 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Knowledge to Action: Outcomes of the 2025 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
May 04, 2026Large language models (LLMs) are rapidly changing how researchers in materials science and chemistry discover, organize, and act on scientific knowledge. This paper analyzes a broad set of community-developed LLM applications in an effort to identify emerging patterns in how these systems can be used across the scientific research lifecycle. We organize the projects into two complementary categories: Knowledge Infrastructure, systems that structure, retrieve, synthesize, and validate scientific information; and Action Systems, systems that execute, coordinate, or automate scientific work across computational and experimental environments. The submissions reveal a shift from single-purpose LLM tools toward integrated, multi-agent workflows that combine retrieval, reasoning, tool use, and domain-specific validation. Prominent themes include retrieval-augmented generation as grounding infrastructure, persistent structured knowledge representations, multimodal and multilingual scientific inputs, and early progress toward laboratory-integrated closed-loop systems. Together, these results suggest that LLMs are evolving from general-purpose assistants into composable infrastructure for scientific reasoning and action. This work provides a community snapshot of that transition and a practical taxonomy for understanding emerging LLM-enabled workflows in materials science and chemistry.
Autonomous Multi-Agent AI for High-Throughput Polymer Informatics: From Property Prediction to Generative Design Across Synthetic and Bio-Polymers
Jan 25, 2026We present an integrated multiagent AI ecosystem for polymer discovery that unifies high-throughput materials workflows, artificial intelligence, and computational modeling within a single Polymer Research Lifecycle (PRL) pipeline. The system orchestrates specialized agents powered by state-of-the-art large language models (DeepSeek-V2 and DeepSeek-Coder) to retrieve and reason over scientific resources, invoke external tools, execute domain-specific code, and perform metacognitive self-assessment for robust end-to-end task execution. We demonstrate three practical capabilities: a high-fidelity polymer property prediction and generative design pipeline, a fully automated multimodal workflow for biopolymer structure characterization, and a metacognitive agent framework that can monitor performance and improve execution strategies over time. On a held-out test set of 1,251 polymers, our PolyGNN agent achieves strong predictive accuracy, reaching R2 = 0.89 for glass-transition temperature (Tg ), R2 = 0.82 for tensile strength, R2 = 0.75 for elongation, and R2 = 0.91 for density. The framework also provides uncertainty estimates via multiagent consensus and scales with linear complexity to at least 10,000 polymers, enabling high-throughput screening at low computational cost. For a representative workload, the system completes inference in 16.3 s using about 2 GB of memory and 0.1 GPU hours, at an estimated cost of about $0.08. On a dedicated Tg benchmark, our approach attains R2 = 0.78, outperforming strong baselines including single-LLM prediction (R2 = 0.67), group-contribution methods (R2 = 0.71), and ChemCrow (R2 = 0.66). We further demonstrate metacognitive control in a polystyrene case study, where the system not only produces domain-level scientific outputs but continually monitors and optimizes its own behavior through tactical, strategic, and meta-strategic self-assessment.
Quantum Error Mitigation with Attention Graph Transformers for Burgers Equation Solvers on NISQ Hardware
Dec 29, 2025We present a hybrid quantum-classical framework augmented with learned error mitigation for solving the viscous Burgers equation on noisy intermediate-scale quantum (NISQ) hardware. Using the Cole-Hopf transformation, the nonlinear Burgers equation is mapped to a diffusion equation, discretized on uniform grids, and encoded into a quantum state whose time evolution is approximated via Trotterized nearest-neighbor circuits implemented in Qiskit. Quantum simulations are executed on noisy Aer backends and IBM superconducting quantum devices and are benchmarked against high-accuracy classical solutions obtained using a Krylov-based solver applied to the corresponding discretized Hamiltonian. From measured quantum amplitudes, we reconstruct the velocity field and evaluate physical and numerical diagnostics, including the L2 error, shock location, and dissipation rate, both with and without zero-noise extrapolation (ZNE). To enable data-driven error mitigation, we construct a large parametric dataset by sweeping viscosity, time step, grid resolution, and boundary conditions, producing matched tuples of noisy, ZNE-corrected, hardware, and classical solutions together with detailed circuit metadata. Leveraging this dataset, we train an attention-based graph neural network that incorporates circuit structure, light-cone information, global circuit parameters, and noisy quantum outputs to predict error-mitigated solutions. Across a wide range of parameters, the learned model consistently reduces the discrepancy between quantum and classical solutions beyond what is achieved by ZNE alone. We discuss extensions of this approach to higher-dimensional Burgers systems and more general quantum partial differential equation solvers, highlighting learned error mitigation as a promising complement to physics-based noise reduction techniques on NISQ devices.
Intervention Efficiency and Perturbation Validation Framework: Capacity-Aware and Robust Clinical Model Selection under the Rashomon Effect
Nov 18, 2025In clinical machine learning, the coexistence of multiple models with comparable performance -- a manifestation of the Rashomon Effect -- poses fundamental challenges for trustworthy deployment and evaluation. Small, imbalanced, and noisy datasets, coupled with high-dimensional and weakly identified clinical features, amplify this multiplicity and make conventional validation schemes unreliable. As a result, selecting among equally performing models becomes uncertain, particularly when resource constraints and operational priorities are not considered by conventional metrics like F1 score. To address these issues, we propose two complementary tools for robust model assessment and selection: Intervention Efficiency (IE) and the Perturbation Validation Framework (PVF). IE is a capacity-aware metric that quantifies how efficiently a model identifies actionable true positives when only limited interventions are feasible, thereby linking predictive performance with clinical utility. PVF introduces a structured approach to assess the stability of models under data perturbations, identifying models whose performance remains most invariant across noisy or shifted validation sets. Empirical results on synthetic and real-world healthcare datasets show that using these tools facilitates the selection of models that generalize more robustly and align with capacity constraints, offering a new direction for tackling the Rashomon Effect in clinical settings.
Mic-hackathon 2024: Hackathon on Machine Learning for Electron and Scanning Probe Microscopy
Jun 10, 2025

Microscopy is a primary source of information on materials structure and functionality at nanometer and atomic scales. The data generated is often well-structured, enriched with metadata and sample histories, though not always consistent in detail or format. The adoption of Data Management Plans (DMPs) by major funding agencies promotes preservation and access. However, deriving insights remains difficult due to the lack of standardized code ecosystems, benchmarks, and integration strategies. As a result, data usage is inefficient and analysis time is extensive. In addition to post-acquisition analysis, new APIs from major microscope manufacturers enable real-time, ML-based analytics for automated decision-making and ML-agent-controlled microscope operation. Yet, a gap remains between the ML and microscopy communities, limiting the impact of these methods on physics, materials discovery, and optimization. Hackathons help bridge this divide by fostering collaboration between ML researchers and microscopy experts. They encourage the development of novel solutions that apply ML to microscopy, while preparing a future workforce for instrumentation, materials science, and applied ML. This hackathon produced benchmark datasets and digital twins of microscopes to support community growth and standardized workflows. All related code is available at GitHub: https://github.com/KalininGroup/Mic-hackathon-2024-codes-publication/tree/1.0.0.1
Beyond Correlation: Towards Causal Large Language Model Agents in Biomedicine
May 22, 2025Large Language Models (LLMs) show promise in biomedicine but lack true causal understanding, relying instead on correlations. This paper envisions causal LLM agents that integrate multimodal data (text, images, genomics, etc.) and perform intervention-based reasoning to infer cause-and-effect. Addressing this requires overcoming key challenges: designing safe, controllable agentic frameworks; developing rigorous benchmarks for causal evaluation; integrating heterogeneous data sources; and synergistically combining LLMs with structured knowledge (KGs) and formal causal inference tools. Such agents could unlock transformative opportunities, including accelerating drug discovery through automated hypothesis generation and simulation, enabling personalized medicine through patient-specific causal models. This research agenda aims to foster interdisciplinary efforts, bridging causal concepts and foundation models to develop reliable AI partners for biomedical progress.
Three-dimensional neural network driving self-interference digital holography enables high-fidelity, non-scanning volumetric fluorescence microscopy
Apr 15, 2025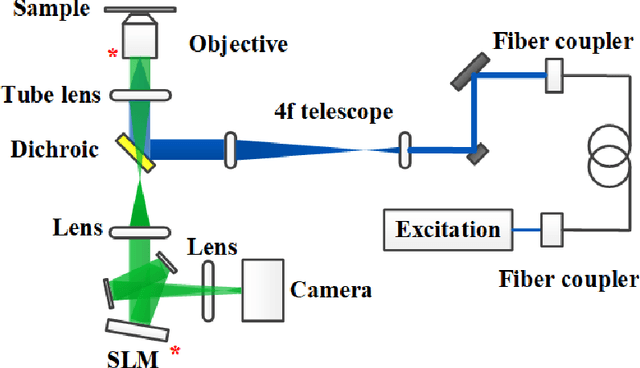
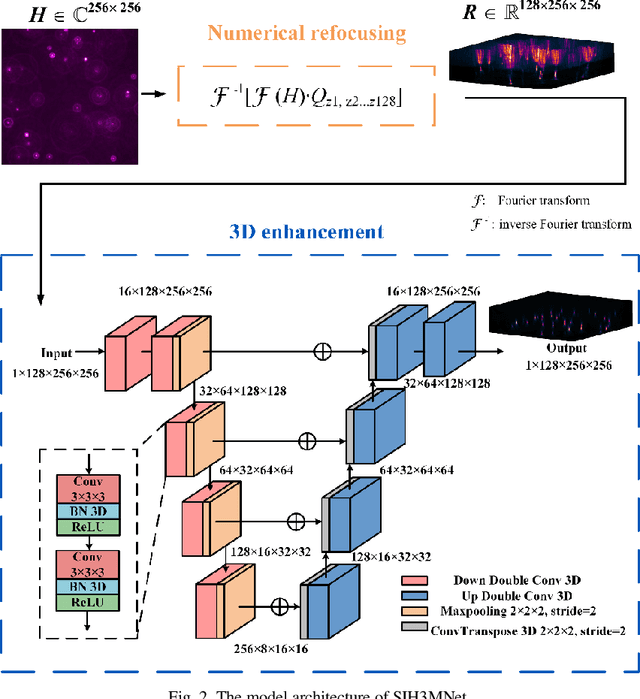
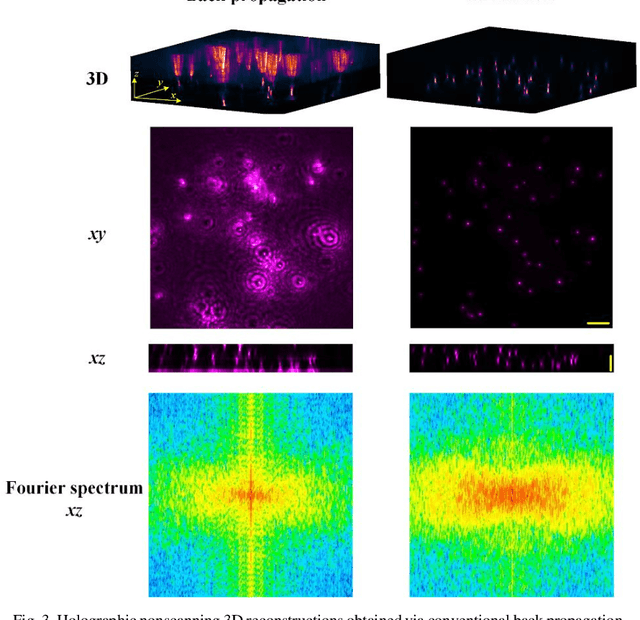
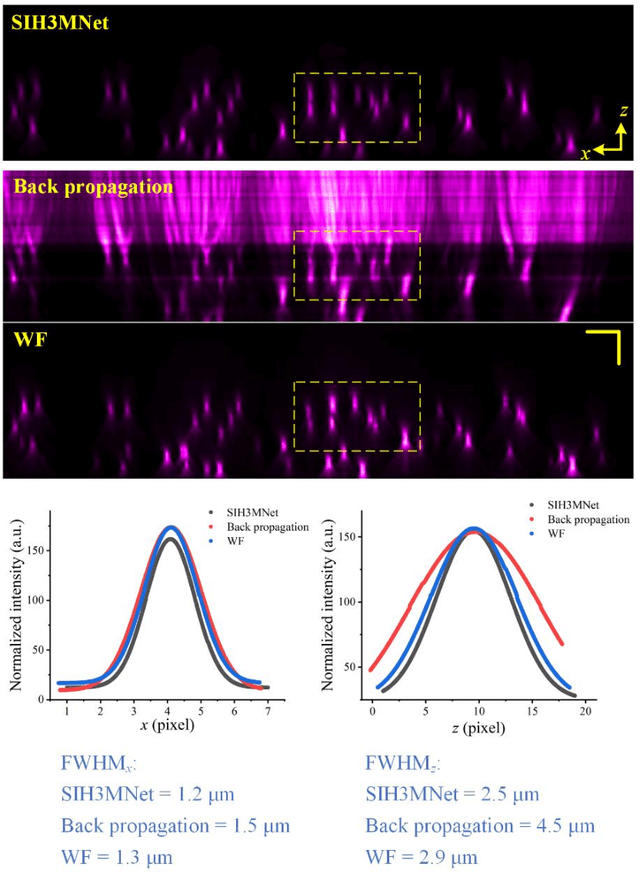
We present a deep learning driven computational approach to overcome the limitations of self-interference digital holography that imposed by inferior axial imaging performances. We demonstrate a 3D deep neural network model can simultaneously suppresses the defocus noise and improves the spatial resolution and signal-to-noise ratio of conventional numerical back-propagation-obtained holographic reconstruction. Compared with existing 2D deep neural networks used for hologram reconstruction, our 3D model exhibits superior performance in enhancing the resolutions along all the three spatial dimensions. As the result, 3D non-scanning volumetric fluorescence microscopy can be achieved, using 2D self-interference hologram as input, without any mechanical and opto-electronic scanning and complicated system calibration. Our method offers a high spatiotemporal resolution 3D imaging approach which can potentially benefit, for example, the visualization of dynamics of cellular structure and measurement of 3D behavior of high-speed flow field.
Blending Is All You Need: Cheaper, Better Alternative to Trillion-Parameters LLM
Jan 09, 2024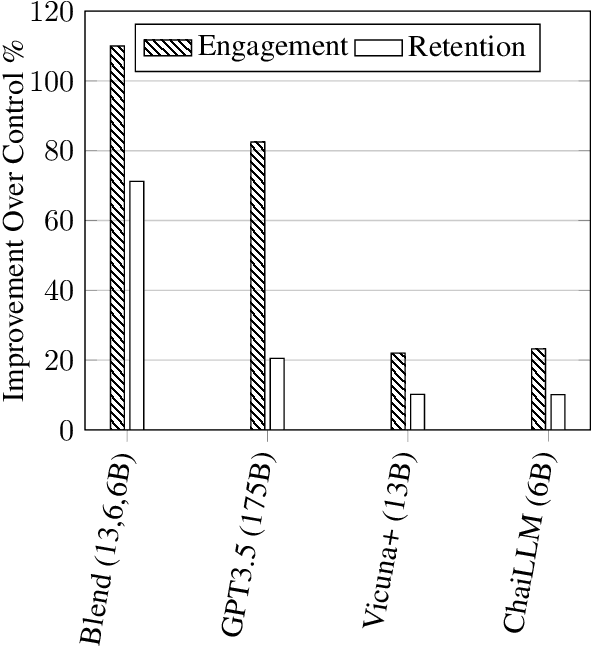
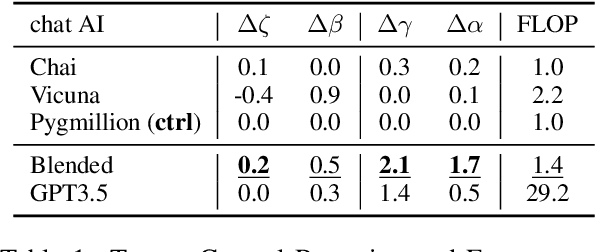
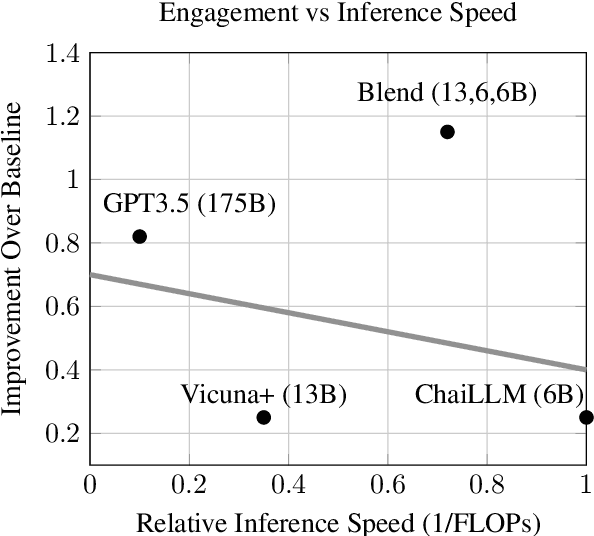
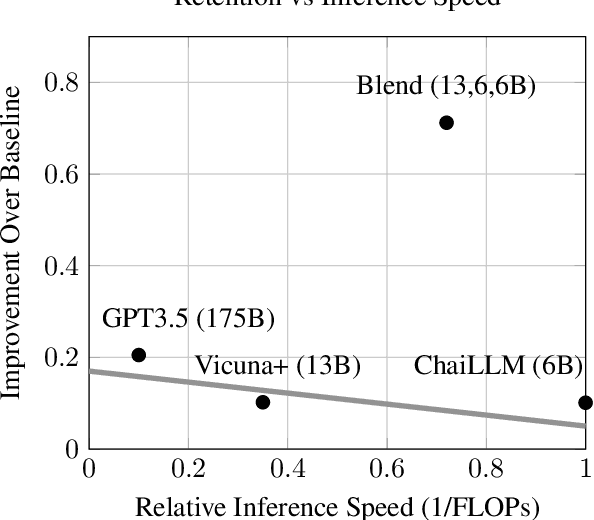
In conversational AI research, there's a noticeable trend towards developing models with a larger number of parameters, exemplified by models like ChatGPT. While these expansive models tend to generate increasingly better chat responses, they demand significant computational resources and memory. This study explores a pertinent question: Can a combination of smaller models collaboratively achieve comparable or enhanced performance relative to a singular large model? We introduce an approach termed "blending", a straightforward yet effective method of integrating multiple chat AIs. Our empirical evidence suggests that when specific smaller models are synergistically blended, they can potentially outperform or match the capabilities of much larger counterparts. For instance, integrating just three models of moderate size (6B/13B paramaeters) can rival or even surpass the performance metrics of a substantially larger model like ChatGPT (175B+ paramaters). This hypothesis is rigorously tested using A/B testing methodologies with a large user base on the Chai research platform over a span of thirty days. The findings underscore the potential of the "blending" strategy as a viable approach for enhancing chat AI efficacy without a corresponding surge in computational demands.
BayesFT: Bayesian Optimization for Fault Tolerant Neural Network Architecture
Sep 30, 2022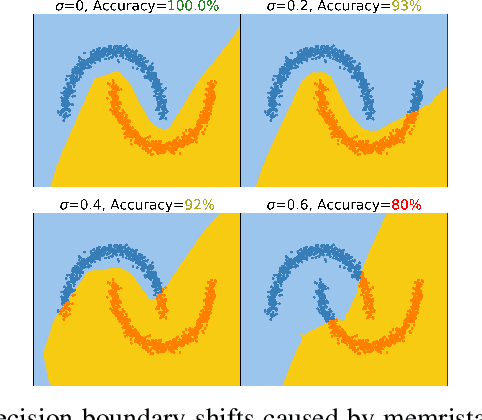
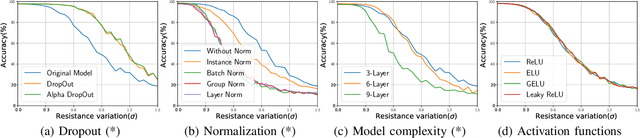
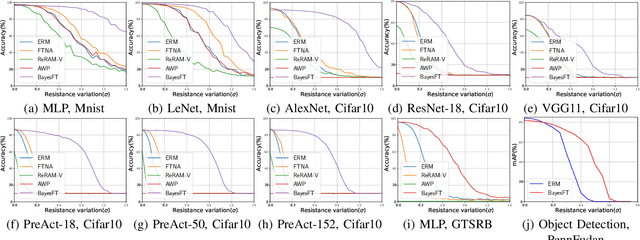

To deploy deep learning algorithms on resource-limited scenarios, an emerging device-resistive random access memory (ReRAM) has been regarded as promising via analog computing. However, the practicability of ReRAM is primarily limited due to the weight drifting of ReRAM neural networks due to multi-factor reasons, including manufacturing, thermal noises, and etc. In this paper, we propose a novel Bayesian optimization method for fault tolerant neural network architecture (BayesFT). For neural architecture search space design, instead of conducting neural architecture search on the whole feasible neural architecture search space, we first systematically explore the weight drifting tolerance of different neural network components, such as dropout, normalization, number of layers, and activation functions in which dropout is found to be able to improve the neural network robustness to weight drifting. Based on our analysis, we propose an efficient search space by only searching for dropout rates for each layer. Then, we use Bayesian optimization to search for the optimal neural architecture robust to weight drifting. Empirical experiments demonstrate that our algorithmic framework has outperformed the state-of-the-art methods by up to 10 times on various tasks, such as image classification and object detection.
Long-run User Value Optimization in Recommender Systems through Content Creation Modeling
Apr 25, 2022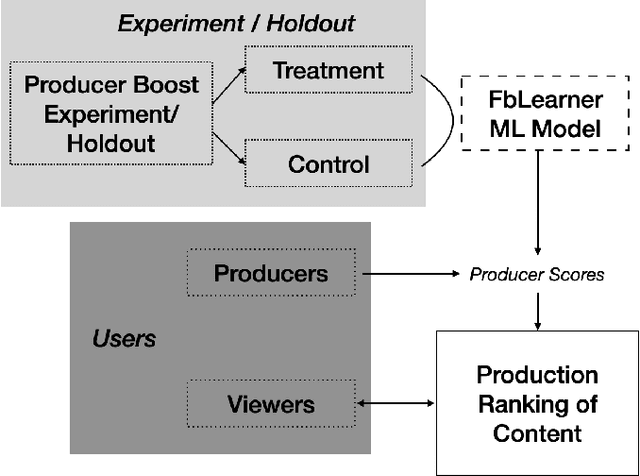
Content recommender systems are generally adept at maximizing immediate user satisfaction but to optimize for the \textit{long-run} user value, we need more statistically sophisticated solutions than off-the-shelf simple recommender algorithms. In this paper we lay out such a solution to optimize \textit{long-run} user value through discounted utility maximization and a machine learning method we have developed for estimating it. Our method estimates which content producers are most likely to create the highest long-run user value if their content is shown more to users who enjoy it in the present. We do this estimation with the help of an A/B test and heterogeneous effects machine learning model. We have used such models in Facebook's feed ranking system, and such a model can be used in other recommender systems.