 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Energy Prediction Smart-Meter Dataset: Analysis of Previous Competitions and Beyond
Nov 07, 2023



This paper presents the real-world smart-meter dataset and offers an analysis of solutions derived from the Energy Prediction Technical Challenges, focusing primarily on two key competitions: the IEEE Computational Intelligence Society (IEEE-CIS) Technical Challenge on Energy Prediction from Smart Meter data in 2020 (named EP) and its follow-up challenge at the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) in 2021 (named as XEP). These competitions focus on accurate energy consumption forecasting and the importance of interpretability in understanding the underlying factors. The challenge aims to predict monthly and yearly estimated consumption for households, addressing the accurate billing problem with limited historical smart meter data. The dataset comprises 3,248 smart meters, with varying data availability ranging from a minimum of one month to a year. This paper delves into the challenges, solutions and analysing issues related to the provided real-world smart meter data, developing accurate predictions at the household level, and introducing evaluation criteria for assessing interpretability. Additionally, this paper discusses aspects beyond the competitions: opportunities for energy disaggregation and pattern detection applications at the household level, significance of communicating energy-driven factors for optimised billing, and emphasising the importance of responsible AI and data privacy considerations. These aspects provide insights into the broader implications and potential advancements in energy consumption prediction. Overall, these competitions provide a dataset for residential energy research and serve as a catalyst for exploring accurate forecasting, enhancing interpretability, and driving progress towards the discussion of various aspects such as energy disaggregation, demand response programs or behavioural interventions.
General Purpose Artificial Intelligence Systems (GPAIS): Properties, Definition, Taxonomy, Open Challenges and Implications
Jul 26, 2023



Most applications of Artificial Intelligence (AI) are designed for a confined and specific task. However, there are many scenarios that call for a more general AI, capable of solving a wide array of tasks without being specifically designed for them. The term General-Purpose Artificial Intelligence Systems (GPAIS) has been defined to refer to these AI systems. To date, the possibility of an Artificial General Intelligence, powerful enough to perform any intellectual task as if it were human, or even improve it, has remained an aspiration, fiction, and considered a risk for our society. Whilst we might still be far from achieving that, GPAIS is a reality and sitting at the forefront of AI research. This work discusses existing definitions for GPAIS and proposes a new definition that allows for a gradual differentiation among types of GPAIS according to their properties and limitations. We distinguish between closed-world and open-world GPAIS, characterising their degree of autonomy and ability based on several factors such as adaptation to new tasks, competence in domains not intentionally trained for, ability to learn from few data, or proactive acknowledgment of their own limitations. We then propose a taxonomy of approaches to realise GPAIS, describing research trends such as the use of AI techniques to improve another AI or foundation models. As a prime example, we delve into generative AI, aligning them with the terms and concepts presented in the taxonomy. Through the proposed definition and taxonomy, our aim is to facilitate research collaboration across different areas that are tackling general-purpose tasks, as they share many common aspects. Finally, we discuss the current state of GPAIS, its challenges and prospects, implications for our society, and the need for responsible and trustworthy AI systems and regulation, with the goal of providing a holistic view of GPAIS.
AutoEn: An AutoML method based on ensembles of predefined Machine Learning pipelines for supervised Traffic Forecasting
Mar 19, 2023



Intelligent Transportation Systems are producing tons of hardly manageable traffic data, which motivates the use of Machine Learning (ML) for data-driven applications, such as Traffic Forecasting (TF). TF is gaining relevance due to its ability to mitigate traffic congestion by forecasting future traffic states. However, TF poses one big challenge to the ML paradigm, known as the Model Selection Problem (MSP): deciding the most suitable combination of data preprocessing techniques and ML method for traffic data collected under different transportation circumstances. In this context, Automated Machine Learning (AutoML), the automation of the ML workflow from data preprocessing to model validation, arises as a promising strategy to deal with the MSP in problem domains wherein expert ML knowledge is not always an available or affordable asset, such as TF. Various AutoML frameworks have been used to approach the MSP in TF. Most are based on online optimisation processes to search for the best-performing pipeline on a given dataset. This online optimisation could be complemented with meta-learning to warm-start the search phase and/or the construction of ensembles using pipelines derived from the optimisation process. However, given the complexity of the search space and the high computational cost of tuning-evaluating pipelines generated, online optimisation is only beneficial when there is a long time to obtain the final model. Thus, we introduce AutoEn, which is a simple and efficient method for automatically generating multi-classifier ensembles from a predefined set of ML pipelines. We compare AutoEn against Auto-WEKA and Auto-sklearn, two AutoML methods commonly used in TF. Experimental results demonstrate that AutoEn can lead to better or more competitive results in the general-purpose domain and in TF.
Forecasting Solar Irradiance without Direct Observation: An Empirical Analysis
Mar 10, 2023As the use of solar power increases, having accurate and timely forecasters will be essential for smooth grid operators. There are many proposed methods for forecasting solar irradiance / solar power production. However, many of these methods formulate the problem as a time-series, relying on near real-time access to observations at the location of interest to generate forecasts. This requires both access to a real-time stream of data and enough historical observations for these methods to be deployed. In this paper, we conduct a thorough analysis of effective ways to formulate the forecasting problem comparing classical machine learning approaches to state-of-the-art deep learning. Using data from 20 locations distributed throughout the UK and commercially available weather data, we show that it is possible to build systems that do not require access to this data. Leveraging weather observations and measurements from other locations we show it is possible to create models capable of accurately forecasting solar irradiance at new locations. We utilise compare both satellite and ground observations (e.g. temperature, pressure) of weather data. This could facilitate use planning and optimisation for both newly deployed solar farms and domestic installations from the moment they come online. Additionally, we show that training a single global model for multiple locations can produce a more robust model with more consistent and accurate results across locations.
CzSL: A new learning paradigm for astronomical image classification with citizen science
Feb 01, 2023
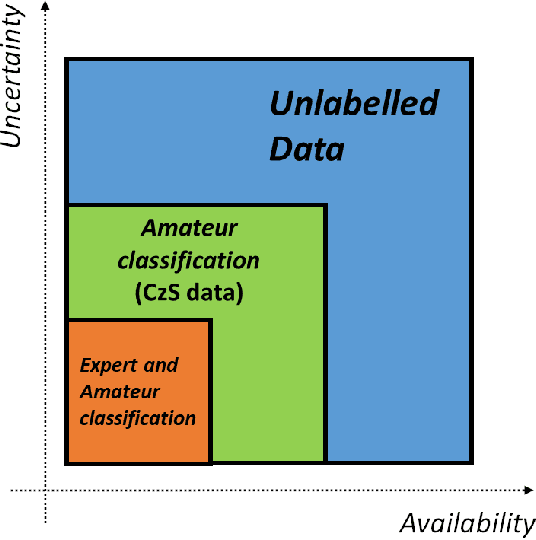

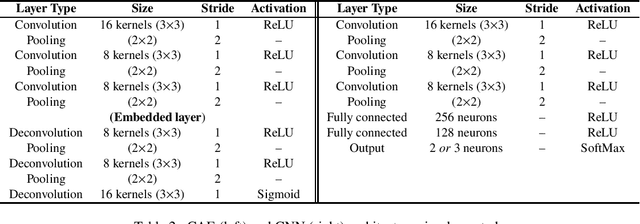
Citizen science is gaining popularity as a valuable tool for labelling large collections of astronomical images by the general public. This is often achieved at the cost of poorer quality classifications made by amateur participants, which are usually verified by employing smaller data sets labelled by professional astronomers. Despite its success, citizen science alone will not be able to handle the classification of current and upcoming surveys. To alleviate this issue, citizen science projects have been coupled with machine learning techniques in pursuit of a more robust automated classification. However, existing approaches have neglected the fact that, apart from the data labelled by amateurs, (limited) expert knowledge of the problem is also available along with vast amounts of unlabelled data that have not yet been exploited within a unified learning framework. This paper presents an innovative learning paradigm for citizen science capable of taking advantage of expert- and amateur-labelled data, and unlabelled data. The proposed methodology first learns from unlabelled data with a convolutional autoencoder and then exploits amateur and expert labels via the pre-training and fine-tuning of a convolutional neural network, respectively. We focus on the classification of galaxy images from the Galaxy Zoo project, from which we test binary, multi-class, and imbalanced classification scenarios. The results demonstrate that our solution is able to improve classification performance compared to a set of baseline approaches, deploying a promising methodology for learning from different confidence levels in data labelling.
Comparison and Evaluation of Methods for a Predict+Optimize Problem in Renewable Energy
Dec 21, 2022
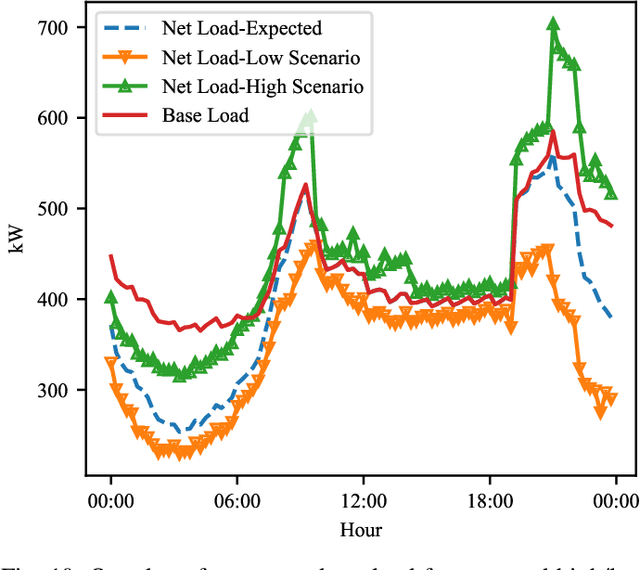
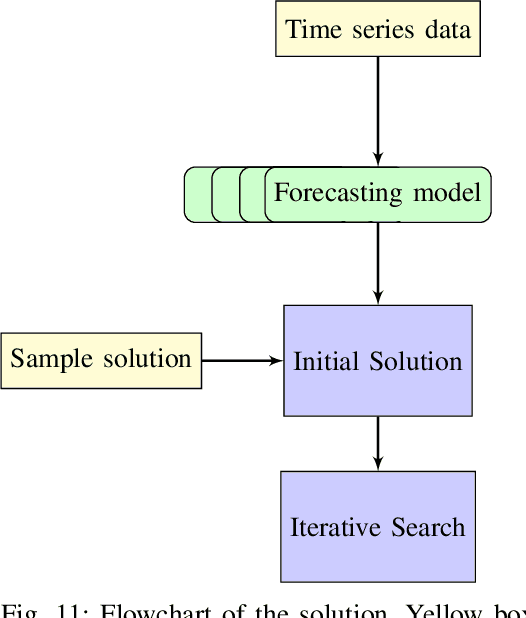
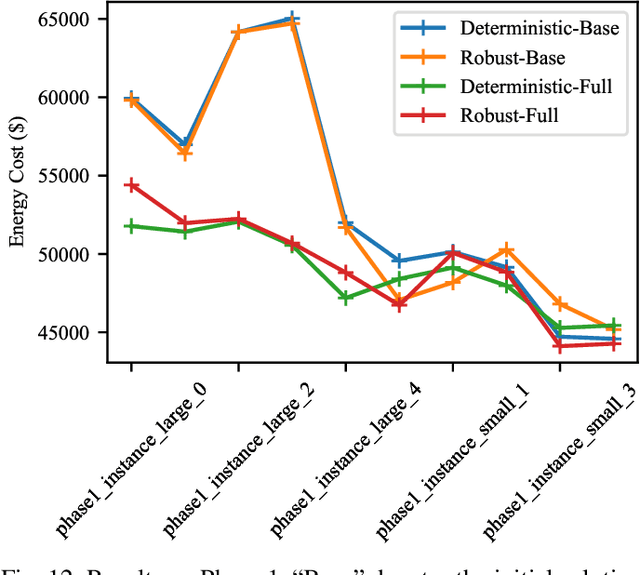
Algorithms that involve both forecasting and optimization are at the core of solutions to many difficult real-world problems, such as in supply chains (inventory optimization), traffic, and in the transition towards carbon-free energy generation in battery/load/production scheduling in sustainable energy systems. Typically, in these scenarios we want to solve an optimization problem that depends on unknown future values, which therefore need to be forecast. As both forecasting and optimization are difficult problems in their own right, relatively few research has been done in this area. This paper presents the findings of the ``IEEE-CIS Technical Challenge on Predict+Optimize for Renewable Energy Scheduling," held in 2021. We present a comparison and evaluation of the seven highest-ranked solutions in the competition, to provide researchers with a benchmark problem and to establish the state of the art for this benchmark, with the aim to foster and facilitate research in this area. The competition used data from the Monash Microgrid, as well as weather data and energy market data. It then focused on two main challenges: forecasting renewable energy production and demand, and obtaining an optimal schedule for the activities (lectures) and on-site batteries that lead to the lowest cost of energy. The most accurate forecasts were obtained by gradient-boosted tree and random forest models, and optimization was mostly performed using mixed integer linear and quadratic programming. The winning method predicted different scenarios and optimized over all scenarios jointly using a sample average approximation method.
L2AE-D: Learning to Aggregate Embeddings for Few-shot Learning with Meta-level Dropout
Apr 08, 2019
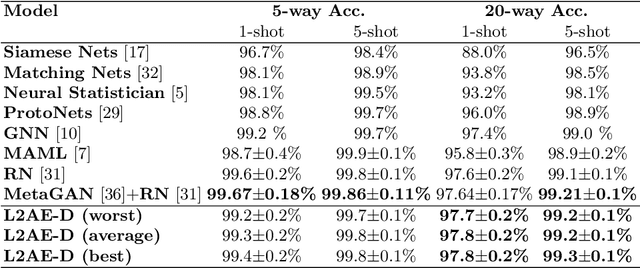
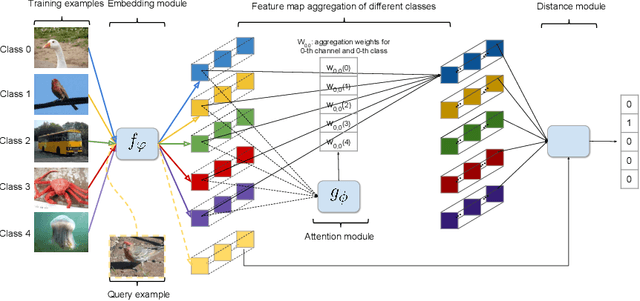
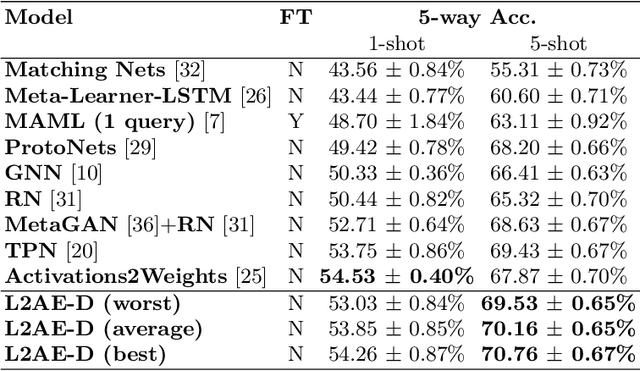
Few-shot learning focuses on learning a new visual concept with very limited labelled examples. A successful approach to tackle this problem is to compare the similarity between examples in a learned metric space based on convolutional neural networks. However, existing methods typically suffer from meta-level overfitting due to the limited amount of training tasks and do not normally consider the importance of the convolutional features of different examples within the same channel. To address these limitations, we make the following two contributions: (a) We propose a novel meta-learning approach for aggregating useful convolutional features and suppressing noisy ones based on a channel-wise attention mechanism to improve class representations. The proposed model does not require fine-tuning and can be trained in an end-to-end manner. The main novelty lies in incorporating a shared weight generation module that learns to assign different weights to the feature maps of different examples within the same channel. (b) We also introduce a simple meta-level dropout technique that reduces meta-level overfitting in several few-shot learning approaches. In our experiments, we find that this simple technique significantly improves the performance of the proposed method as well as various state-of-the-art meta-learning algorithms. Applying our method to few-shot image recognition using Omniglot and miniImageNet datasets shows that it is capable of delivering a state-of-the-art classification performance.
On the use of convolutional neural networks for robust classification of multiple fingerprint captures
May 15, 2017



Fingerprint classification is one of the most common approaches to accelerate the identification in large databases of fingerprints. Fingerprints are grouped into disjoint classes, so that an input fingerprint is compared only with those belonging to the predicted class, reducing the penetration rate of the search. The classification procedure usually starts by the extraction of features from the fingerprint image, frequently based on visual characteristics. In this work, we propose an approach to fingerprint classification using convolutional neural networks, which avoid the necessity of an explicit feature extraction process by incorporating the image processing within the training of the classifier. Furthermore, such an approach is able to predict a class even for low-quality fingerprints that are rejected by commonly used algorithms, such as FingerCode. The study gives special importance to the robustness of the classification for different impressions of the same fingerprint, aiming to minimize the penetration in the database. In our experiments, convolutional neural networks yielded better accuracy and penetration rate than state-of-the-art classifiers based on explicit feature extraction. The tested networks also improved on the runtime, as a result of the joint optimization of both feature extraction and classification.