 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISCO PAL: Diachronic Spanish Sonnet Corpus with Psychological and Affective Labels
Paper and Code
Jul 09, 2020
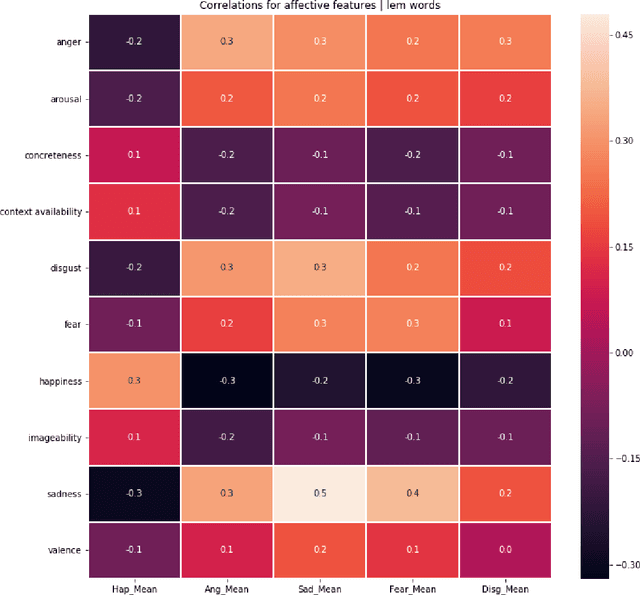
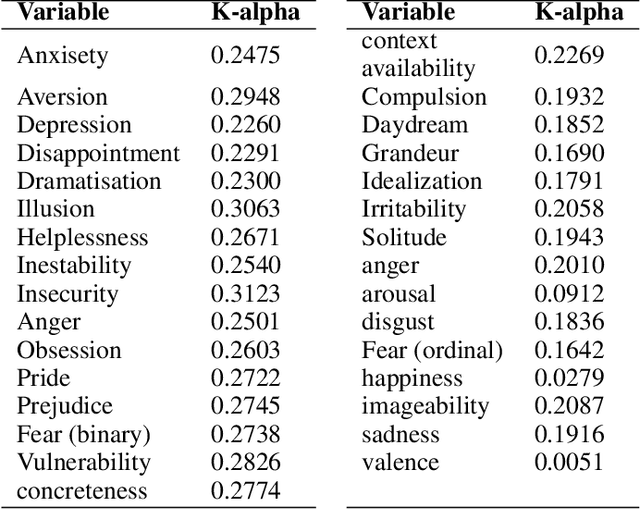
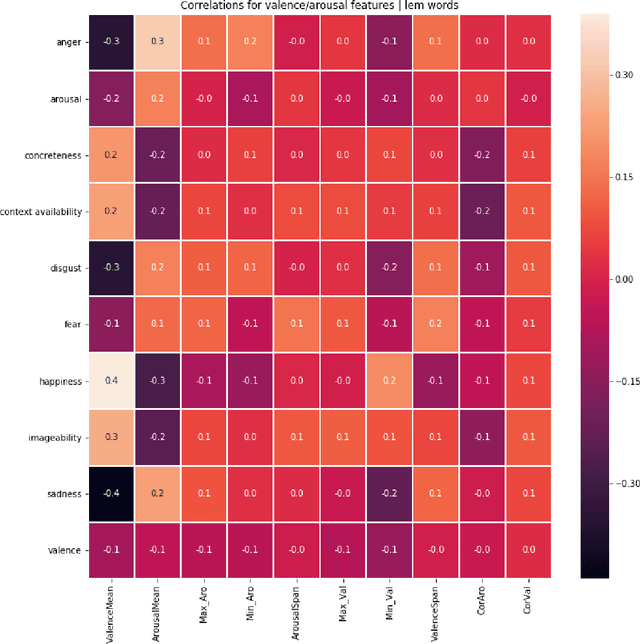
Nowadays, there are many applications of text mining over corpus from different languages, such as using supervised machine learning in order to predict labels associated to a text using as predictors features derived from the text itself. However, most of these applications are based on texts in prose, with a lack of applications that work with poetry texts. An example of application of text mining in poetry is the usage of features derived from their individual word in order to capture the lexical, sublexical and interlexical meaning, and infer the General Affective Meaning (GAM) of the text. However, though this proposal has been proved as useful for poetry in some languages, there is a lack of studies for both Spanish poetry and for highly-structured poetic compositions such as sonnets. This article presents a study over a labeled corpus of Spanish sonnets, in order to analyse if it is possible to build features from their individual words in order to predict their GAM. The purpose of this is to model sonnets at an affective level. The article also analyses the relationship between the GAM of the sonnets and the content itself. For this, we consider the content from a psychological perspective, identifying with tags when a sonnet is related to a specific term (p.e, when the sonnet's content is related to "daydream"). Then, we study how the GAM changes according to each of those psychological terms. The corpus contains 230 Spanish sonnets from authors of different centuries, from 15th to 19th. This corpus was annotated by different domain experts. The experts annotated the poems with affective features, as well as with domain concepts that belong to psychology. Thanks to this, the corpora of sonnets can be used in different applications, such as poetry recommender systems, personality text mining studies of the authors, or the usage of poetry for therapeutic purposes.