 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiLM-Based Speaker Conditioning of a SpeechLLM for Pathological Speech Recognition
Jun 04, 2026Automatic speech recognition (ASR) has advanced remarkably for standard speech; however, pathological speech from neurological conditions remains a significant challenge. We investigate speaker conditioning via Feature-wise Linear Modulation (FiLM), injecting x-vector-derived information into each transformer layer of a frozen ASR encoder to adapt internal representations to individual pathological speakers without modifying base model weights. We benchmark this for the ASR task against standard and parameter-efficient fine-tuning baselines, complemented by post-processing, on Spanish and English pathological speech. Additionally, we evaluate if the adapted model preserves the ability to answer speech-related questions. Results show that speaker-conditioned ASR is competitive with established adaptation strategies while retaining performance on non-conditioned speech.
"OK Aura, Be Fair With Me": Demographics-Agnostic Training for Bias Mitigation in Wake-up Word Detection
Apr 07, 2026Voice-based interfaces are widely used; however, achieving fair Wake-up Word detection across diverse speaker populations remains a critical challenge due to persistent demographic biases. This study evaluates the effectiveness of demographics-agnostic training techniques in mitigating performance disparities among speakers of varying sex, age, and accent. We utilize the OK Aura database for our experiments, employing a training methodology that excludes demographic labels, which are reserved for evaluation purposes. We explore (i) data augmentation techniques to enhance model generalization and (ii) knowledge distillation of pre-trained foundational speech models. The experimental results indicate that these demographics-agnostic training techniques markedly reduce demographic bias, leading to a more equitable performance profile across different speaker groups. Specifically, one of the evaluated techniques achieves a Predictive Disparity reduction of 39.94\% for sex, 83.65\% for age, and 40.48\% for accent when compared to the baseline. This study highlights the effectiveness of label-agnostic methodologies in fostering fairness in Wake-up Word detection.
Robustness assessment of large audio language models in multiple-choice evaluation
Oct 06, 2025



Recent advances in large audio language models (LALMs) have primarily been assessed using a multiple-choice question answering (MCQA) framework. However, subtle changes, such as shifting the order of choices, result in substantially different results. Existing MCQA frameworks do not account for this variability and report a single accuracy number per benchmark or category. We dive into the MCQA evaluation framework and conduct a systematic study spanning three benchmarks (MMAU, MMAR and MMSU) and four models: Audio Flamingo 2, Audio Flamingo 3, Qwen2.5-Omni-7B-Instruct, and Kimi-Audio-7B-Instruct. Our findings indicate that models are sensitive not only to the ordering of choices, but also to the paraphrasing of the question and the choices. Finally, we propose a simpler evaluation protocol and metric that account for subtle variations and provide a more detailed evaluation report of LALMs within the MCQA framework.
Robust Wake-Up Word Detection by Two-stage Multi-resolution Ensembles
Oct 17, 2023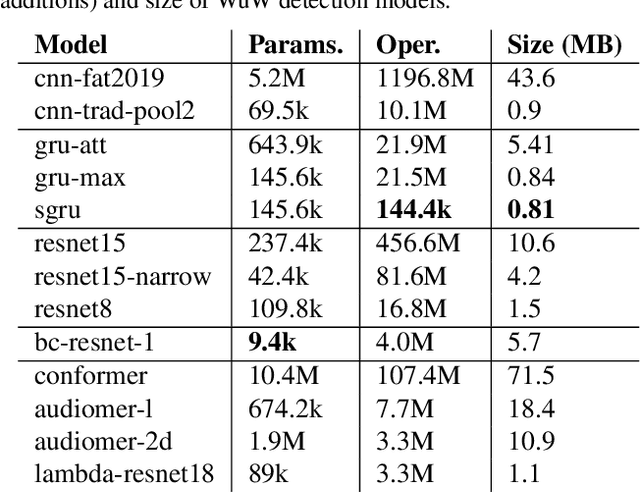
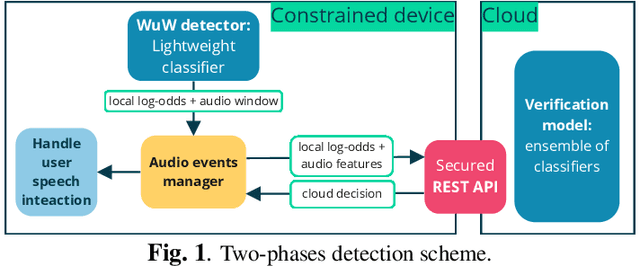
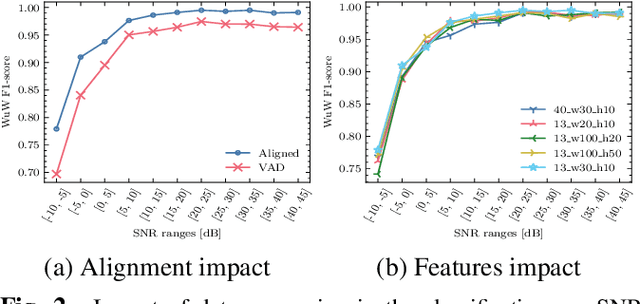
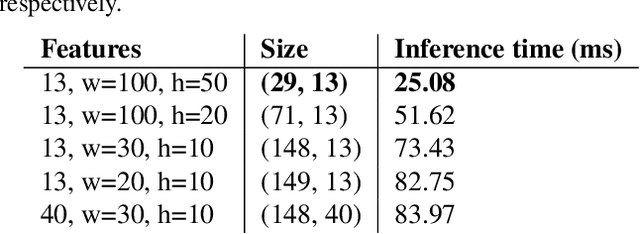
Voice-based interfaces rely on a wake-up word mechanism to initiate communication with devices. However, achieving a robust, energy-efficient, and fast detection remains a challenge. This paper addresses these real production needs by enhancing data with temporal alignments and using detection based on two phases with multi-resolution. It employs two models: a lightweight on-device model for real-time processing of the audio stream and a verification model on the server-side, which is an ensemble of heterogeneous architectures that refine detection. This scheme allows the optimization of two operating points. To protect privacy, audio features are sent to the cloud instead of raw audio. The study investigated different parametric configurations for feature extraction to select one for on-device detection and another for the verification model. Furthermore, thirteen different audio classifiers were compared in terms of performance and inference time. The proposed ensemble outperforms our stronger classifier in every noise condition.
Iterative pseudo-forced alignment by acoustic CTC loss for self-supervised ASR domain adaptation
Oct 27, 2022



High-quality data labeling from specific domains is costly and human time-consuming. In this work, we propose a self-supervised domain adaptation method, based upon an iterative pseudo-forced alignment algorithm. The produced alignments are employed to customize an end-to-end Automatic Speech Recognition (ASR) and iteratively refined. The algorithm is fed with frame-wise character posteriors produced by a seed ASR, trained with out-of-domain data, and optimized throughout a Connectionist Temporal Classification (CTC) loss. The alignments are computed iteratively upon a corpus of broadcast TV. The process is repeated by reducing the quantity of text to be aligned or expanding the alignment window until finding the best possible audio-text alignment. The starting timestamps, or temporal anchors, are produced uniquely based on the confidence score of the last aligned utterance. This score is computed with the paths of the CTC-alignment matrix. With this methodology, no human-revised text references are required. Alignments from long audio files with low-quality transcriptions, like TV captions, are filtered out by confidence score and ready for further ASR adaptation. The obtained results, on both the Spanish RTVE2022 and CommonVoice databases, underpin the feasibility of using CTC-based systems to perform: highly accurate audio-text alignments, domain adaptation and semi-supervised training of end-to-end ASR.
Speech Enhancement for Wake-Up-Word detection in Voice Assistants
Jan 29, 2021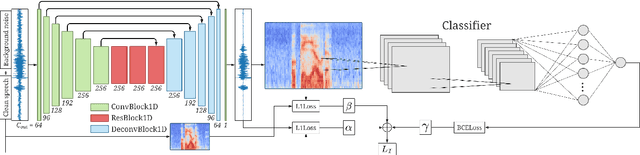
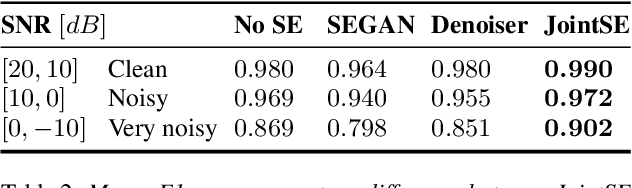
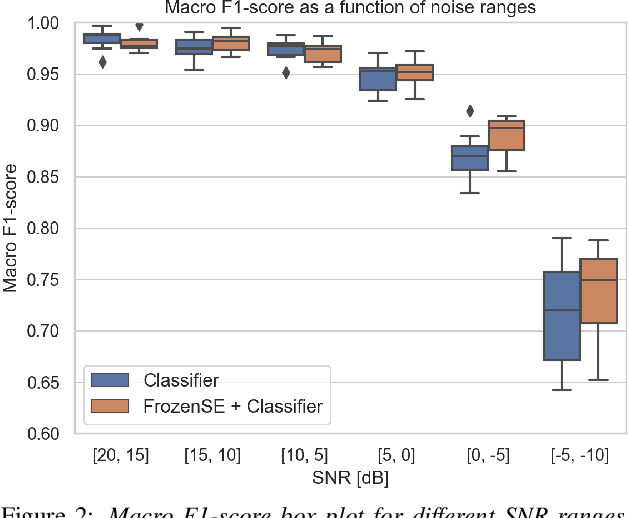
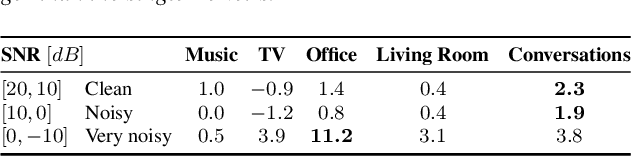
Keyword spotting and in particular Wake-Up-Word (WUW) detection is a very important task for voice assistants. A very common issue of voice assistants is that they get easily activated by background noise like music, TV or background speech that accidentally triggers the device. In this paper, we propose a Speech Enhancement (SE) model adapted to the task of WUW detection that aims at increasing the recognition rate and reducing the false alarms in the presence of these types of noises. The SE model is a fully-convolutional denoising auto-encoder at waveform level and is trained using a log-Mel Spectrogram and waveform reconstruction losses together with the BCE loss of a simple WUW classification network. A new database has been purposely prepared for the task of recognizing the WUW in challenging conditions containing negative samples that are very phonetically similar to the keyword. The database is extended with public databases and an exhaustive data augmentation to simulate different noises and environments. The results obtained by concatenating the SE with a simple and state-of-the-art WUW detectors show that the SE does not have a negative impact on the recognition rate in quiet environments while increasing the performance in the presence of noise, especially when the SE and WUW detector are trained jointly end-to-end.