 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyricSIM: A novel Dataset and Benchmark for Similarity Detection in Spanish Song LyricS
Jun 02, 2023In this paper, we present a new dataset and benchmark tailored to the task of semantic similarity in song lyrics. Our dataset, originally consisting of 2775 pairs of Spanish songs, was annotated in a collective annotation experiment by 63 native annotators. After collecting and refining the data to ensure a high degree of consensus and data integrity, we obtained 676 high-quality annotated pairs that were used to evaluate the performance of various state-of-the-art monolingual and multilingual language models. Consequently, we established baseline results that we hope will be useful to the community in all future academic and industrial applications conducted in this context.
DISCO PAL: Diachronic Spanish Sonnet Corpus with Psychological and Affective Labels
Jul 09, 2020
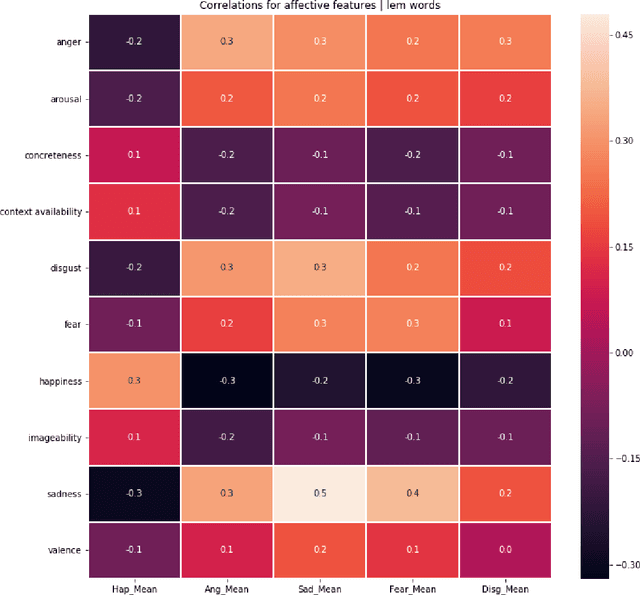
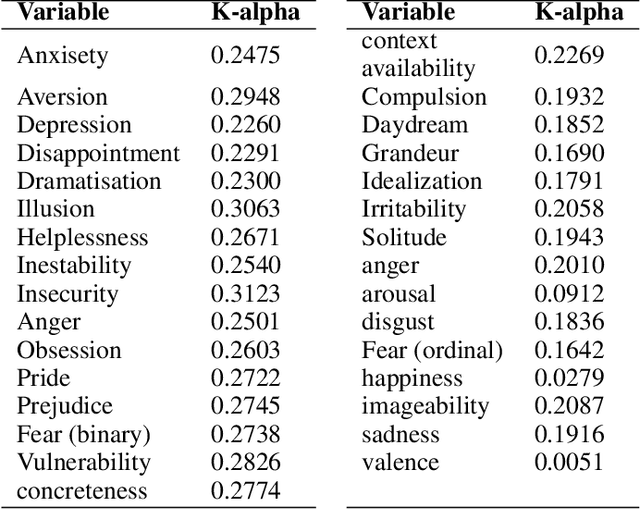
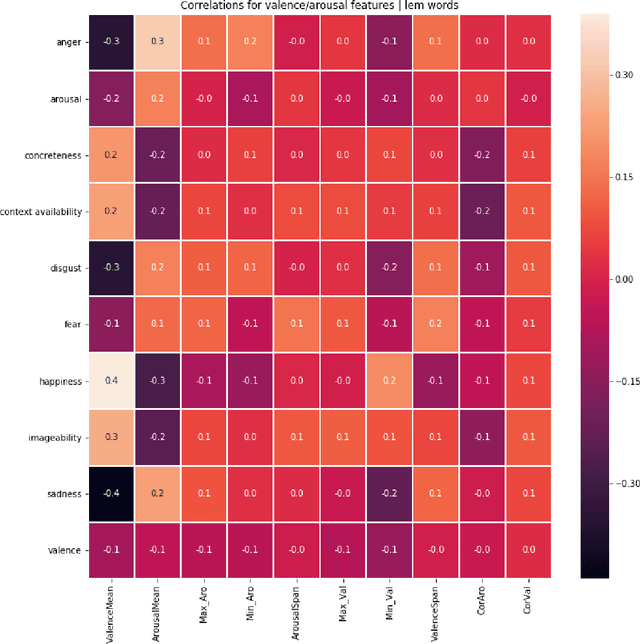
Nowadays, there are many applications of text mining over corpus from different languages, such as using supervised machine learning in order to predict labels associated to a text using as predictors features derived from the text itself. However, most of these applications are based on texts in prose, with a lack of applications that work with poetry texts. An example of application of text mining in poetry is the usage of features derived from their individual word in order to capture the lexical, sublexical and interlexical meaning, and infer the General Affective Meaning (GAM) of the text. However, though this proposal has been proved as useful for poetry in some languages, there is a lack of studies for both Spanish poetry and for highly-structured poetic compositions such as sonnets. This article presents a study over a labeled corpus of Spanish sonnets, in order to analyse if it is possible to build features from their individual words in order to predict their GAM. The purpose of this is to model sonnets at an affective level. The article also analyses the relationship between the GAM of the sonnets and the content itself. For this, we consider the content from a psychological perspective, identifying with tags when a sonnet is related to a specific term (p.e, when the sonnet's content is related to "daydream"). Then, we study how the GAM changes according to each of those psychological terms. The corpus contains 230 Spanish sonnets from authors of different centuries, from 15th to 19th. This corpus was annotated by different domain experts. The experts annotated the poems with affective features, as well as with domain concepts that belong to psychology. Thanks to this, the corpora of sonnets can be used in different applications, such as poetry recommender systems, personality text mining studies of the authors, or the usage of poetry for therapeutic purposes.
Using Fuzzy Logic to Leverage HTML Markup for Web Page Representation
Jun 14, 2016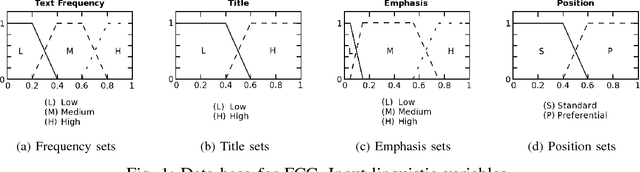
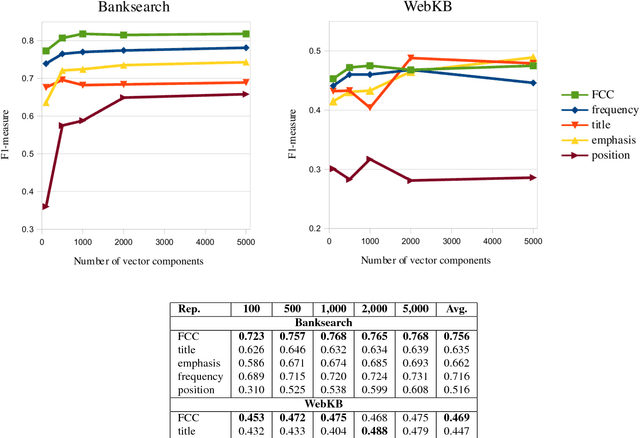
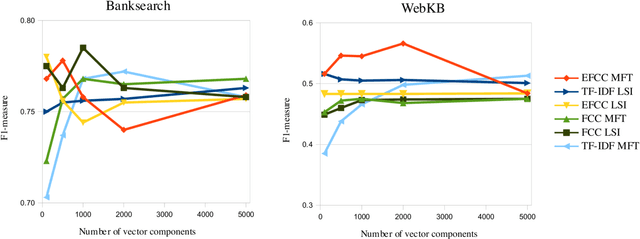
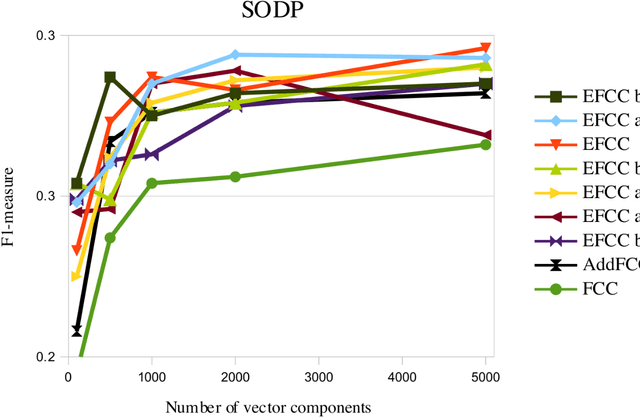
The selection of a suitable document representation approach plays a crucial role in the performance of a document clustering task. Being able to pick out representative words within a document can lead to substantial improvements in document clustering. In the case of web documents, the HTML markup that defines the layout of the content provides additional structural information that can be further exploited to identify representative words. In this paper we introduce a fuzzy term weighing approach that makes the most of the HTML structure for document clustering. We set forth and build on the hypothesis that a good representation can take advantage of how humans skim through documents to extract the most representative words. The authors of web pages make use of HTML tags to convey the most important message of a web page through page elements that attract the readers' attention, such as page titles or emphasized elements. We define a set of criteria to exploit the information provided by these page elements, and introduce a fuzzy combination of these criteria that we evaluate within the context of a web page clustering task. Our proposed approach, called Abstract Fuzzy Combination of Criteria (AFCC), can adapt to datasets whose features are distributed differently, achieving good results compared to other similar fuzzy logic based approaches and TF-IDF across different datasets.
Real-Time Classification of Twitter Trends
Mar 06, 2014
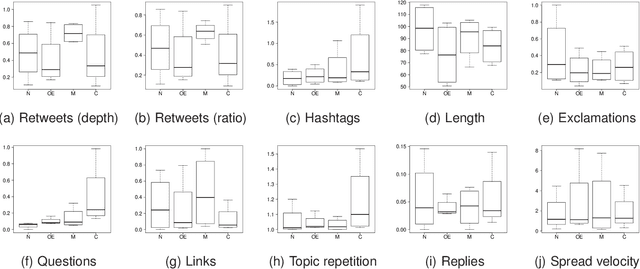
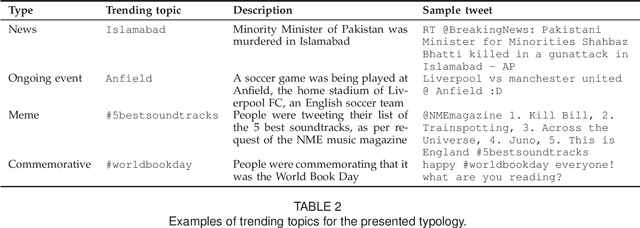
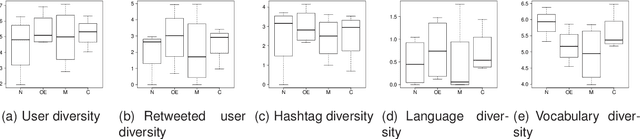
Social media users give rise to social trends as they share about common interests, which can be triggered by different reasons. In this work, we explore the types of triggers that spark trends on Twitter, introducing a typology with following four types: 'news', 'ongoing events', 'memes', and 'commemoratives'. While previous research has analyzed trending topics in a long term, we look at the earliest tweets that produce a trend, with the aim of categorizing trends early on. This would allow to provide a filtered subset of trends to end users. We analyze and experiment with a set of straightforward language-independent features based on the social spread of trends to categorize them into the introduced typology. Our method provides an efficient way to accurately categorize trending topics without need of external data, enabling news organizations to discover breaking news in real-time, or to quickly identify viral memes that might enrich marketing decisions, among others. The analysis of social features also reveals patterns associated with each type of trend, such as tweets about ongoing events being shorter as many were likely sent from mobile devices, or memes having more retweets originating from a few trend-setters.