 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-run User Value Optimization in Recommender Systems through Content Creation Modeling
Apr 25, 2022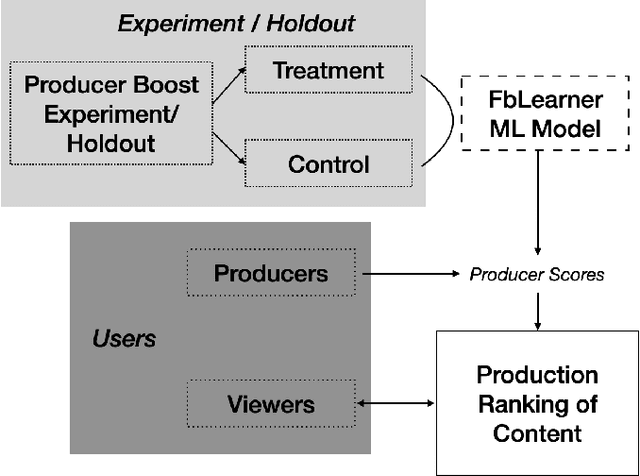
Content recommender systems are generally adept at maximizing immediate user satisfaction but to optimize for the \textit{long-run} user value, we need more statistically sophisticated solutions than off-the-shelf simple recommender algorithms. In this paper we lay out such a solution to optimize \textit{long-run} user value through discounted utility maximization and a machine learning method we have developed for estimating it. Our method estimates which content producers are most likely to create the highest long-run user value if their content is shown more to users who enjoy it in the present. We do this estimation with the help of an A/B test and heterogeneous effects machine learning model. We have used such models in Facebook's feed ranking system, and such a model can be used in other recommender systems.
Combining observational and experimental data to find heterogeneous treatment effects
Nov 08, 2016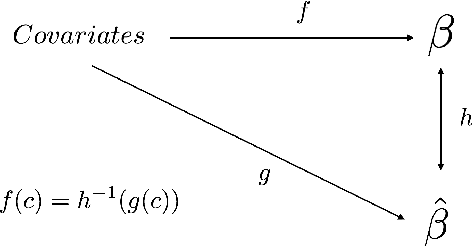
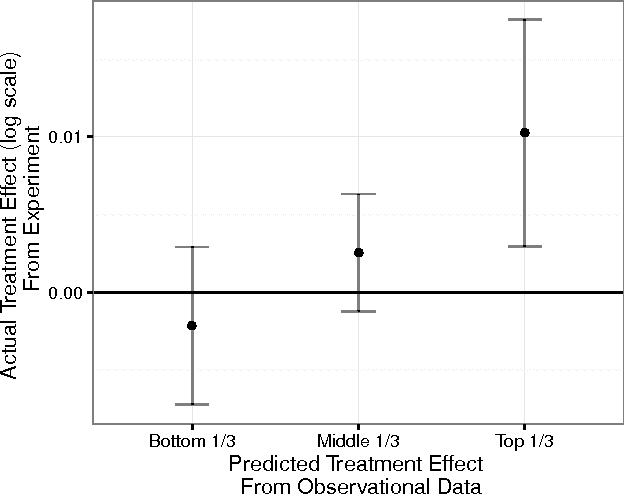
Every design choice will have different effects on different units. However traditional A/B tests are often underpowered to identify these heterogeneous effects. This is especially true when the set of unit-level attributes is high-dimensional and our priors are weak about which particular covariates are important. However, there are often observational data sets available that are orders of magnitude larger. We propose a method to combine these two data sources to estimate heterogeneous treatment effects. First, we use observational time series data to estimate a mapping from covariates to unit-level effects. These estimates are likely biased but under some conditions the bias preserves unit-level relative rank orderings. If these conditions hold, we only need sufficient experimental data to identify a monotonic, one-dimensional transformation from observationally predicted treatment effects to real treatment effects. This reduces power demands greatly and makes the detection of heterogeneous effects much easier. As an application, we show how our method can be used to improve Facebook page recommendations.