 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Wake-Up Word Detection by Two-stage Multi-resolution Ensembles
Paper and Code
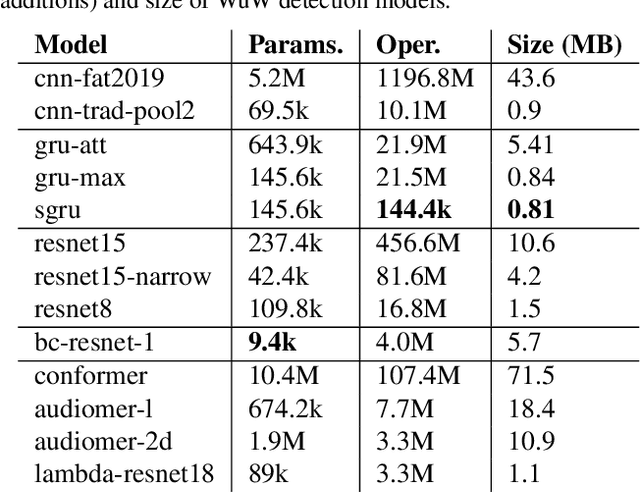
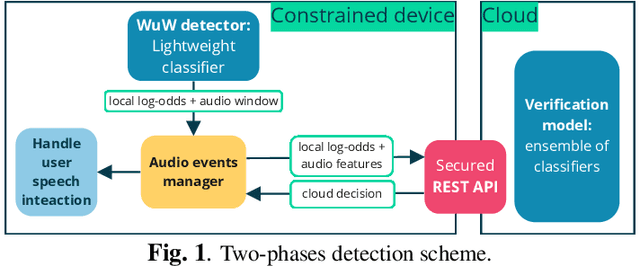
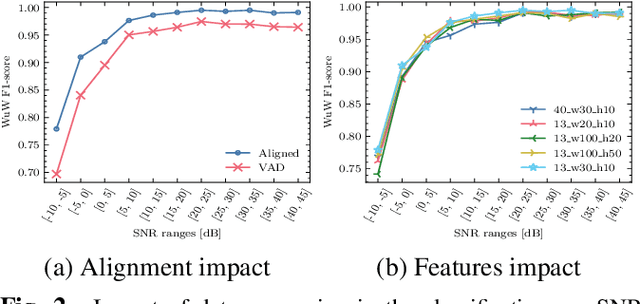
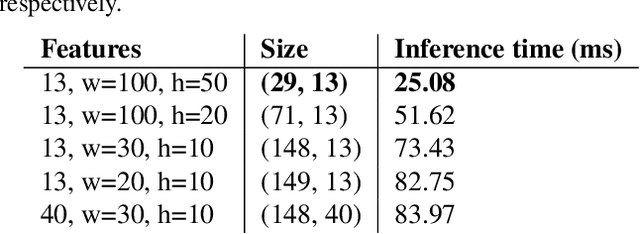
Voice-based interfaces rely on a wake-up word mechanism to initiate communication with devices. However, achieving a robust, energy-efficient, and fast detection remains a challenge. This paper addresses these real production needs by enhancing data with temporal alignments and using detection based on two phases with multi-resolution. It employs two models: a lightweight on-device model for real-time processing of the audio stream and a verification model on the server-side, which is an ensemble of heterogeneous architectures that refine detection. This scheme allows the optimization of two operating points. To protect privacy, audio features are sent to the cloud instead of raw audio. The study investigated different parametric configurations for feature extraction to select one for on-device detection and another for the verification model. Furthermore, thirteen different audio classifiers were compared in terms of performance and inference time. The proposed ensemble outperforms our stronger classifier in every noise condition.