 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Multiple-Choice Reading and Listening Comprehension Tests
Paper and Code
Jul 03, 2023

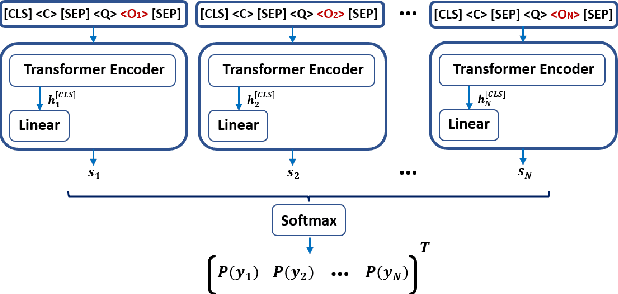
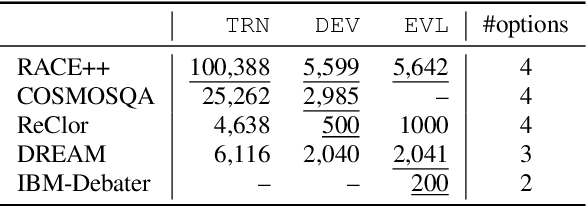
Multiple-choice reading and listening comprehension tests are an important part of language assessment. Content creators for standard educational tests need to carefully curate questions that assess the comprehension abilities of candidates taking the tests. However, recent work has shown that a large number of questions in general multiple-choice reading comprehension datasets can be answered without comprehension, by leveraging world knowledge instead. This work investigates how much of a contextual passage needs to be read in multiple-choice reading based on conversation transcriptions and listening comprehension tests to be able to work out the correct answer. We find that automated reading comprehension systems can perform significantly better than random with partial or even no access to the context passage. These findings offer an approach for content creators to automatically capture the trade-off between comprehension and world knowledge required for their proposed questions.