 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecast reconciliation for vaccine supply chain optimization
May 02, 2023Vaccine supply chain optimization can benefit from hierarchical time series forecasting, when grouping the vaccines by type or location. However, forecasts of different hierarchy levels become incoherent when higher levels do not match the sum of the lower levels forecasts, which can be addressed by reconciliation methods. In this paper, we tackle the vaccine sale forecasting problem by modeling sales data from GSK between 2010 and 2021 as a hierarchical time series. After forecasting future values with several ARIMA models, we systematically compare the performance of various reconciliation methods, using statistical tests. We also compare the performance of the forecast before and after COVID. The results highlight Minimum Trace and Weighted Least Squares with Structural scaling as the best performing methods, which provided a coherent forecast while reducing the forecast error of the baseline ARIMA.
Semi-Supervised Constrained Clustering: An In-Depth Overview, Ranked Taxonomy and Future Research Directions
Feb 28, 2023Clustering is a well-known unsupervised machine learning approach capable of automatically grouping discrete sets of instances with similar characteristics. Constrained clustering is a semi-supervised extension to this process that can be used when expert knowledge is available to indicate constraints that can be exploited. Well-known examples of such constraints are must-link (indicating that two instances belong to the same group) and cannot-link (two instances definitely do not belong together). The research area of constrained clustering has grown significantly over the years with a large variety of new algorithms and more advanced types of constraints being proposed. However, no unifying overview is available to easily understand the wide variety of available methods, constraints and benchmarks. To remedy this, this study presents in-detail the background of constrained clustering and provides a novel ranked taxonomy of the types of constraints that can be used in constrained clustering. In addition, it focuses on the instance-level pairwise constraints, and gives an overview of its applications and its historical context. Finally, it presents a statistical analysis covering 307 constrained clustering methods, categorizes them according to their features, and provides a ranking score indicating which methods have the most potential based on their popularity and validation quality. Finally, based upon this analysis, potential pitfalls and future research directions are provided.
Comparison and Evaluation of Methods for a Predict+Optimize Problem in Renewable Energy
Dec 21, 2022
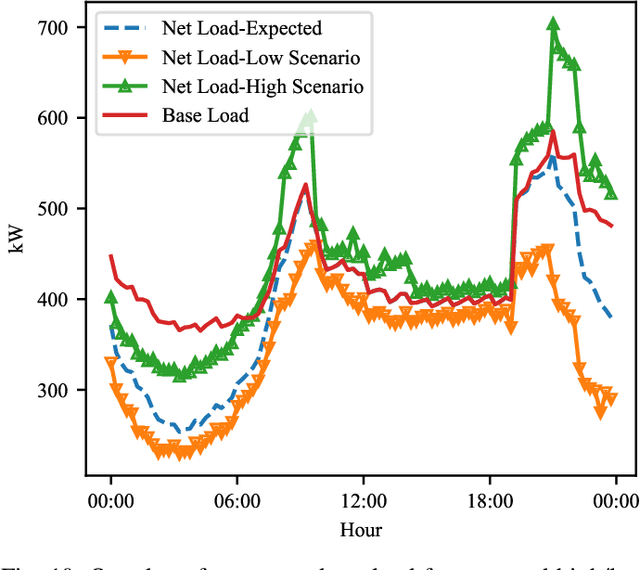
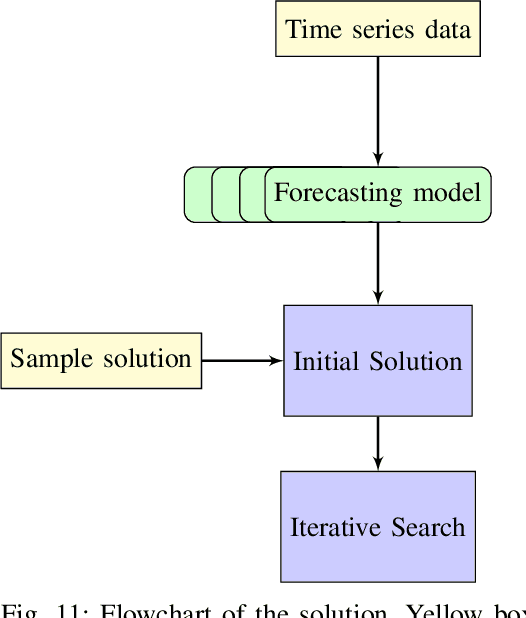
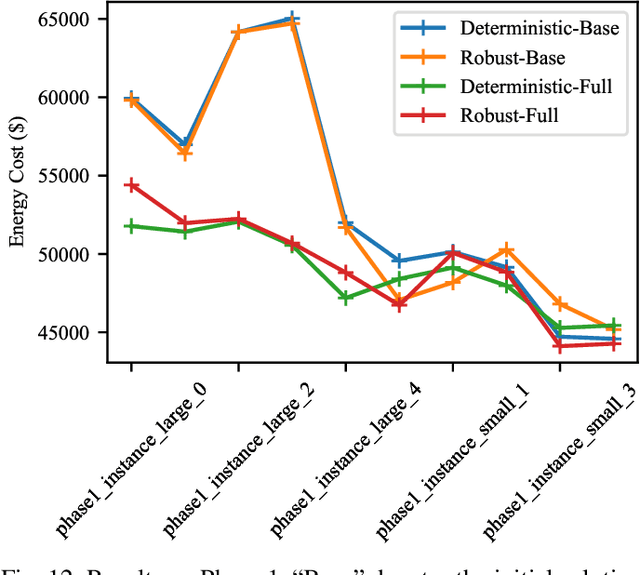
Algorithms that involve both forecasting and optimization are at the core of solutions to many difficult real-world problems, such as in supply chains (inventory optimization), traffic, and in the transition towards carbon-free energy generation in battery/load/production scheduling in sustainable energy systems. Typically, in these scenarios we want to solve an optimization problem that depends on unknown future values, which therefore need to be forecast. As both forecasting and optimization are difficult problems in their own right, relatively few research has been done in this area. This paper presents the findings of the ``IEEE-CIS Technical Challenge on Predict+Optimize for Renewable Energy Scheduling," held in 2021. We present a comparison and evaluation of the seven highest-ranked solutions in the competition, to provide researchers with a benchmark problem and to establish the state of the art for this benchmark, with the aim to foster and facilitate research in this area. The competition used data from the Monash Microgrid, as well as weather data and energy market data. It then focused on two main challenges: forecasting renewable energy production and demand, and obtaining an optimal schedule for the activities (lectures) and on-site batteries that lead to the lowest cost of energy. The most accurate forecasts were obtained by gradient-boosted tree and random forest models, and optimization was mostly performed using mixed integer linear and quadratic programming. The winning method predicted different scenarios and optimized over all scenarios jointly using a sample average approximation method.
Representing missing values through polar encoding
Oct 04, 2022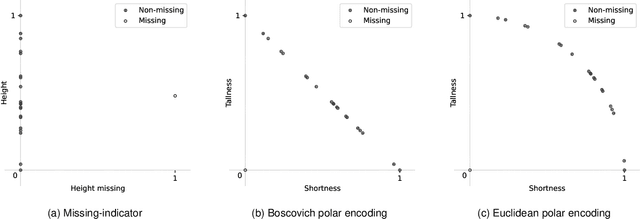
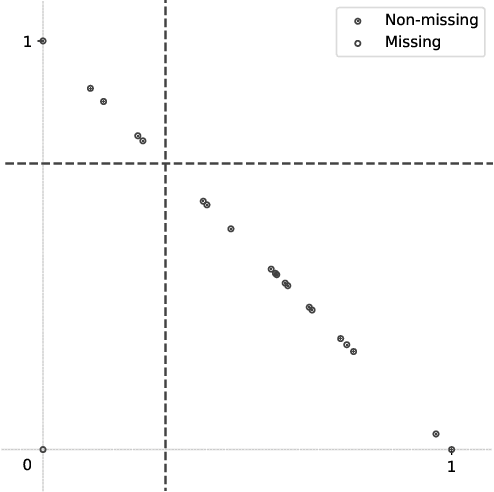
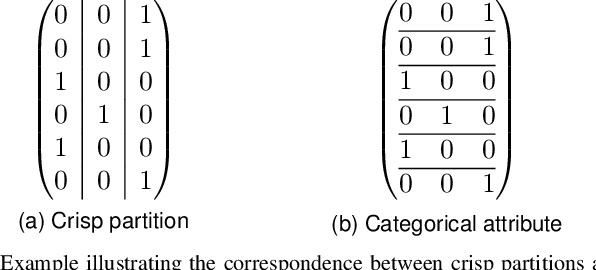
We propose polar encoding, a representation of categorical and numerical $[0,1]$-valued attributes with missing values that preserves the information encoded in the distribution of the missing values. Unlike the existing missing-indicator approach, this does not require imputation. We support our proposal with three different arguments. Firstly, polar encoding ensures that missing values become equidistant from all non-missing values by mapping the latter onto the unit circle. Secondly, polar encoding lets decision trees choose how missing values should be split, providing a practical realisation of the missingness incorporated in attributes (MIA) proposal. And lastly, polar encoding corresponds to the normalised representation of categorical and $[0,1]$-valued attributes when viewed as barycentric attributes, a new concept based on traditional barycentric coordinates. In particular, we show that barycentric attributes are fuzzified categorical attributes, that their normalised representation generalises one-hot encoding, and that the polar encoding of $[0, 1]$-valued attributes is analogous to the one-hot encoding of binary attributes. With an experiment based on twenty real-life datasets with missing values, we show that polar encoding performs about as well or better than the missing-indicator approach in terms of the resulting classification performance.
No imputation without representation
Jun 28, 2022
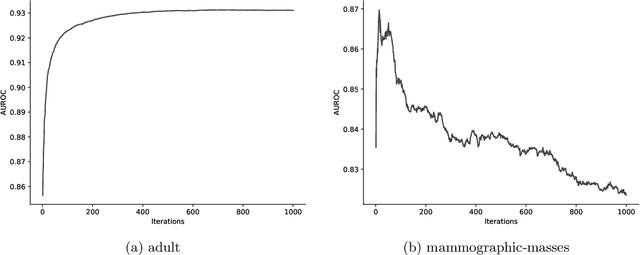
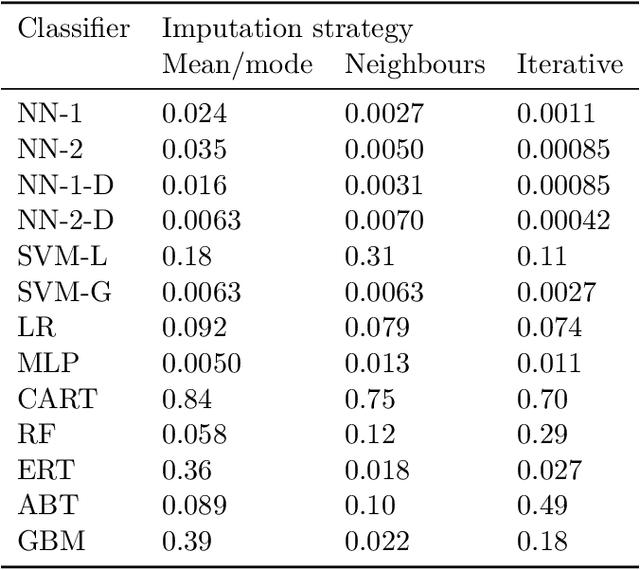
By filling in missing values in datasets, imputation allows these datasets to be used with algorithms that cannot handle missing values by themselves. However, missing values may in principle contribute useful information that is lost through imputation. The missing-indicator approach can be used in combination with imputation to instead represent this information as a part of the dataset. There are several theoretical considerations why missing-indicators may or may not be beneficial, but there has not been any large-scale practical experiment on real-life datasets to test this question for machine learning predictions. We perform this experiment for three imputation strategies and a range of different classification algorithms, on the basis of twenty real-life datasets. We find that on these datasets, missing-indicators generally increase classification performance. In addition, we find no evidence for most algorithms that nearest neighbour and iterative imputation lead to better performance than simple mean/mode imputation. Therefore, we recommend the use of missing-indicators with mean/mode imputation as a safe default, with the caveat that for decision trees, pruning is necessary to prevent overfitting. In a follow-up experiment, we determine attribute-specific missingness thresholds for each classifier above which missing-indicators are more likely than not to increase classification performance, and observe that these thresholds are much lower for categorical than for numerical attributes. Finally, we argue that mean imputation of numerical attributes may preserve some of the information from missing values, and we show that in the absence of missing-indicators, it can similarly be useful to apply mean imputation to one-hot encoded categorical attributes instead of mode imputation.
Optimised one-class classification performance
Feb 04, 2021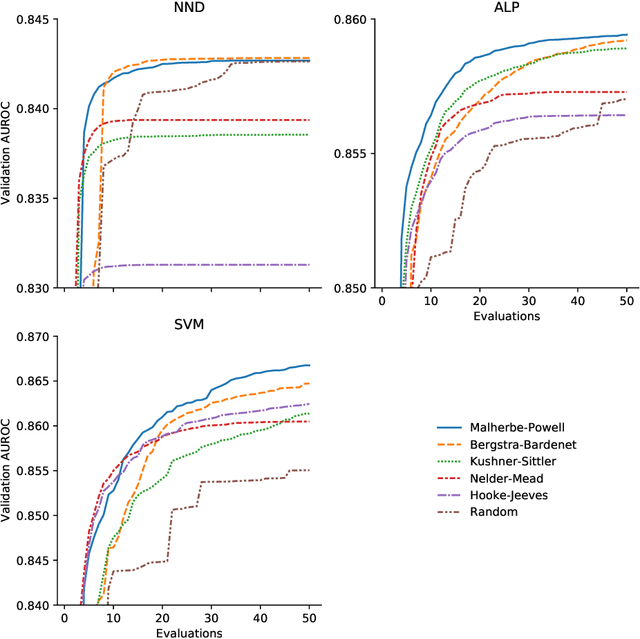

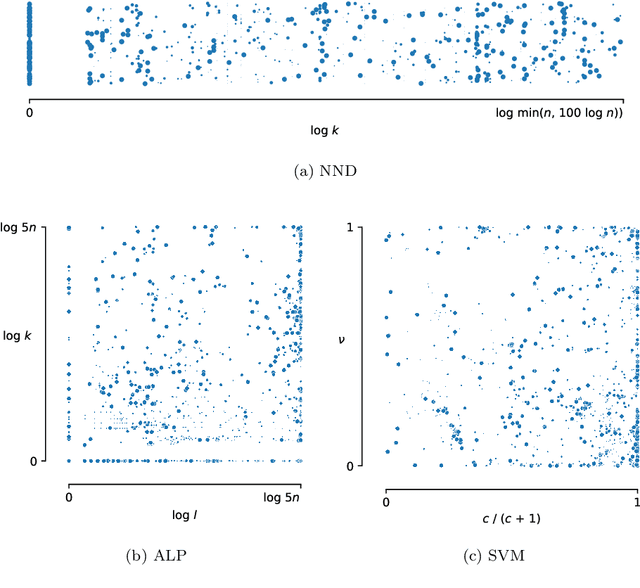
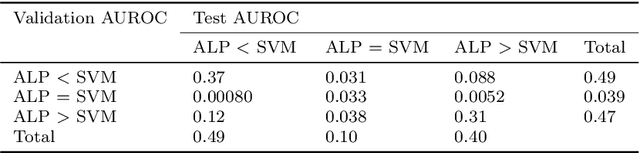
We provide a thorough treatment of hyperparameter optimisation for three data descriptors with a good track-record in the literature: Support Vector Machine (SVM), Nearest Neighbour Distance (NND) and Average Localised Proximity (ALP). The hyperparameters of SVM have to be optimised through cross-validation, while NND and ALP allow the reuse of a single nearest-neighbour query and an efficient form of leave-one-out validation. We experimentally evaluate the effect of hyperparameter optimisation with 246 classification problems drawn from 50 datasets. From a selection of optimisation algorithms, the recent Malherbe-Powell proposal optimises the hyperparameters of all three data descriptors most efficiently. We calculate the increase in test AUROC and the amount of overfitting as a function of the number of hyperparameter evaluations. After 50 evaluations, ALP and SVM both significantly outperform NND. The performance of ALP and SVM is comparable, but ALP can be optimised more efficiently, while a choice between ALP and SVM based on validation AUROC gives the best overall result. This distils the many variables of one-class classification with hyperparameter optimisation down to a clear choice with a known trade-off, allowing practitioners to make informed decisions.
Average Localised Proximity: a new data descriptor with good default one-class classification performance
Jan 26, 2021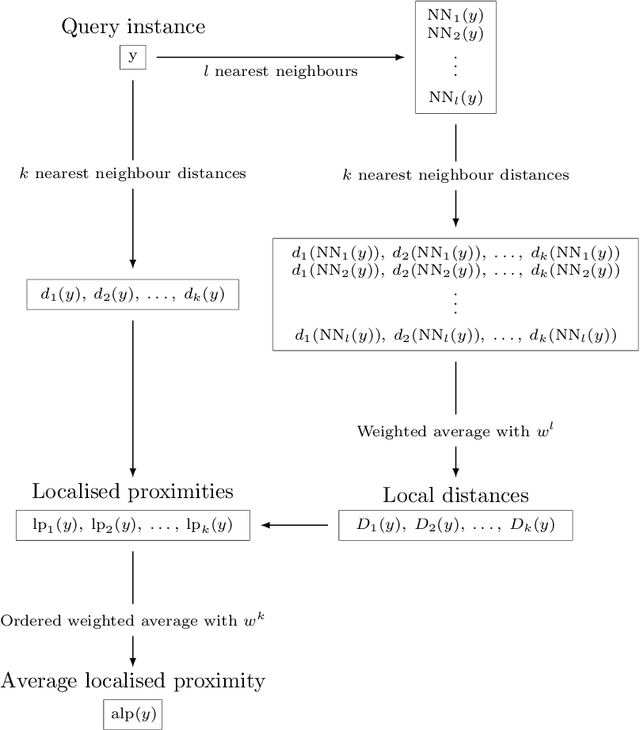
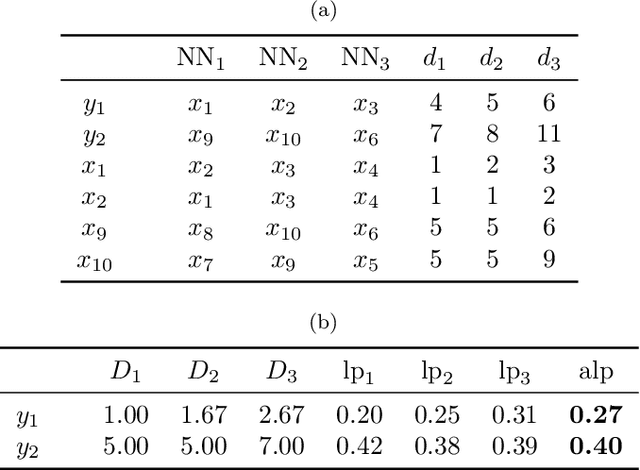

One-class classification is a challenging subfield of machine learning in which so-called data descriptors are used to predict membership of a class based solely on positive examples of that class, and no counter-examples. A number of data descriptors that have been shown to perform well in previous studies of one-class classification, like the Support Vector Machine (SVM), require setting one or more hyperparameters. There has been no systematic attempt to date to determine optimal default values for these hyperparameters, which limits their ease of use, especially in comparison with hyperparameter-free proposals like the Isolation Forest (IF). We address this issue by determining optimal default hyperparameter values across a collection of 246 one-class classification problems derived from 50 different real-world datasets. In addition, we propose a new data descriptor, Average Localised Proximity (ALP) to address certain issues with existing approaches based on nearest neighbour distances. Finally, we evaluate classification performance using a leave-one-dataset-out procedure, and find strong evidence that ALP outperforms IF and a number of other data descriptors, as well as weak evidence that it outperforms SVM, making ALP a good default choice.
On the use of convolutional neural networks for robust classification of multiple fingerprint captures
May 15, 2017



Fingerprint classification is one of the most common approaches to accelerate the identification in large databases of fingerprints. Fingerprints are grouped into disjoint classes, so that an input fingerprint is compared only with those belonging to the predicted class, reducing the penetration rate of the search. The classification procedure usually starts by the extraction of features from the fingerprint image, frequently based on visual characteristics. In this work, we propose an approach to fingerprint classification using convolutional neural networks, which avoid the necessity of an explicit feature extraction process by incorporating the image processing within the training of the classifier. Furthermore, such an approach is able to predict a class even for low-quality fingerprints that are rejected by commonly used algorithms, such as FingerCode. The study gives special importance to the robustness of the classification for different impressions of the same fingerprint, aiming to minimize the penetration in the database. In our experiments, convolutional neural networks yielded better accuracy and penetration rate than state-of-the-art classifiers based on explicit feature extraction. The tested networks also improved on the runtime, as a result of the joint optimization of both feature extraction and classification.