 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Federated Continual Learning
Apr 07, 2023The standard class-incremental continual learning setting assumes a set of tasks seen one after the other in a fixed and predefined order. This is not very realistic in federated learning environments where each client works independently in an asynchronous manner getting data for the different tasks in time-frames and orders totally uncorrelated with the other ones. We introduce a novel federated learning setting (AFCL) where the continual learning of multiple tasks happens at each client with different orderings and in asynchronous time slots. We tackle this novel task using prototype-based learning, a representation loss, fractal pre-training, and a modified aggregation policy. Our approach, called FedSpace, effectively tackles this task as shown by the results on the CIFAR-100 dataset using 3 different federated splits with 50, 100, and 500 clients, respectively. The code and federated splits are available at https://github.com/LTTM/FedSpace.
Learning with Style: Continual Semantic Segmentation Across Tasks and Domains
Oct 13, 2022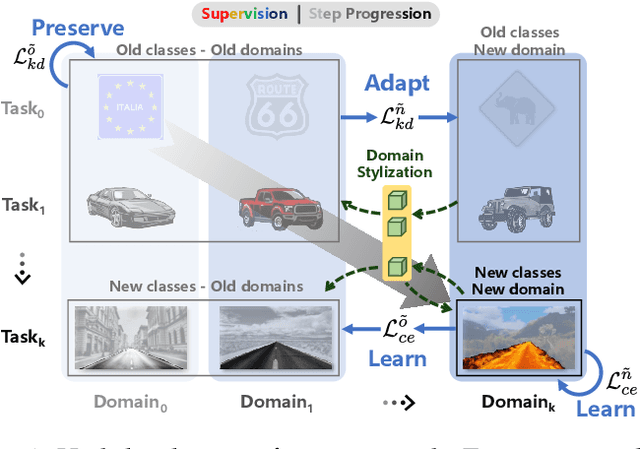

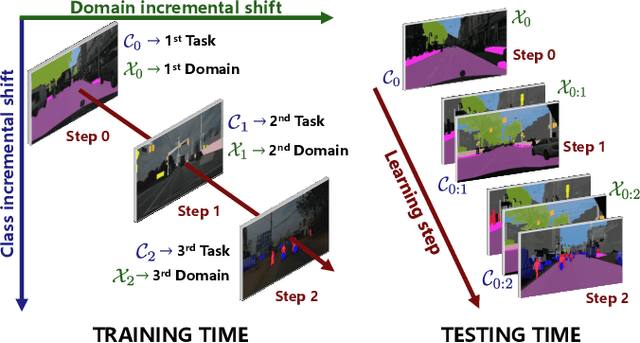

Deep learning models dealing with image understanding in real-world settings must be able to adapt to a wide variety of tasks across different domains. Domain adaptation and class incremental learning deal with domain and task variability separately, whereas their unified solution is still an open problem. We tackle both facets of the problem together, taking into account the semantic shift within both input and label spaces. We start by formally introducing continual learning under task and domain shift. Then, we address the proposed setup by using style transfer techniques to extend knowledge across domains when learning incremental tasks and a robust distillation framework to effectively recollect task knowledge under incremental domain shift. The devised framework (LwS, Learning with Style) is able to generalize incrementally acquired task knowledge across all the domains encountered, proving to be robust against catastrophic forgetting. Extensive experimental evaluation on multiple autonomous driving datasets shows how the proposed method outperforms existing approaches, which prove to be ill-equipped to deal with continual semantic segmentation under both task and domain shift.
Learning Across Domains and Devices: Style-Driven Source-Free Domain Adaptation in Clustered Federated Learning
Oct 05, 2022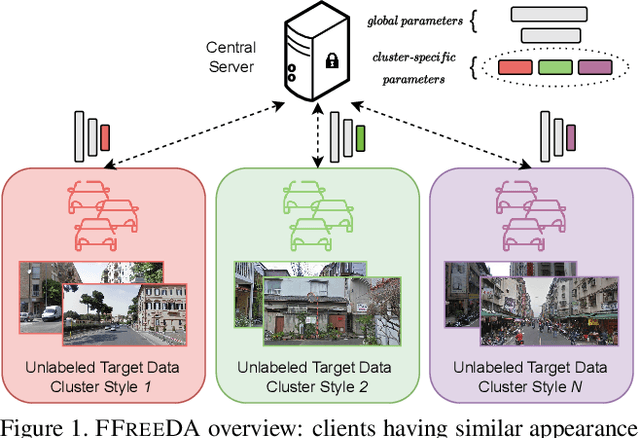
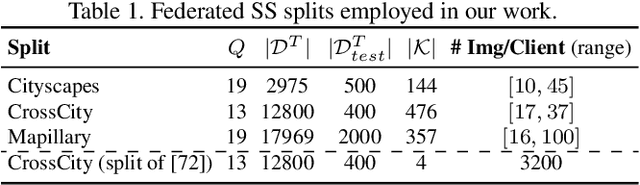
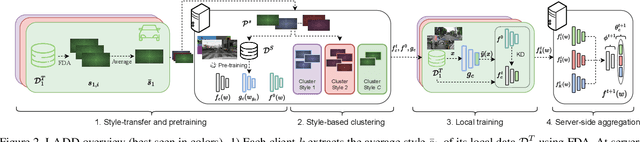
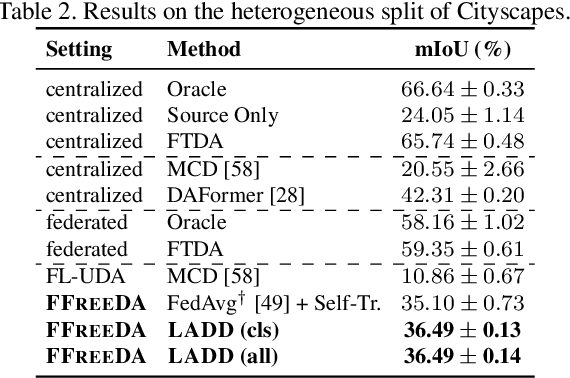
Federated Learning (FL) has recently emerged as a possible way to tackle the domain shift in real-world Semantic Segmentation (SS) without compromising the private nature of the collected data. However, most of the existing works on FL unrealistically assume labeled data in the remote clients. Here we propose a novel task (FFREEDA) in which the clients' data is unlabeled and the server accesses a source labeled dataset for pre-training only. To solve FFREEDA, we propose LADD, which leverages the knowledge of the pre-trained model by employing self-supervision with ad-hoc regularization techniques for local training and introducing a novel federated clustered aggregation scheme based on the clients' style. Our experiments show that our algorithm is able to efficiently tackle the new task outperforming existing approaches. The code is available at https://github.com/Erosinho13/LADD.
Adapting Segmentation Networks to New Domains by Disentangling Latent Representations
Aug 10, 2021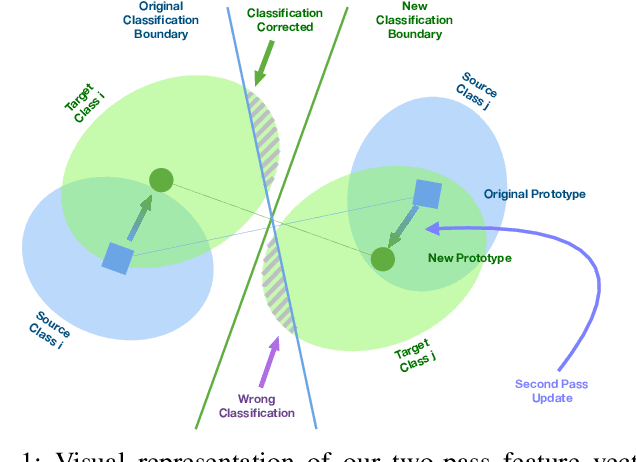
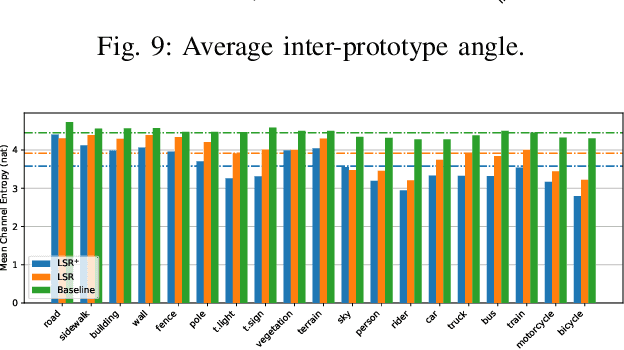
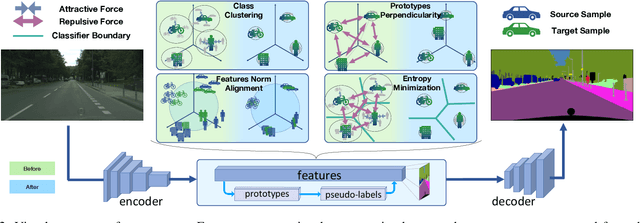
Deep learning models achieve outstanding accuracy in semantic segmentation, however they require a huge amount of labeled data for their optimization. Hence, domain adaptation approaches have come into play to transfer knowledge acquired on a label-abundant source domain to a related label-scarce target domain. However, such models do not generalize well to data with statistical properties not perfectly matching the ones of the training samples. In this work, we design and carefully analyze multiple latent space-shaping regularization strategies that work in conjunction to reduce the domain discrepancy in semantic segmentation. In particular, we devise a feature clustering strategy to increase domain alignment, a feature perpendicularity constraint to space apart feature belonging to different semantic classes, including those not present in the current batch, and a feature norm alignment strategy to separate active and inactive channels. Additionally, we propose a novel performance metric to capture the relative efficacy of an adaptation strategy compared to supervised training. We verify the effectiveness of our framework in synthetic-to-real and real-to-real adaptation scenarios, outperforming previous state-of-the-art methods on multiple road scenes benchmarks and using different backbones.
RECALL: Replay-based Continual Learning in Semantic Segmentation
Aug 08, 2021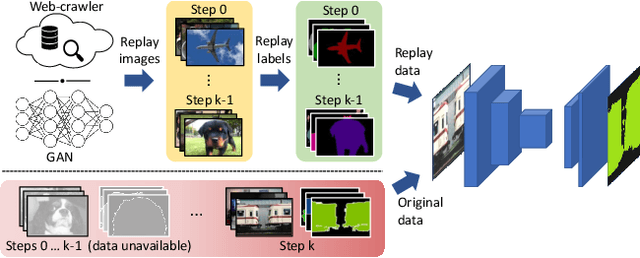
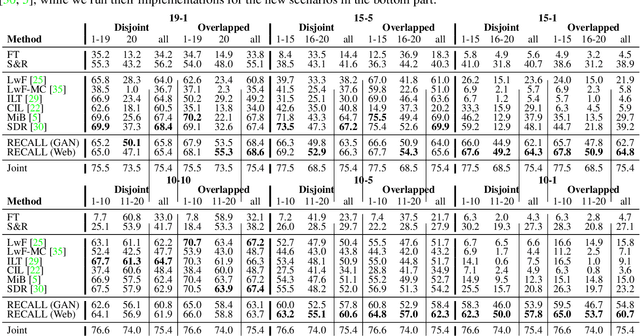
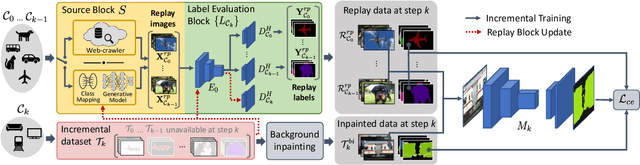
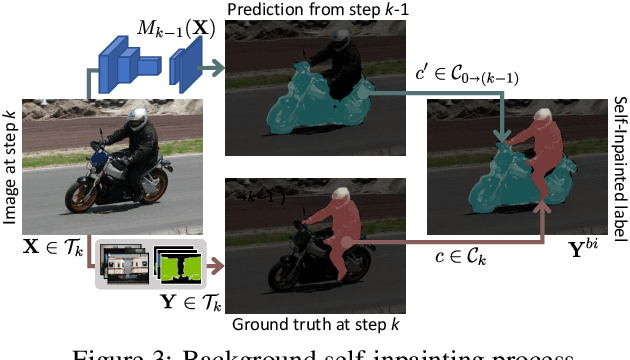
Deep networks allow to obtain outstanding results in semantic segmentation, however they need to be trained in a single shot with a large amount of data. Continual learning settings where new classes are learned in incremental steps and previous training data is no longer available are challenging due to the catastrophic forgetting phenomenon. Existing approaches typically fail when several incremental steps are performed or in presence of a distribution shift of the background class. We tackle these issues by recreating no longer available data for the old classes and outlining a content inpainting scheme on the background class. We propose two sources for replay data. The first resorts to a generative adversarial network to sample from the class space of past learning steps. The second relies on web-crawled data to retrieve images containing examples of old classes from online databases. In both scenarios no samples of past steps are stored, thus avoiding privacy concerns. Replay data are then blended with new samples during the incremental steps. Our approach, RECALL, outperforms state-of-the-art methods.
Latent Space Regularization for Unsupervised Domain Adaptation in Semantic Segmentation
Apr 21, 2021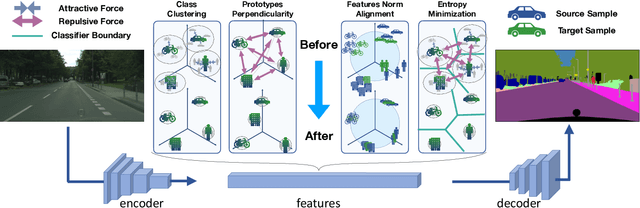
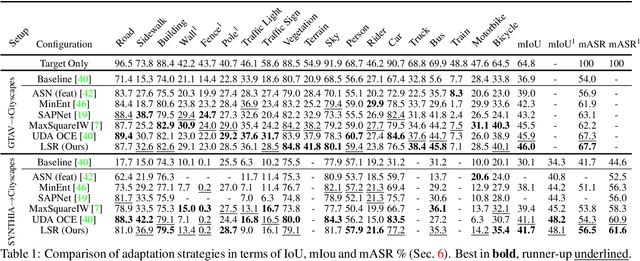

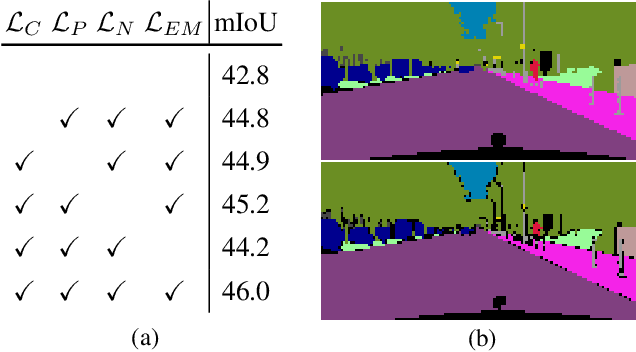
Deep convolutional neural networks for semantic segmentation achieve outstanding accuracy, however they also have a couple of major drawbacks: first, they do not generalize well to distributions slightly different from the one of the training data; second, they require a huge amount of labeled data for their optimization. In this paper, we introduce feature-level space-shaping regularization strategies to reduce the domain discrepancy in semantic segmentation. In particular, for this purpose we jointly enforce a clustering objective, a perpendicularity constraint and a norm alignment goal on the feature vectors corresponding to source and target samples. Additionally, we propose a novel measure able to capture the relative efficacy of an adaptation strategy compared to supervised training. We verify the effectiveness of such methods in the autonomous driving setting achieving state-of-the-art results in multiple synthetic-to-real road scenes benchmarks.
Unsupervised Domain Adaptation in Semantic Segmentation via Orthogonal and Clustered Embeddings
Nov 25, 2020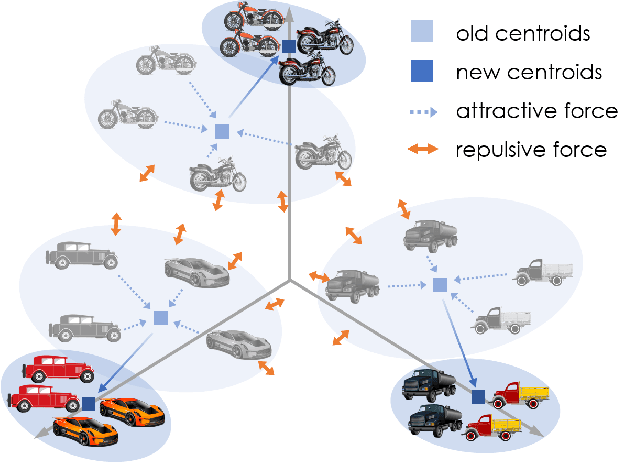
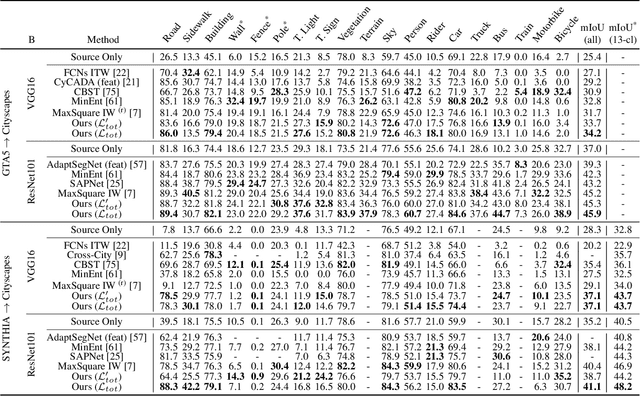
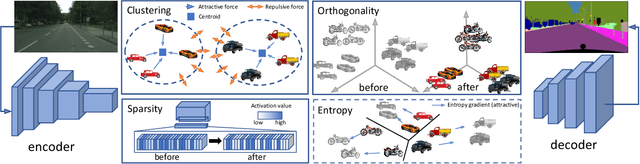

Deep learning frameworks allowed for a remarkable advancement in semantic segmentation, but the data hungry nature of convolutional networks has rapidly raised the demand for adaptation techniques able to transfer learned knowledge from label-abundant domains to unlabeled ones. In this paper we propose an effective Unsupervised Domain Adaptation (UDA) strategy, based on a feature clustering method that captures the different semantic modes of the feature distribution and groups features of the same class into tight and well-separated clusters. Furthermore, we introduce two novel learning objectives to enhance the discriminative clustering performance: an orthogonality loss forces spaced out individual representations to be orthogonal, while a sparsity loss reduces class-wise the number of active feature channels. The joint effect of these modules is to regularize the structure of the feature space. Extensive evaluations in the synthetic-to-real scenario show that we achieve state-of-the-art performance.
Unsupervised Domain Adaptation in Semantic Segmentation: a Review
May 21, 2020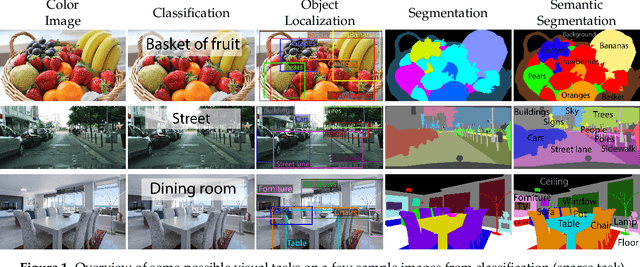
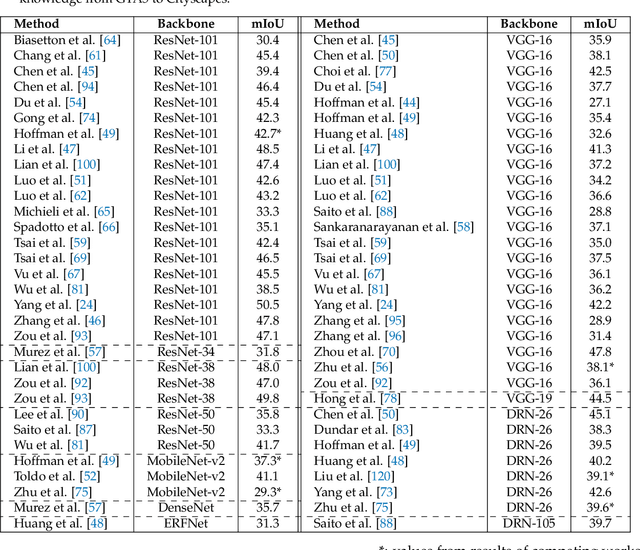

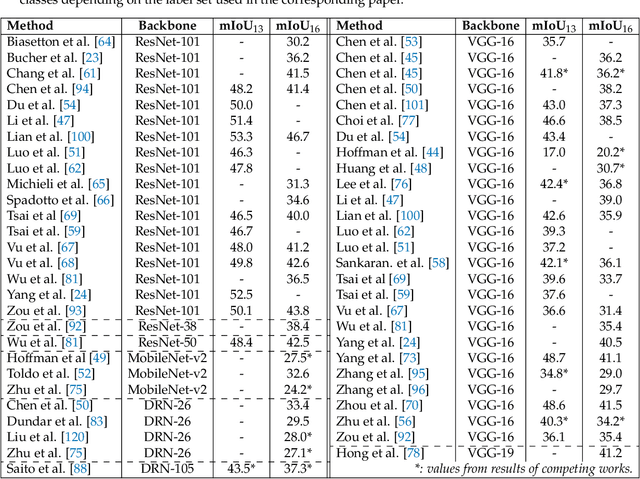
The aim of this paper is to give an overview of the recent advancements in the Unsupervised Domain Adaptation (UDA) of deep networks for semantic segmentation. This task is attracting a wide interest, since semantic segmentation models require a huge amount of labeled data and the lack of data fitting specific requirements is the main limitation in the deployment of these techniques. This problem has been recently explored and has rapidly grown with a large number of ad-hoc approaches. This motivates us to build a comprehensive overview of the proposed methodologies and to provide a clear categorization. In this paper, we start by introducing the problem, its formulation and the various scenarios that can be considered. Then, we introduce the different levels at which adaptation strategies may be applied: namely, at the input (image) level, at the internal features representation and at the output level. Furthermore, we present a detailed overview of the literature in the field, dividing previous methods based on the following (non mutually exclusive) categories: adversarial learning, generative-based, analysis of the classifier discrepancies, self-teaching, entropy minimization, curriculum learning and multi-task learning. Novel research directions are also briefly introduced to give a hint of interesting open problems in the field. Finally, a comparison of the performance of the various methods in the widely used autonomous driving scenario is presented.
Unsupervised Domain Adaptation with Multiple Domain Discriminators and Adaptive Self-Training
Apr 27, 2020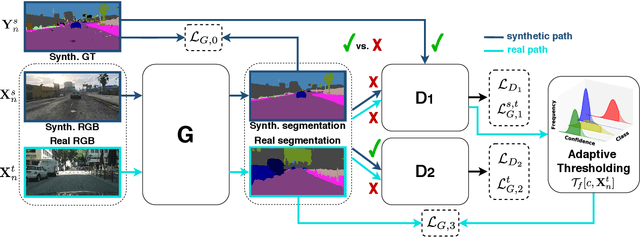
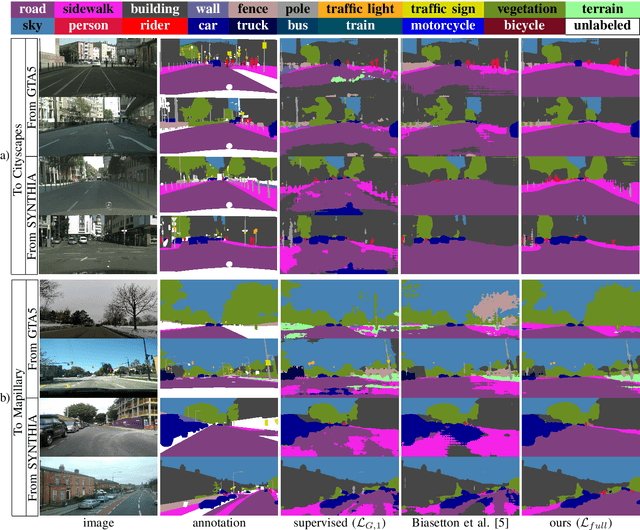
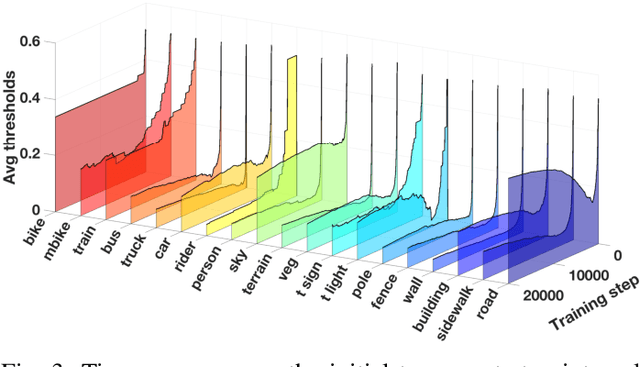
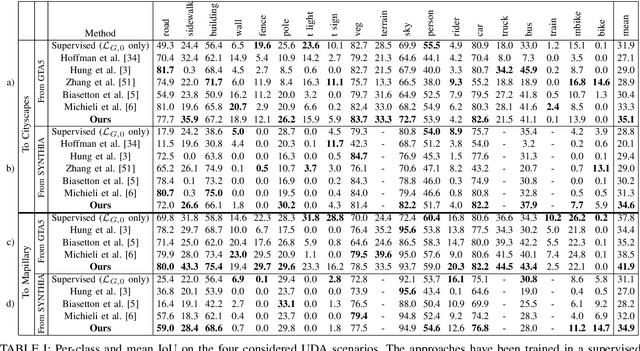
Unsupervised Domain Adaptation (UDA) aims at improving the generalization capability of a model trained on a source domain to perform well on a target domain for which no labeled data is available. In this paper, we consider the semantic segmentation of urban scenes and we propose an approach to adapt a deep neural network trained on synthetic data to real scenes addressing the domain shift between the two different data distributions. We introduce a novel UDA framework where a standard supervised loss on labeled synthetic data is supported by an adversarial module and a self-training strategy aiming at aligning the two domain distributions. The adversarial module is driven by a couple of fully convolutional discriminators dealing with different domains: the first discriminates between ground truth and generated maps, while the second between segmentation maps coming from synthetic or real world data. The self-training module exploits the confidence estimated by the discriminators on unlabeled data to select the regions used to reinforce the learning process. Furthermore, the confidence is thresholded with an adaptive mechanism based on the per-class overall confidence. Experimental results prove the effectiveness of the proposed strategy in adapting a segmentation network trained on synthetic datasets like GTA5 and SYNTHIA, to real world datasets like Cityscapes and Mapillary.
Unsupervised Domain Adaptation for Mobile Semantic Segmentation based on Cycle Consistency and Feature Alignment
Jan 14, 2020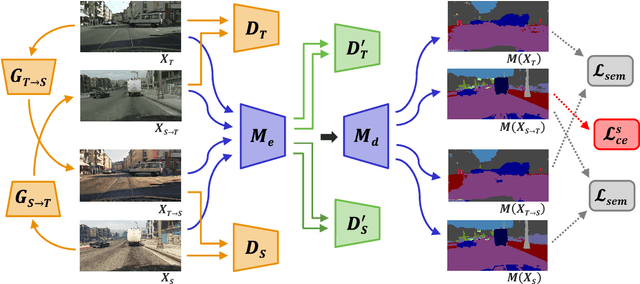


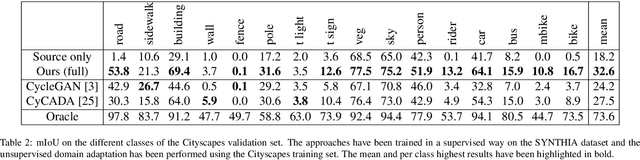
The supervised training of deep networks for semantic segmentation requires a huge amount of labeled real world data. To solve this issue, a commonly exploited workaround is to use synthetic data for training, but deep networks show a critical performance drop when analyzing data with slightly different statistical properties with respect to the training set. In this work, we propose a novel Unsupervised Domain Adaptation (UDA) strategy to address the domain shift issue between real world and synthetic representations. An adversarial model, based on the cycle consistency framework, performs the mapping between the synthetic and real domain. The data is then fed to a MobileNet-v2 architecture that performs the semantic segmentation task. An additional couple of discriminators, working at the feature level of the MobileNet-v2, allows to better align the features of the two domain distributions and to further improve the performance. Finally, the consistency of the semantic maps is exploited. After an initial supervised training on synthetic data, the whole UDA architecture is trained end-to-end considering all its components at once. Experimental results show how the proposed strategy is able to obtain impressive performance in adapting a segmentation network trained on synthetic data to real world scenarios. The usage of the lightweight MobileNet-v2 architecture allows its deployment on devices with limited computational resources as the ones employed in autonomous vehicles.