 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLexico-semantic and affective modelling of Spanish poetry: A semi-supervised learning approach
Sep 13, 2021
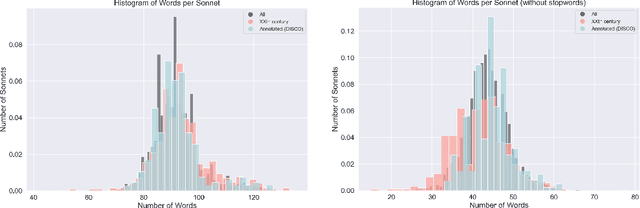

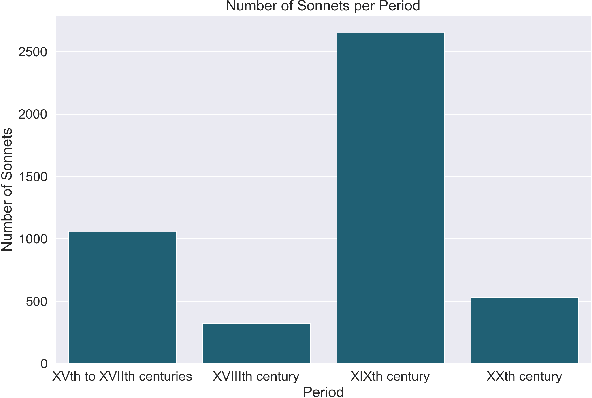
Text classification tasks have improved substantially during the last years by the usage of transformers. However, the majority of researches focus on prose texts, with poetry receiving less attention, specially for Spanish language. In this paper, we propose a semi-supervised learning approach for inferring 21 psychological categories evoked by a corpus of 4572 sonnets, along with 10 affective and lexico-semantic multiclass ones. The subset of poems used for training an evaluation includes 270 sonnets. With our approach, we achieve an AUC beyond 0.7 for 76% of the psychological categories, and an AUC over 0.65 for 60% on the multiclass ones. The sonnets are modelled using transformers, through sentence embeddings, along with lexico-semantic and affective features, obtained by using external lexicons. Consequently, we see that this approach provides an AUC increase of up to 0.12, as opposed to using transformers alone.
Vehicle Fuel Optimization Under Real-World Driving Conditions: An Explainable Artificial Intelligence Approach
Jul 22, 2021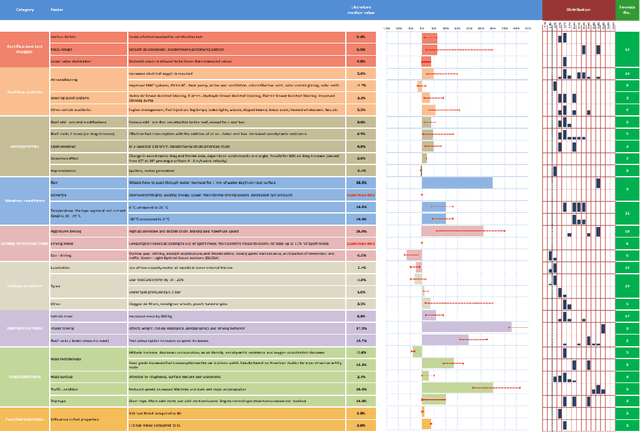
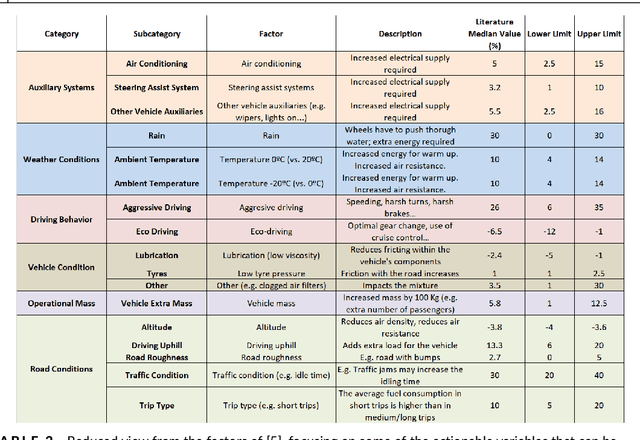
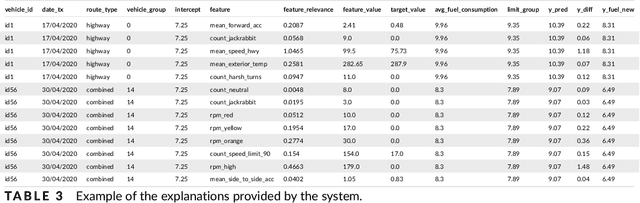

Fuel optimization of diesel and petrol vehicles within industrial fleets is critical for mitigating costs and reducing emissions. This objective is achievable by acting on fuel-related factors, such as the driving behaviour style. In this study, we developed an Explainable Boosting Machine (EBM) model to predict fuel consumption of different types of industrial vehicles, using real-world data collected from 2020 to 2021. This Machine Learning model also explains the relationship between the input factors and fuel consumption, quantifying the individual contribution of each one of them. The explanations provided by the model are compared with domain knowledge in order to see if they are aligned. The results show that the 70% of the categories associated to the fuel-factors are similar to the previous literature. With the EBM algorithm, we estimate that optimizing driving behaviour decreases fuel consumption between 12% and 15% in a large fleet (more than 1000 vehicles).
Anomaly detection in average fuel consumption with XAI techniques for dynamic generation of explanations
Nov 05, 2020



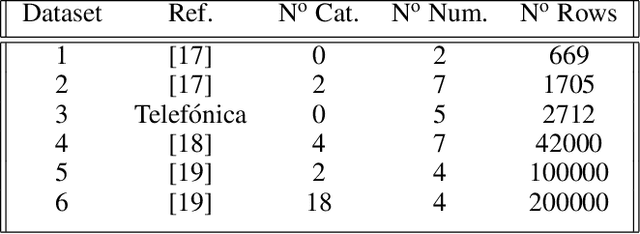
In this paper we show a complete process for unsupervised anomaly detection for the average fuel consumption of fleet vehicles that is able to explain what variables are affecting the consumption in terms of feature relevance. For doing that, we combine the anomaly detection with a surrogate model that is able to provide that feature relevance. For this part, we evaluate both whitebox models from the literature, as well as novel variations over them, and blackbox models combined with local posthoc feature relevance techniques. The evaluation is done using real IoT data belonging to Telef\'onica, and is measured both in terms of model performance, as well as using Explainable AI metrics that compare the explanations generated in terms representativeness, fidelity, stability and contrastiveness. The explanations generate counterfactual recommendations that show what could have been done to reduce the average fuel consumption of a vehicle and turn it into an inlier. The procedure is combined with domain knowledge expressed in business rules, and is able to adequate the type of explanations depending on the target user profile.
DISCO PAL: Diachronic Spanish Sonnet Corpus with Psychological and Affective Labels
Jul 09, 2020
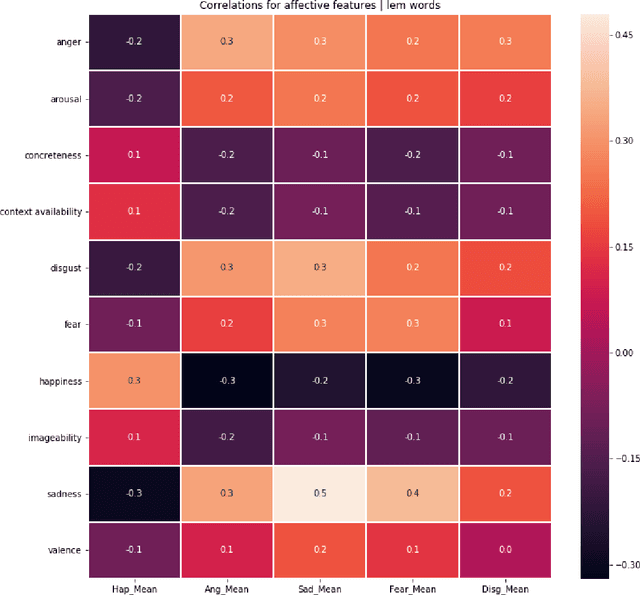
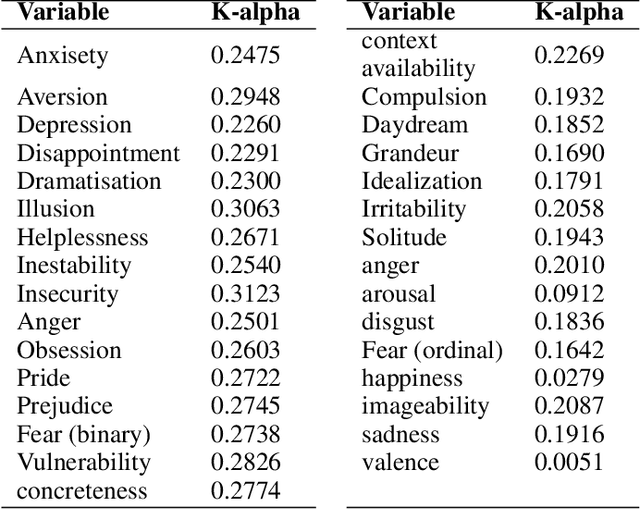
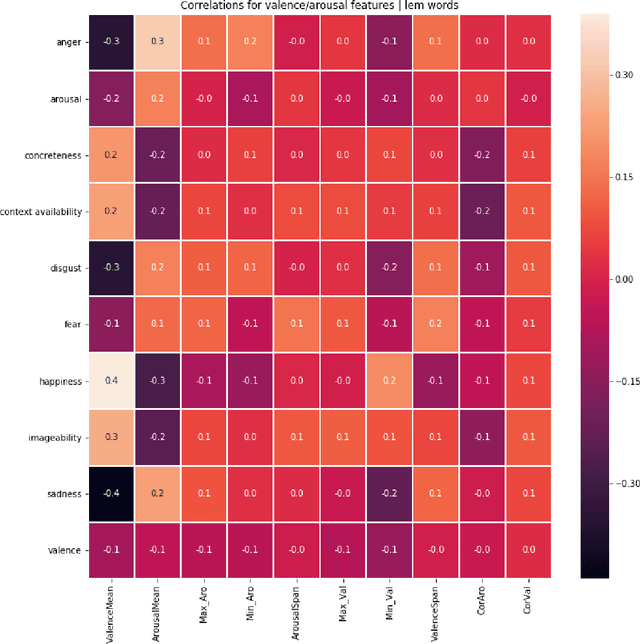
Nowadays, there are many applications of text mining over corpus from different languages, such as using supervised machine learning in order to predict labels associated to a text using as predictors features derived from the text itself. However, most of these applications are based on texts in prose, with a lack of applications that work with poetry texts. An example of application of text mining in poetry is the usage of features derived from their individual word in order to capture the lexical, sublexical and interlexical meaning, and infer the General Affective Meaning (GAM) of the text. However, though this proposal has been proved as useful for poetry in some languages, there is a lack of studies for both Spanish poetry and for highly-structured poetic compositions such as sonnets. This article presents a study over a labeled corpus of Spanish sonnets, in order to analyse if it is possible to build features from their individual words in order to predict their GAM. The purpose of this is to model sonnets at an affective level. The article also analyses the relationship between the GAM of the sonnets and the content itself. For this, we consider the content from a psychological perspective, identifying with tags when a sonnet is related to a specific term (p.e, when the sonnet's content is related to "daydream"). Then, we study how the GAM changes according to each of those psychological terms. The corpus contains 230 Spanish sonnets from authors of different centuries, from 15th to 19th. This corpus was annotated by different domain experts. The experts annotated the poems with affective features, as well as with domain concepts that belong to psychology. Thanks to this, the corpora of sonnets can be used in different applications, such as poetry recommender systems, personality text mining studies of the authors, or the usage of poetry for therapeutic purposes.
Rule Extraction in Unsupervised Anomaly Detection for Model Explainability: Application to OneClass SVM
Nov 21, 2019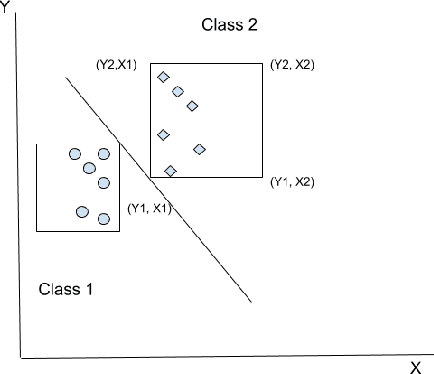
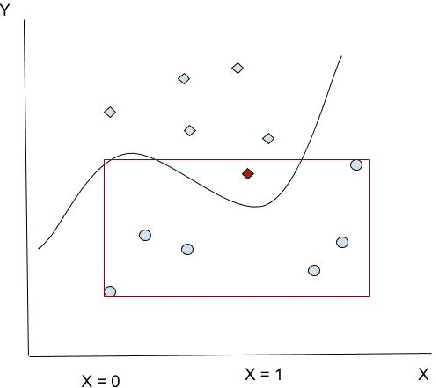
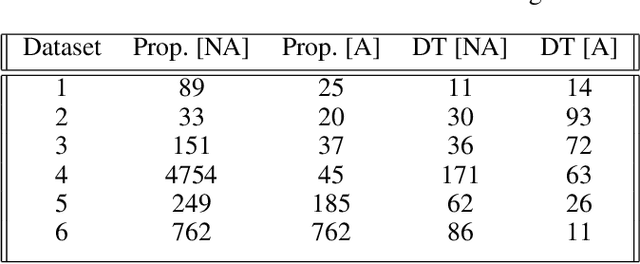
OneClass SVM is a popular method for unsupervised anomaly detection. As many other methods, it suffers from the \textit{black box} problem: it is difficult to justify, in an intuitive and simple manner, why the decision frontier is identifying data points as anomalous or non anomalous. Such type of problem is being widely addressed for supervised models. However, it is still an uncharted area for unsupervised learning. In this paper, we describe a method to infer rules that justify why a point is labelled as an anomaly, so as to obtain intuitive explanations for models created using the OneClass SVM algorithm. We evaluate our proposal with different datasets, including real-world data coming from industry. With this, our proposal contributes to extend Explainable AI techniques to unsupervised machine learning models.
Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI
Oct 22, 2019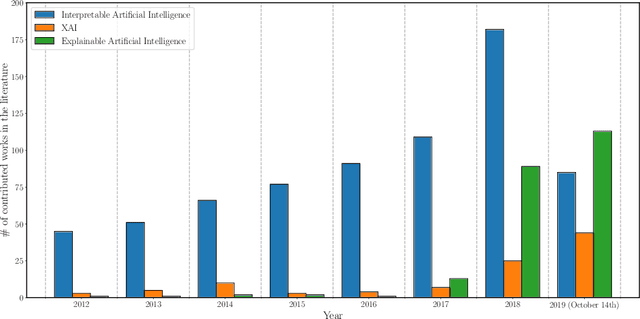
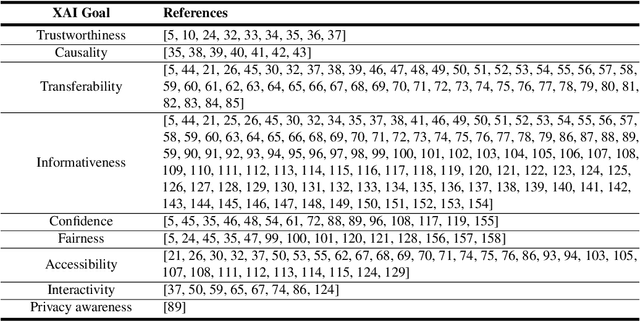
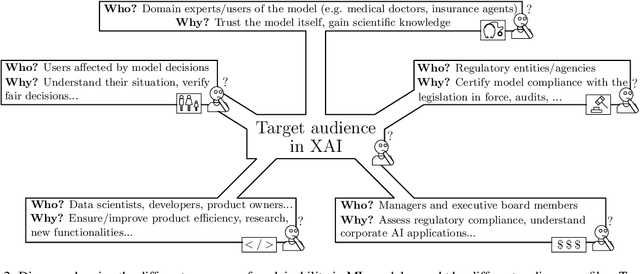

In the last years, Artificial Intelligence (AI) has achieved a notable momentum that may deliver the best of expectations over many application sectors across the field. For this to occur, the entire community stands in front of the barrier of explainability, an inherent problem of AI techniques brought by sub-symbolism (e.g. ensembles or Deep Neural Networks) that were not present in the last hype of AI. Paradigms underlying this problem fall within the so-called eXplainable AI (XAI) field, which is acknowledged as a crucial feature for the practical deployment of AI models. This overview examines the existing literature in the field of XAI, including a prospect toward what is yet to be reached. We summarize previous efforts to define explainability in Machine Learning, establishing a novel definition that covers prior conceptual propositions with a major focus on the audience for which explainability is sought. We then propose and discuss about a taxonomy of recent contributions related to the explainability of different Machine Learning models, including those aimed at Deep Learning methods for which a second taxonomy is built. This literature analysis serves as the background for a series of challenges faced by XAI, such as the crossroads between data fusion and explainability. Our prospects lead toward the concept of Responsible Artificial Intelligence, namely, a methodology for the large-scale implementation of AI methods in real organizations with fairness, model explainability and accountability at its core. Our ultimate goal is to provide newcomers to XAI with a reference material in order to stimulate future research advances, but also to encourage experts and professionals from other disciplines to embrace the benefits of AI in their activity sectors, without any prior bias for its lack of interpretability.