 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Dynamic Upcycling of Expert Language Models
Mar 31, 2026Large Language Models (LLMs) have achieved remarkable performance on a wide range of specialized tasks, exhibiting strong problem-solving capabilities. However, training these models is prohibitively expensive, and they often lack domain-specific expertise because they rely on general knowledge datasets. Expertise finetuning can address this issue; however, it often leads to overspecialization, and developing a single multi-domain expert remains difficult due to diverging objectives. Furthermore, multitask training is challenging due to interference and catastrophic forgetting. Existing work proposes combining the expertise of dense models within a Mixture of Experts (MoE) architecture, although this approach still requires multitask finetuning. To address these issues, we introduce Dynamic Upcycling MoE (DUME), a novel approach that reuses dense experts trained on different domains to construct a unified MoE model. Our method builds a single multitask model that preserves the capabilities of the original dense experts without requiring additional training. DUME is both cost-efficient and scalable: by leveraging the closed-form solution of ridge regression, it eliminates the need for further optimization and enables experts to be added dynamically while maintaining the model's original performance. We demonstrate that DUME consistently outperforms baseline approaches in both causal language modeling and reasoning settings. Finally, we also show that the DUME model can be fine-tuned to further improve performance. We show that, in the causal language modeling setting, DUME can retain up to 97.6% of a dense expert model specialized in one particular domain, and that it can also surpass it in the reasoning setting, where it can achieve 102.1% of the dense expert performance. Our code is available at: github.com/gensyn-ai/dume.
Diversity-Driven Learning: Tackling Spurious Correlations and Data Heterogeneity in Federated Models
Apr 15, 2025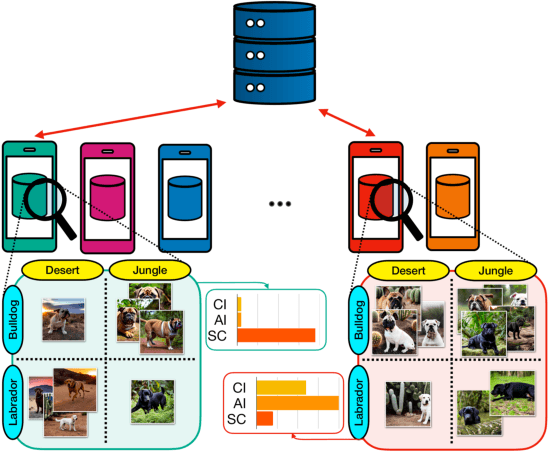

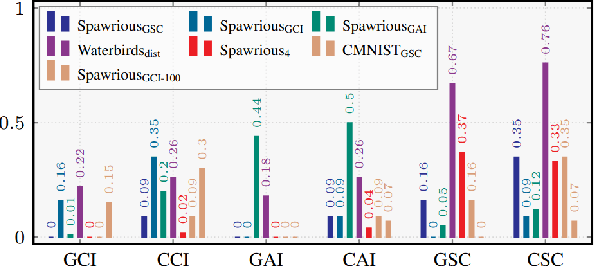
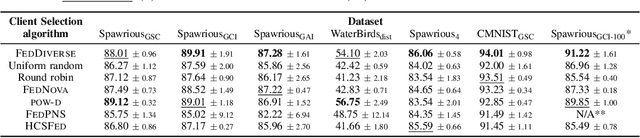
Federated Learning (FL) enables decentralized training of machine learning models on distributed data while preserving privacy. However, in real-world FL settings, client data is often non-identically distributed and imbalanced, resulting in statistical data heterogeneity which impacts the generalization capabilities of the server's model across clients, slows convergence and reduces performance. In this paper, we address this challenge by first proposing a characterization of statistical data heterogeneity by means of 6 metrics of global and client attribute imbalance, class imbalance, and spurious correlations. Next, we create and share 7 computer vision datasets for binary and multiclass image classification tasks in Federated Learning that cover a broad range of statistical data heterogeneity and hence simulate real-world situations. Finally, we propose FedDiverse, a novel client selection algorithm in FL which is designed to manage and leverage data heterogeneity across clients by promoting collaboration between clients with complementary data distributions. Experiments on the seven proposed FL datasets demonstrate FedDiverse's effectiveness in enhancing the performance and robustness of a variety of FL methods while having low communication and computational overhead.
Accelerating Heterogeneous Federated Learning with Closed-form Classifiers
Jun 03, 2024Federated Learning (FL) methods often struggle in highly statistically heterogeneous settings. Indeed, non-IID data distributions cause client drift and biased local solutions, particularly pronounced in the final classification layer, negatively impacting convergence speed and accuracy. To address this issue, we introduce Federated Recursive Ridge Regression (Fed3R). Our method fits a Ridge Regression classifier computed in closed form leveraging pre-trained features. Fed3R is immune to statistical heterogeneity and is invariant to the sampling order of the clients. Therefore, it proves particularly effective in cross-device scenarios. Furthermore, it is fast and efficient in terms of communication and computation costs, requiring up to two orders of magnitude fewer resources than the competitors. Finally, we propose to leverage the Fed3R parameters as an initialization for a softmax classifier and subsequently fine-tune the model using any FL algorithm (Fed3R with Fine-Tuning, Fed3R+FT). Our findings also indicate that maintaining a fixed classifier aids in stabilizing the training and learning more discriminative features in cross-device settings. Official website: https://fed-3r.github.io/.
FedDrive v2: an Analysis of the Impact of Label Skewness in Federated Semantic Segmentation for Autonomous Driving
Sep 23, 2023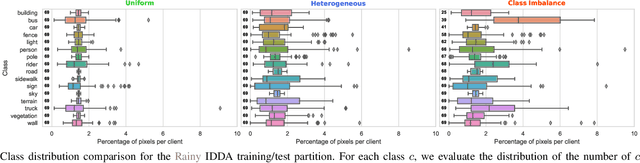
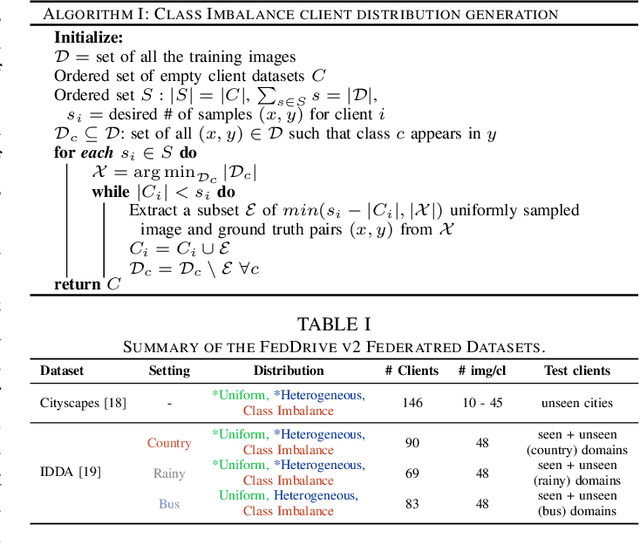

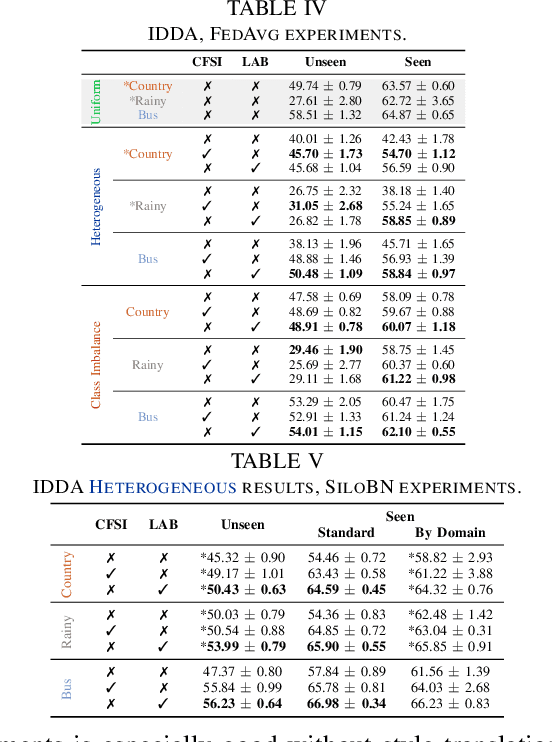
We propose FedDrive v2, an extension of the Federated Learning benchmark for Semantic Segmentation in Autonomous Driving. While the first version aims at studying the effect of domain shift of the visual features across clients, in this work, we focus on the distribution skewness of the labels. We propose six new federated scenarios to investigate how label skewness affects the performance of segmentation models and compare it with the effect of domain shift. Finally, we study the impact of using the domain information during testing.
Learning Across Domains and Devices: Style-Driven Source-Free Domain Adaptation in Clustered Federated Learning
Oct 05, 2022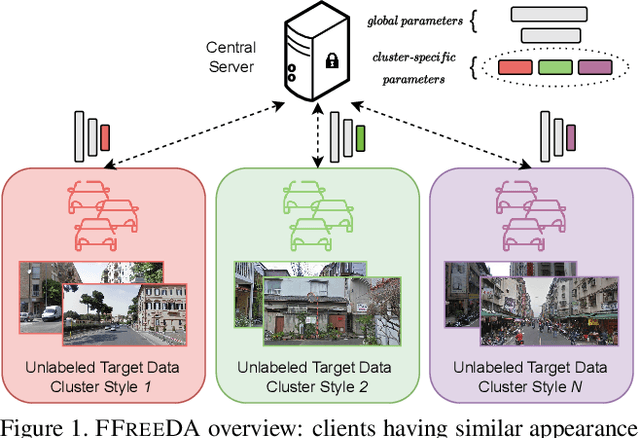
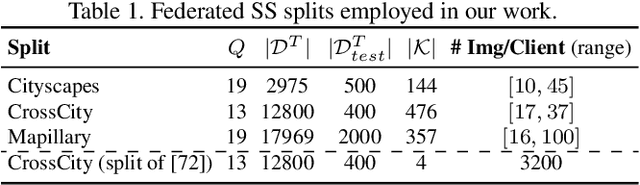
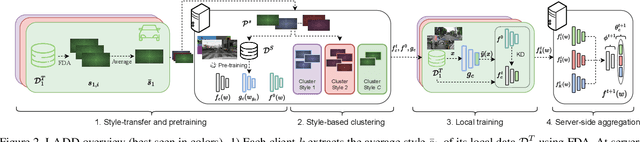
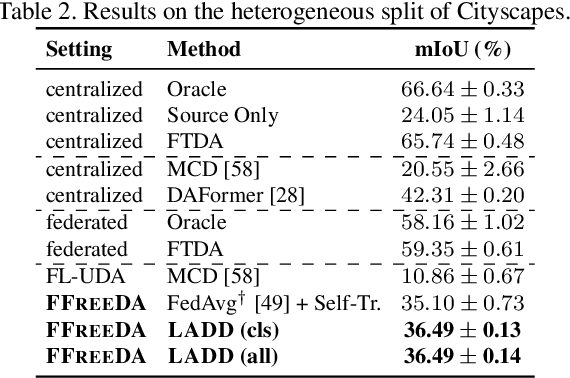
Federated Learning (FL) has recently emerged as a possible way to tackle the domain shift in real-world Semantic Segmentation (SS) without compromising the private nature of the collected data. However, most of the existing works on FL unrealistically assume labeled data in the remote clients. Here we propose a novel task (FFREEDA) in which the clients' data is unlabeled and the server accesses a source labeled dataset for pre-training only. To solve FFREEDA, we propose LADD, which leverages the knowledge of the pre-trained model by employing self-supervision with ad-hoc regularization techniques for local training and introducing a novel federated clustered aggregation scheme based on the clients' style. Our experiments show that our algorithm is able to efficiently tackle the new task outperforming existing approaches. The code is available at https://github.com/Erosinho13/LADD.