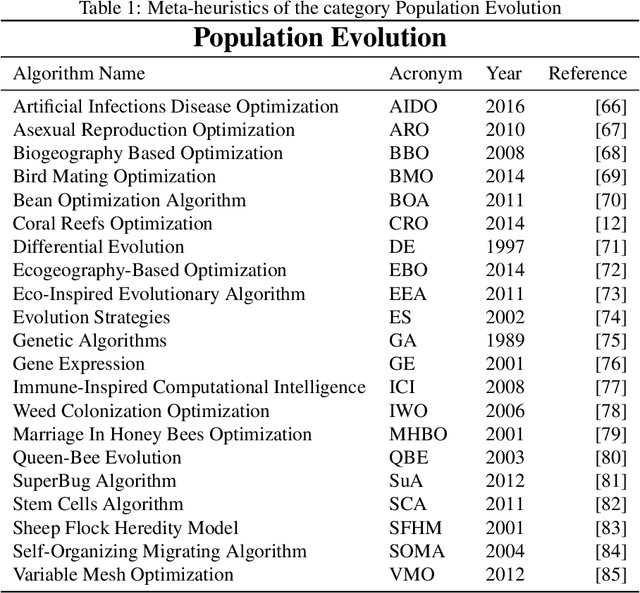
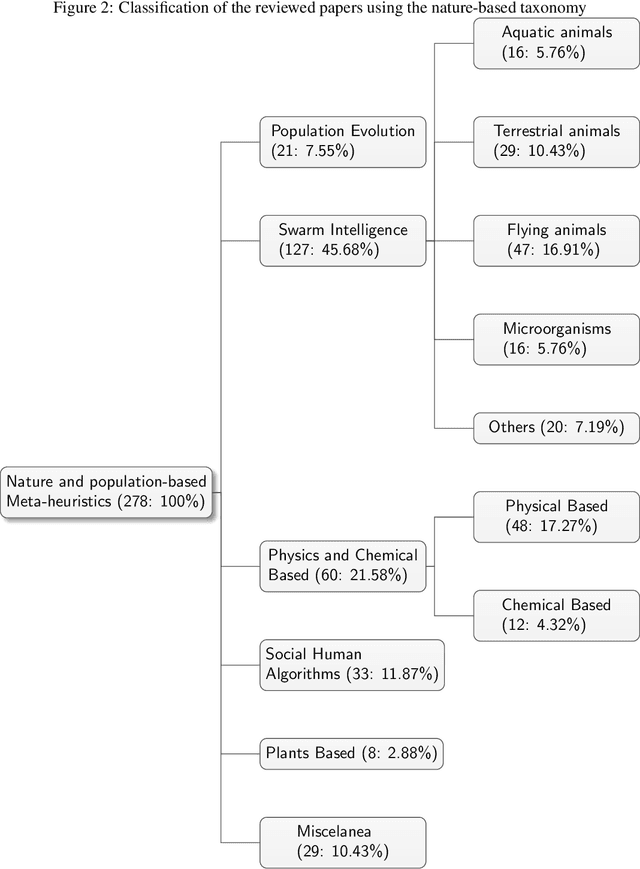
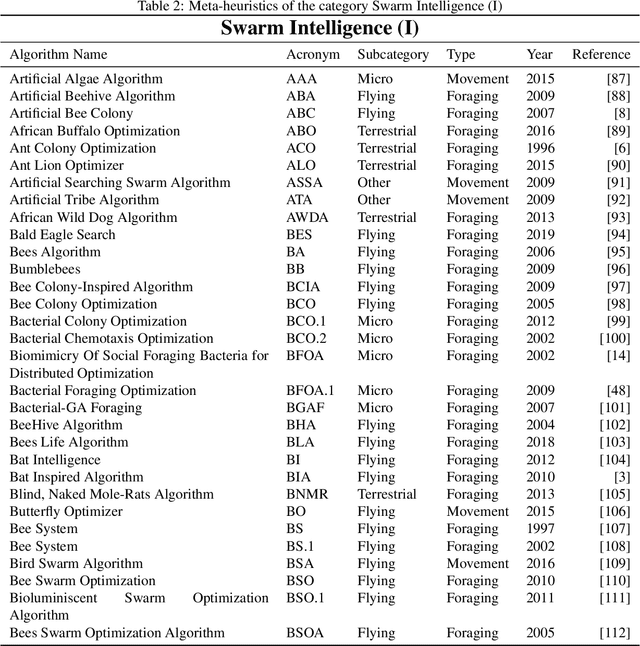
In recent years, a great variety of nature- and bio-inspired algorithms has been reported in the literature. This algorithmic family simulates different biological processes observed in Nature in order to efficiently address complex optimization problems. In the last years the number of bio-inspired optimization approaches in literature has grown considerably, reaching unprecedented levels that dark the future prospects of this field of research. This paper addresses this problem by proposing two comprehensive, principle-based taxonomies that allow researchers to organize existing and future algorithmic developments into well-defined categories, considering two different criteria: the source of inspiration and the behavior of each algorithm. Using these taxonomies we review more than three hundred publications dealing with nature-inspired and bio-inspired algorithms, and proposals falling within each of these categories are examined, leading to a critical summary of design trends and similarities between them, and the identification of the most similar classical algorithm for each reviewed paper. From our analysis we conclude that a poor relationship is often found between the natural inspiration of an algorithm and its behavior. Furthermore, similarities in terms of behavior between different algorithms are greater than what is claimed in their public disclosure: specifically, we show that more than one-third of the reviewed bio-inspired solvers are versions of classical algorithms. Grounded on the conclusions of our critical analysis, we give several recommendations and points of improvement for better methodological practices in this active and growing research field.
Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI
Oct 22, 2019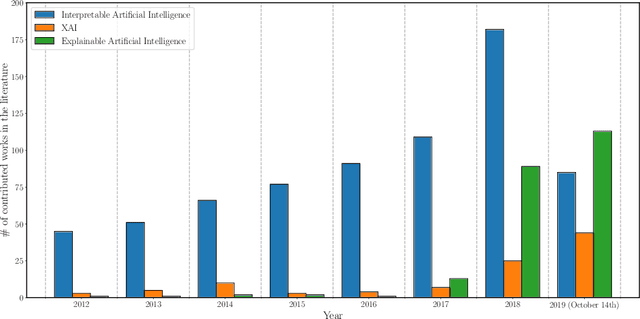
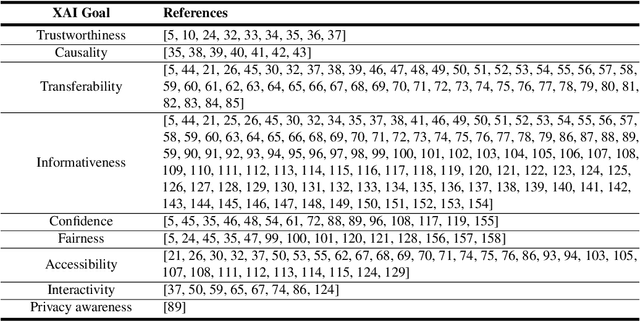
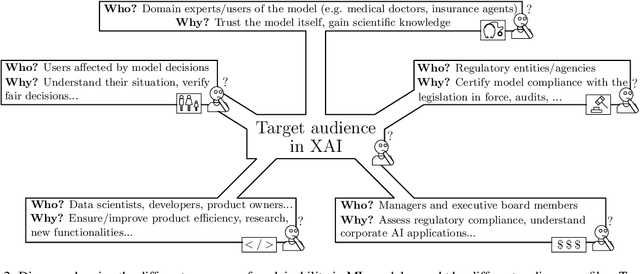

In the last years, Artificial Intelligence (AI) has achieved a notable momentum that may deliver the best of expectations over many application sectors across the field. For this to occur, the entire community stands in front of the barrier of explainability, an inherent problem of AI techniques brought by sub-symbolism (e.g. ensembles or Deep Neural Networks) that were not present in the last hype of AI. Paradigms underlying this problem fall within the so-called eXplainable AI (XAI) field, which is acknowledged as a crucial feature for the practical deployment of AI models. This overview examines the existing literature in the field of XAI, including a prospect toward what is yet to be reached. We summarize previous efforts to define explainability in Machine Learning, establishing a novel definition that covers prior conceptual propositions with a major focus on the audience for which explainability is sought. We then propose and discuss about a taxonomy of recent contributions related to the explainability of different Machine Learning models, including those aimed at Deep Learning methods for which a second taxonomy is built. This literature analysis serves as the background for a series of challenges faced by XAI, such as the crossroads between data fusion and explainability. Our prospects lead toward the concept of Responsible Artificial Intelligence, namely, a methodology for the large-scale implementation of AI methods in real organizations with fairness, model explainability and accountability at its core. Our ultimate goal is to provide newcomers to XAI with a reference material in order to stimulate future research advances, but also to encourage experts and professionals from other disciplines to embrace the benefits of AI in their activity sectors, without any prior bias for its lack of interpretability.
Learning Critical Regions for Robot Planning using Convolutional Neural Networks
Apr 15, 2019

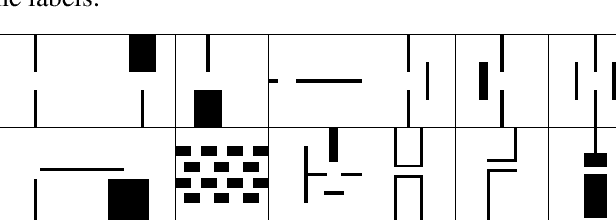

In this paper, we present a new approach to learning for motion planning (MP) where critical regions of an environment with low probability measure are learned from a given set of motion plans and used to improve performance on new problem instances. We show that convolutional neural networks (CNN) can be used to identify critical regions for motion planning problems. We also introduce a new sampling-based motion planner, Learn and Link. Our planner leverages critical region locations identified by our CNN to overcome the limitations of uniform sampling, while still maintaining guarantees of correctness inherent to sampling-based algorithms. We evaluate Learn and Link against planners from the Open Motion Planning Library (OMPL) using an extensive suite of experiments on challenging navigation planning problems. We show that our approach requires far less planning time than the existing sampling-based planners.