 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Segmentation of Neuronal Nuclei and Cell-Type Identification using Multi-channel Information
Oct 04, 2024


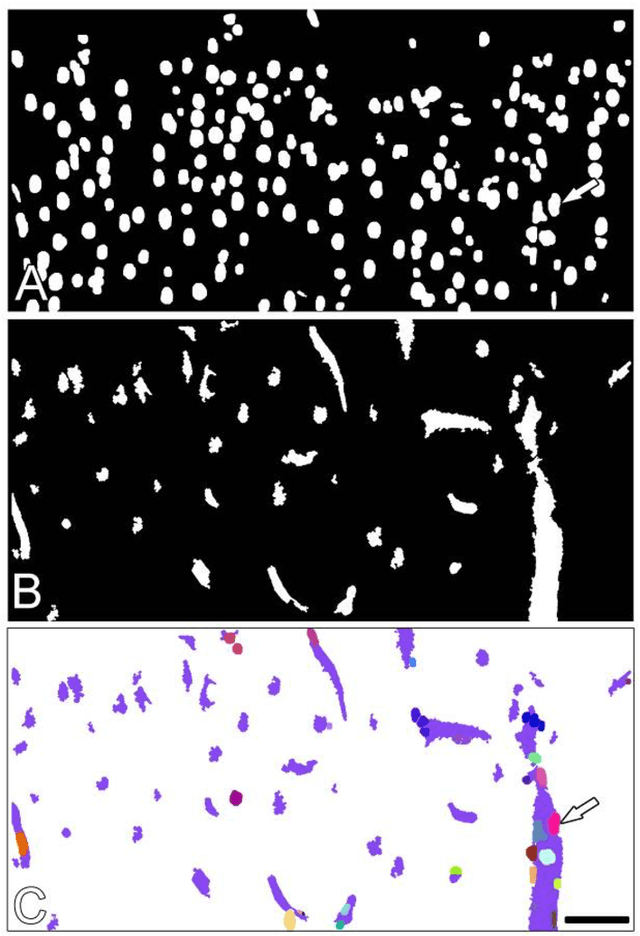
Background Analyzing images to accurately estimate the number of different cell types in the brain using automatic methods is a major objective in neuroscience. The automatic and selective detection and segmentation of neurons would be an important step in neuroanatomical studies. New method We present a method to improve the 3D reconstruction of neuronal nuclei that allows their segmentation, excluding the nuclei of non-neuronal cell types. Results We have tested the algorithm on stacks of images from rat neocortex, in a complex scenario (large stacks of images, uneven staining, and three different channels to visualize different cellular markers). It was able to provide a good identification ratio of neuronal nuclei and a 3D segmentation. Comparison with Existing Methods: Many automatic tools are in fact currently available, but different methods yield different cell count estimations, even in the same brain regions, due to differences in the labeling and imaging techniques, as well as in the algorithms used to detect cells. Moreover, some of the available automated software methods have provided estimations of cell numbers that have been reported to be inaccurate or inconsistent after evaluation by neuroanatomists. Conclusions It is critical to have a tool for automatic segmentation that allows discrimination between neurons, glial cells and perivascular cells. It would greatly speed up a task that is currently performed manually and would allow the cell counting to be systematic, avoiding human bias. Furthermore, the resulting 3D reconstructions of different cell types can be used to generate models of the spatial distribution of cells.
A Tutorial on the Design, Experimentation and Application of Metaheuristic Algorithms to Real-World Optimization Problems
Oct 04, 2024



In the last few years, the formulation of real-world optimization problems and their efficient solution via metaheuristic algorithms has been a catalyst for a myriad of research studies. In spite of decades of historical advancements on the design and use of metaheuristics, large difficulties still remain in regards to the understandability, algorithmic design uprightness, and performance verifiability of new technical achievements. A clear example stems from the scarce replicability of works dealing with metaheuristics used for optimization, which is often infeasible due to ambiguity and lack of detail in the presentation of the methods to be reproduced. Additionally, in many cases, there is a questionable statistical significance of their reported results. This work aims at providing the audience with a proposal of good practices which should be embraced when conducting studies about metaheuristics methods used for optimization in order to provide scientific rigor, value and transparency. To this end, we introduce a step by step methodology covering every research phase that should be followed when addressing this scientific field. Specifically, frequently overlooked yet crucial aspects and useful recommendations will be discussed in regards to the formulation of the problem, solution encoding, implementation of search operators, evaluation metrics, design of experiments, and considerations for real-world performance, among others. Finally, we will outline important considerations, challenges, and research directions for the success of newly developed optimization metaheuristics in their deployment and operation over real-world application environments.
Comparative study of regression vs pairwise models for surrogate-based heuristic optimisation
Oct 04, 2024Heuristic optimisation algorithms explore the search space by sampling solutions, evaluating their fitness, and biasing the search in the direction of promising solutions. However, in many cases, this fitness function involves executing expensive computational calculations, drastically reducing the reasonable number of evaluations. In this context, surrogate models have emerged as an excellent alternative to alleviate these computational problems. This paper addresses the formulation of surrogate problems as both regression models that approximate fitness (surface surrogate models) and a novel way to connect classification models (pairwise surrogate models). The pairwise approach can be directly exploited by some algorithms, such as Differential Evolution, in which the fitness value is not actually needed to drive the search, and it is sufficient to know whether a solution is better than another one or not. Based on these modelling approaches, we have conducted a multidimensional analysis of surrogate models under different configurations: different machine learning algorithms (regularised regression, neural networks, decision trees, boosting methods, and random forests), different surrogate strategies (encouraging diversity or relaxing prediction thresholds), and compare them for both surface and pairwise surrogate models. The experimental part of the article includes the benchmark problems already proposed for the SOCO2011 competition in continuous optimisation and a simulation problem included in the recent GECCO2021 Industrial Challenge. This paper shows that the performance of the overall search, when using online machine learning-based surrogate models, depends not only on the accuracy of the predictive model but also on both the kind of bias towards positive or negative cases and how the optimisation uses those predictions to decide whether to execute the actual fitness function.
Fairness in Bio-inspired Optimization Research: A Prescription of Methodological Guidelines for Comparing Meta-heuristics
Apr 19, 2020
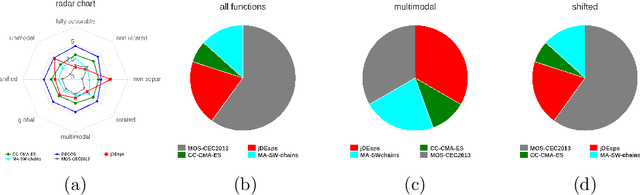
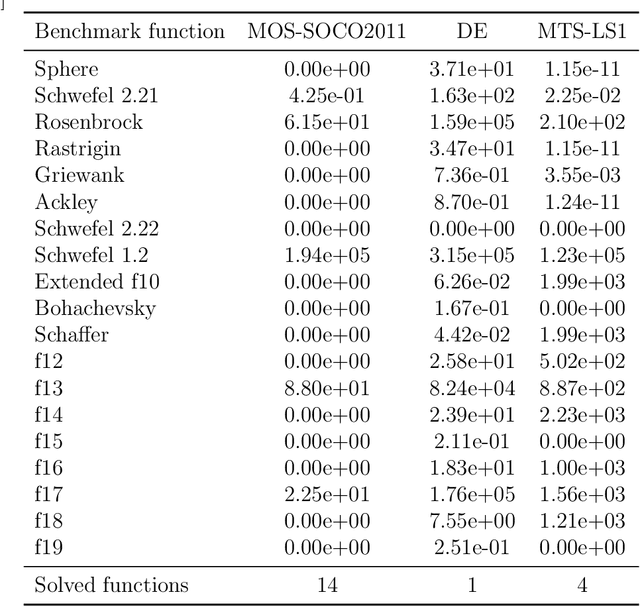
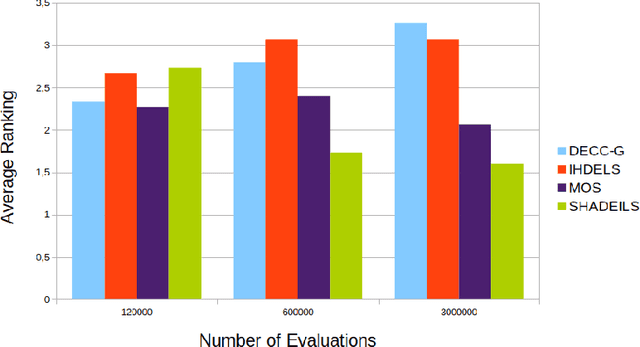
Bio-inspired optimization (including Evolutionary Computation and Swarm Intelligence) is a growing research topic with many competitive bio-inspired algorithms being proposed every year. In such an active area, preparing a successful proposal of a new bio-inspired algorithm is not an easy task. Given the maturity of this research field, proposing a new optimization technique with innovative elements is no longer enough. Apart from the novelty, results reported by the authors should be proven to achieve a significant advance over previous outcomes from the state of the art. Unfortunately, not all new proposals deal with this requirement properly. Some of them fail to select an appropriate benchmark or reference algorithms to compare with. In other cases, the validation process carried out is not defined in a principled way (or is even not done at all). Consequently, the significance of the results presented in such studies cannot be guaranteed. In this work we review several recommendations in the literature and propose methodological guidelines to prepare a successful proposal, taking all these issues into account. We expect these guidelines to be useful not only for authors, but also for reviewers and editors along their assessment of new contributions to the field.