 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Transfer Learning with CoRTe: Consistent and Reliable Transfer from Black-Box to Lightweight Segmentation Model
Feb 20, 2024Many practical applications require training of semantic segmentation models on unlabelled datasets and their execution on low-resource hardware. Distillation from a trained source model may represent a solution for the first but does not account for the different distribution of the training data. Unsupervised domain adaptation (UDA) techniques claim to solve the domain shift, but in most cases assume the availability of the source data or an accessible white-box source model, which in practical applications are often unavailable for commercial and/or safety reasons. In this paper, we investigate a more challenging setting in which a lightweight model has to be trained on a target unlabelled dataset for semantic segmentation, under the assumption that we have access only to black-box source model predictions. Our method, named CoRTe, consists of (i) a pseudo-labelling function that extracts reliable knowledge from the black-box source model using its relative confidence, (ii) a pseudo label refinement method to retain and enhance the novel information learned by the student model on the target data, and (iii) a consistent training of the model using the extracted pseudo labels. We benchmark CoRTe on two synthetic-to-real settings, demonstrating remarkable results when using black-box models to transfer knowledge on lightweight models for a target data distribution.
Hierarchical Instance Mixing across Domains in Aerial Segmentation
Oct 12, 2022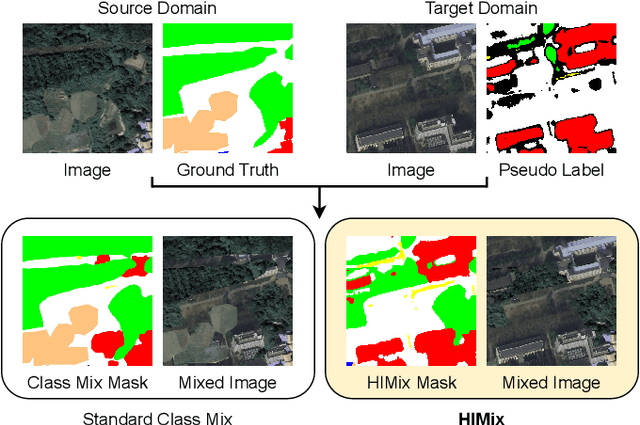
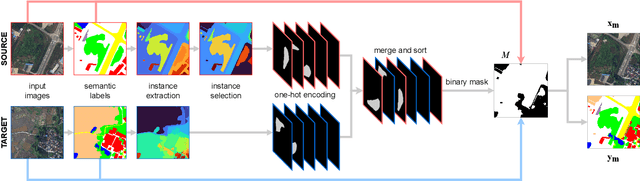

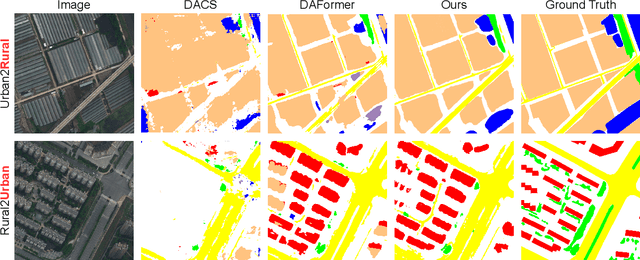
We investigate the task of unsupervised domain adaptation in aerial semantic segmentation and discover that the current state-of-the-art algorithms designed for autonomous driving based on domain mixing do not translate well to the aerial setting. This is due to two factors: (i) a large disparity in the extension of the semantic categories, which causes a domain imbalance in the mixed image, and (ii) a weaker structural consistency in aerial scenes than in driving scenes since the same scene might be viewed from different perspectives and there is no well-defined and repeatable structure of the semantic elements in the images. Our solution to these problems is composed of: (i) a new mixing strategy for aerial segmentation across domains called Hierarchical Instance Mixing (HIMix), which extracts a set of connected components from each semantic mask and mixes them according to a semantic hierarchy and, (ii) a twin-head architecture in which two separate segmentation heads are fed with variations of the same images in a contrastive fashion to produce finer segmentation maps. We conduct extensive experiments on the LoveDA benchmark, where our solution outperforms the current state-of-the-art.
Learning Across Domains and Devices: Style-Driven Source-Free Domain Adaptation in Clustered Federated Learning
Oct 05, 2022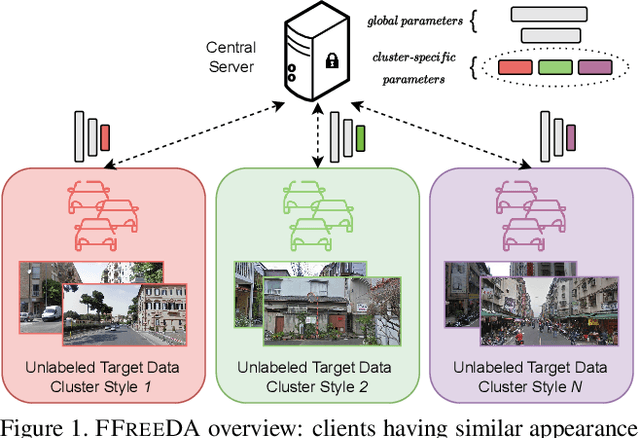
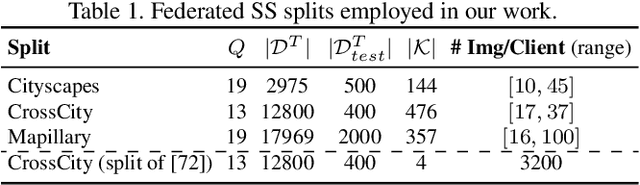
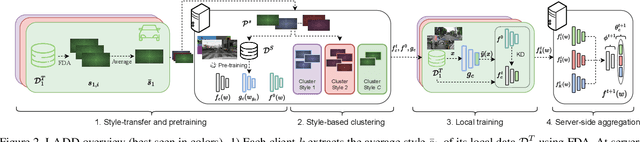
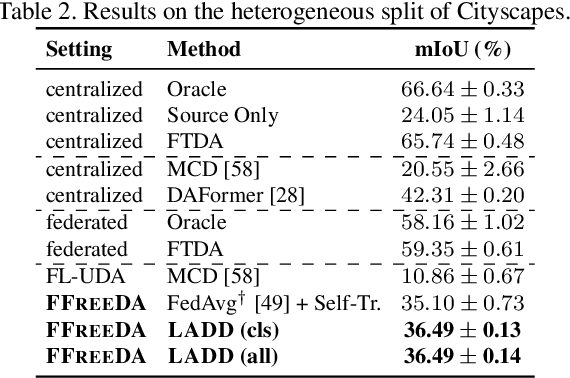
Federated Learning (FL) has recently emerged as a possible way to tackle the domain shift in real-world Semantic Segmentation (SS) without compromising the private nature of the collected data. However, most of the existing works on FL unrealistically assume labeled data in the remote clients. Here we propose a novel task (FFREEDA) in which the clients' data is unlabeled and the server accesses a source labeled dataset for pre-training only. To solve FFREEDA, we propose LADD, which leverages the knowledge of the pre-trained model by employing self-supervision with ad-hoc regularization techniques for local training and introducing a novel federated clustered aggregation scheme based on the clients' style. Our experiments show that our algorithm is able to efficiently tackle the new task outperforming existing approaches. The code is available at https://github.com/Erosinho13/LADD.
Augmentation Invariance and Adaptive Sampling in Semantic Segmentation of Agricultural Aerial Images
Apr 17, 2022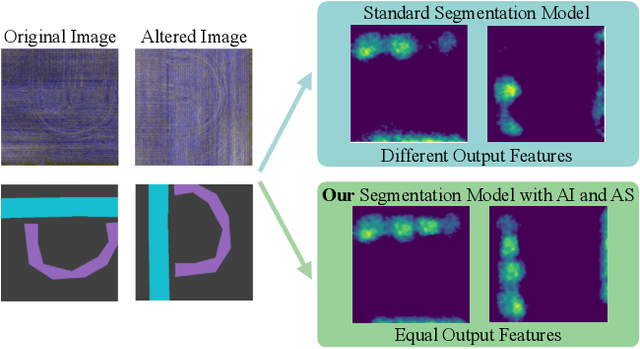
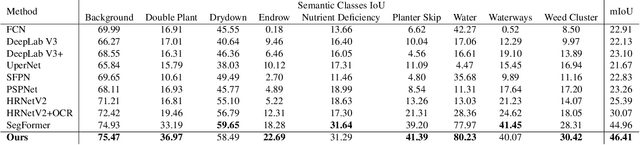
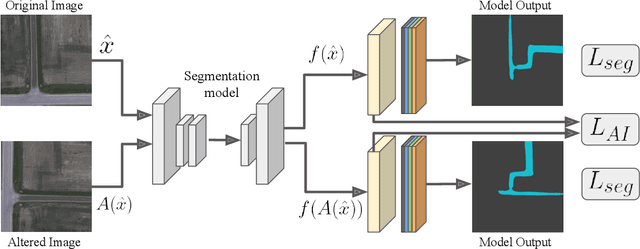
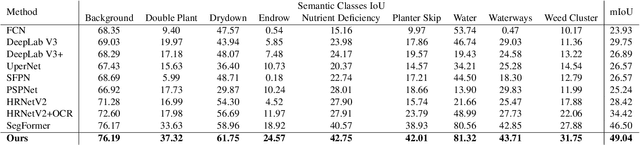
In this paper, we investigate the problem of Semantic Segmentation for agricultural aerial imagery. We observe that the existing methods used for this task are designed without considering two characteristics of the aerial data: (i) the top-down perspective implies that the model cannot rely on a fixed semantic structure of the scene, because the same scene may be experienced with different rotations of the sensor; (ii) there can be a strong imbalance in the distribution of semantic classes because the relevant objects of the scene may appear at extremely different scales (e.g., a field of crops and a small vehicle). We propose a solution to these problems based on two ideas: (i) we use together a set of suitable augmentation and a consistency loss to guide the model to learn semantic representations that are invariant to the photometric and geometric shifts typical of the top-down perspective (Augmentation Invariance); (ii) we use a sampling method (Adaptive Sampling) that selects the training images based on a measure of pixel-wise distribution of classes and actual network confidence. With an extensive set of experiments conducted on the Agriculture-Vision dataset, we demonstrate that our proposed strategies improve the performance of the current state-of-the-art method.
FedDrive: Generalizing Federated Learning to Semantic Segmentation in Autonomous Driving
Feb 28, 2022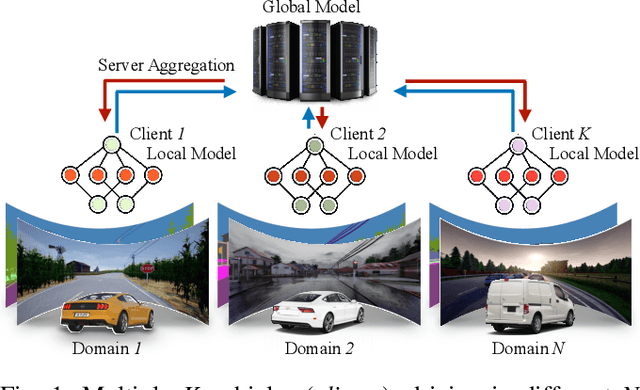


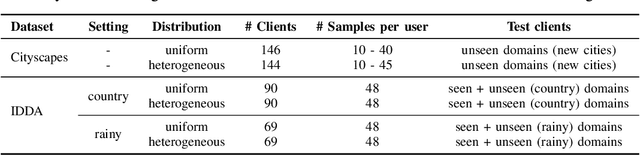
Semantic Segmentation is essential to make self-driving vehicles autonomous, enabling them to understand their surroundings by assigning individual pixels to known categories. However, it operates on sensible data collected from the users' cars; thus, protecting the clients' privacy becomes a primary concern. For similar reasons, Federated Learning has been recently introduced as a new machine learning paradigm aiming to learn a global model while preserving privacy and leveraging data on millions of remote devices. Despite several efforts on this topic, no work has explicitly addressed the challenges of federated learning in semantic segmentation for driving so far. To fill this gap, we propose FedDrive, a new benchmark consisting of three settings and two datasets, incorporating the real-world challenges of statistical heterogeneity and domain generalization. We benchmark state-of-the-art algorithms from the federated learning literature through an in-depth analysis, combining them with style transfer methods to improve their generalization ability. We demonstrate that correctly handling normalization statistics is crucial to deal with the aforementioned challenges. Furthermore, style transfer improves performance when dealing with significant appearance shifts. We plan to make both the code and the benchmark publicly available to the research community.
Learning Semantics for Visual Place Recognition through Multi-Scale Attention
Jan 25, 2022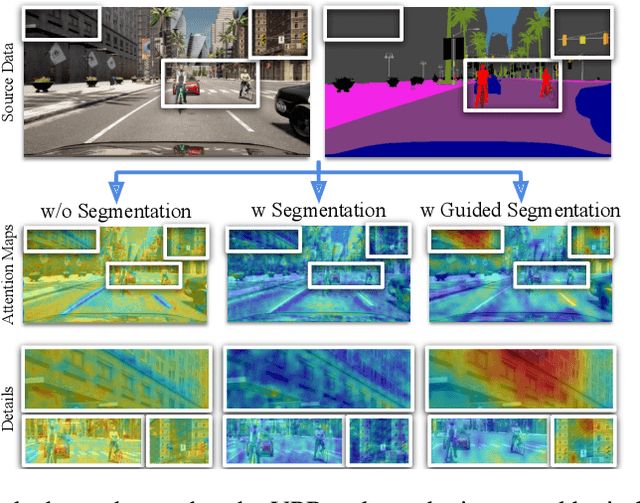
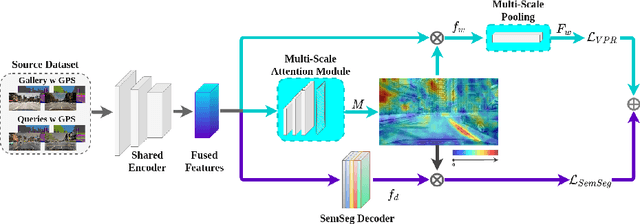
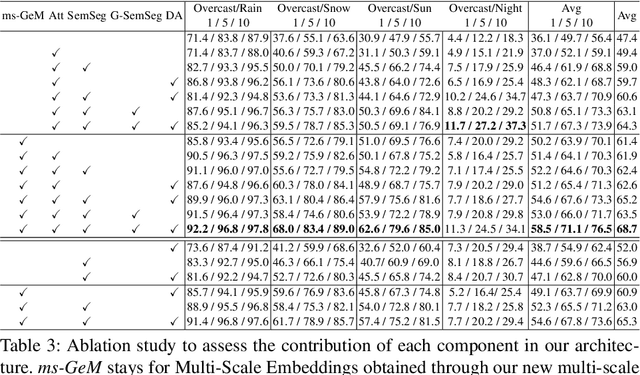
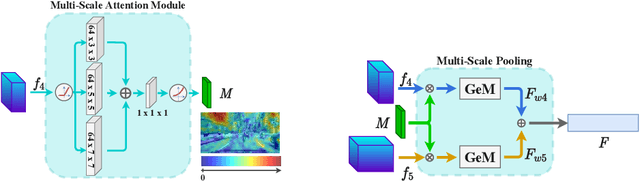
In this paper we address the task of visual place recognition (VPR), where the goal is to retrieve the correct GPS coordinates of a given query image against a huge geotagged gallery. While recent works have shown that building descriptors incorporating semantic and appearance information is beneficial, current state-of-the-art methods opt for a top down definition of the significant semantic content. Here we present the first VPR algorithm that learns robust global embeddings from both visual appearance and semantic content of the data, with the segmentation process being dynamically guided by the recognition of places through a multi-scale attention module. Experiments on various scenarios validate this new approach and demonstrate its performance against state-of-the-art methods. Finally, we propose the first synthetic-world dataset suited for both place recognition and segmentation tasks.
A Contrastive Distillation Approach for Incremental Semantic Segmentation in Aerial Images
Dec 07, 2021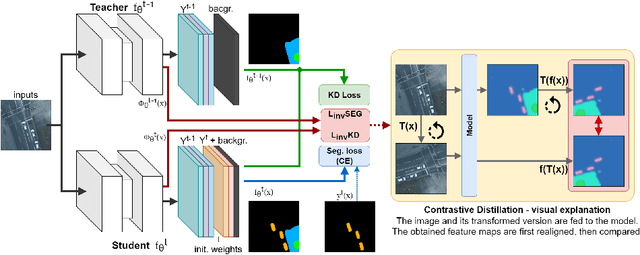
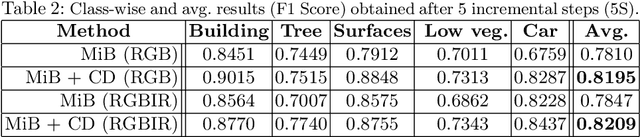
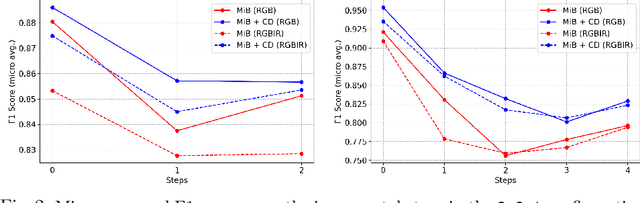
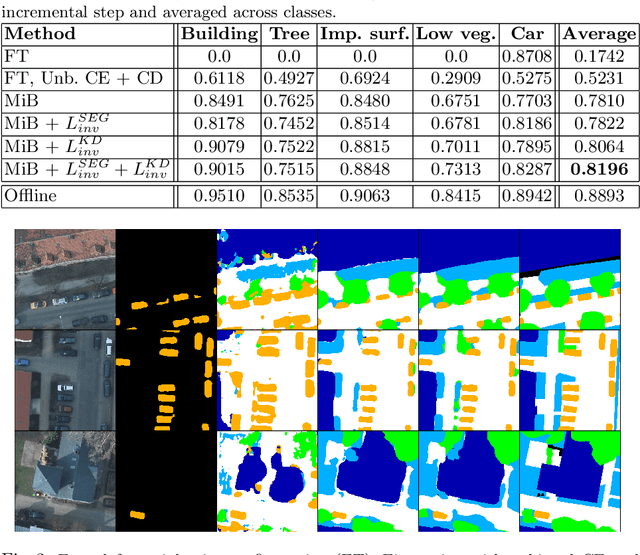
Incremental learning represents a crucial task in aerial image processing, especially given the limited availability of large-scale annotated datasets. A major issue concerning current deep neural architectures is known as catastrophic forgetting, namely the inability to faithfully maintain past knowledge once a new set of data is provided for retraining. Over the years, several techniques have been proposed to mitigate this problem for image classification and object detection. However, only recently the focus has shifted towards more complex downstream tasks such as instance or semantic segmentation. Starting from incremental-class learning for semantic segmentation tasks, our goal is to adapt this strategy to the aerial domain, exploiting a peculiar feature that differentiates it from natural images, namely the orientation. In addition to the standard knowledge distillation approach, we propose a contrastive regularization, where any given input is compared with its augmented version (i.e. flipping and rotations) in order to minimize the difference between the segmentation features produced by both inputs. We show the effectiveness of our solution on the Potsdam dataset, outperforming the incremental baseline in every test. Code available at: https://github.com/edornd/contrastive-distillation.
Incremental Learning in Semantic Segmentation from Image Labels
Dec 03, 2021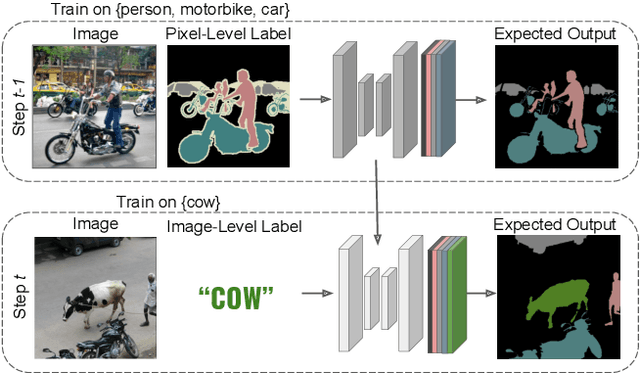
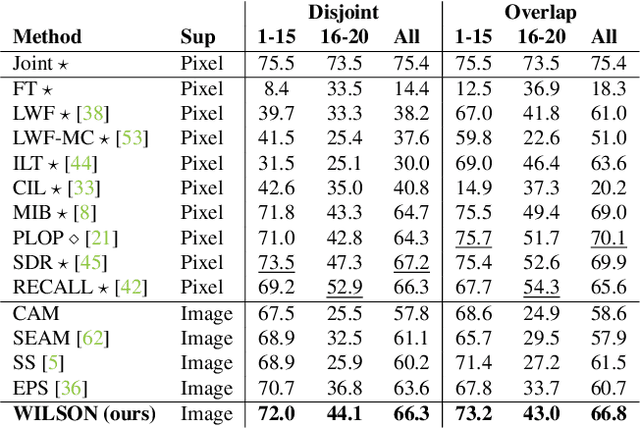
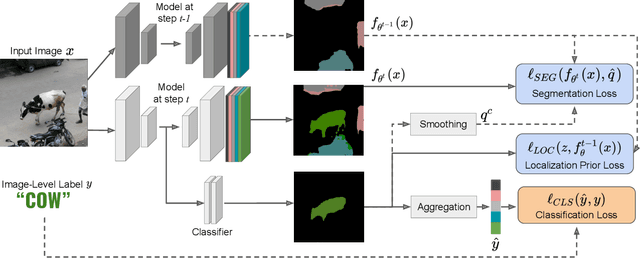
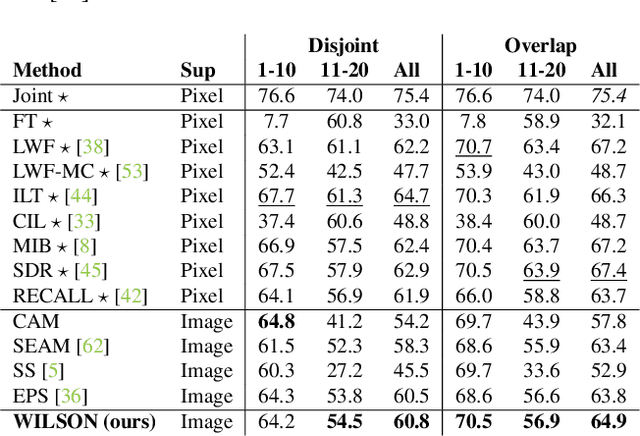
Although existing semantic segmentation approaches achieve impressive results, they still struggle to update their models incrementally as new categories are uncovered. Furthermore, pixel-by-pixel annotations are expensive and time-consuming. This paper proposes a novel framework for Weakly Incremental Learning for Semantic Segmentation, that aims at learning to segment new classes from cheap and largely available image-level labels. As opposed to existing approaches, that need to generate pseudo-labels offline, we use an auxiliary classifier, trained with image-level labels and regularized by the segmentation model, to obtain pseudo-supervision online and update the model incrementally. We cope with the inherent noise in the process by using soft-labels generated by the auxiliary classifier. We demonstrate the effectiveness of our approach on the Pascal VOC and COCO datasets, outperforming offline weakly-supervised methods and obtaining results comparable with incremental learning methods with full supervision.
Reimagine BiSeNet for Real-Time Domain Adaptation in Semantic Segmentation
Oct 22, 2021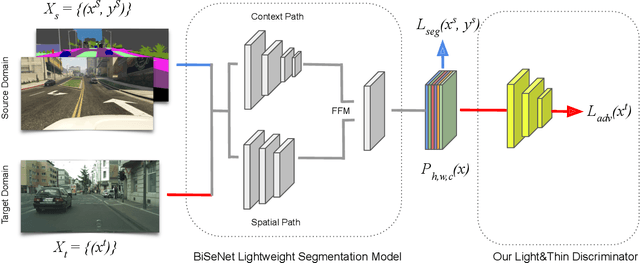



Semantic segmentation models have reached remarkable performance across various tasks. However, this performance is achieved with extremely large models, using powerful computational resources and without considering training and inference time. Real-world applications, on the other hand, necessitate models with minimal memory demands, efficient inference speed, and executable with low-resources embedded devices, such as self-driving vehicles. In this paper, we look at the challenge of real-time semantic segmentation across domains, and we train a model to act appropriately on real-world data even though it was trained on a synthetic realm. We employ a new lightweight and shallow discriminator that was specifically created for this purpose. To the best of our knowledge, we are the first to present a real-time adversarial approach for assessing the domain adaption problem in semantic segmentation. We tested our framework in the two standard protocol: GTA5 to Cityscapes and SYNTHIA to Cityscapes. Code is available at: https://github.com/taveraantonio/RTDA.
Pixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic Segmentation
Oct 22, 2021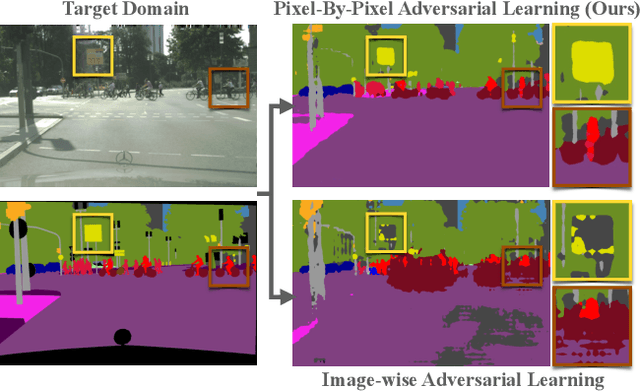
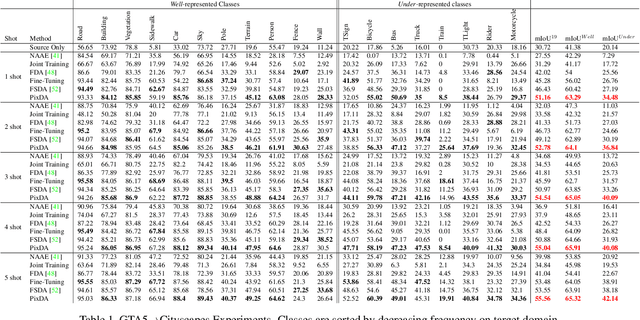
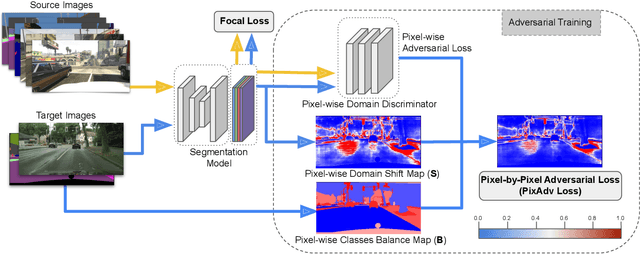
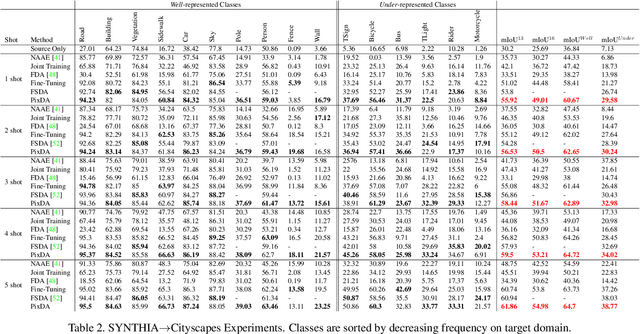
In this paper we consider the task of semantic segmentation in autonomous driving applications. Specifically, we consider the cross-domain few-shot setting where training can use only few real-world annotated images and many annotated synthetic images. In this context, aligning the domains is made more challenging by the pixel-wise class imbalance that is intrinsic in the segmentation and that leads to ignoring the underrepresented classes and overfitting the well represented ones. We address this problem with a novel framework called Pixel-By-Pixel Cross-Domain Alignment (PixDA). We propose a novel pixel-by-pixel domain adversarial loss following three criteria: (i) align the source and the target domain for each pixel, (ii) avoid negative transfer on the correctly represented pixels, and (iii) regularize the training of infrequent classes to avoid overfitting. The pixel-wise adversarial training is assisted by a novel sample selection procedure, that handles the imbalance between source and target data, and a knowledge distillation strategy, that avoids overfitting towards the few target images. We demonstrate on standard synthetic-to-real benchmarks that PixDA outperforms previous state-of-the-art methods in (1-5)-shot settings.