 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking Anomalies in Road-Scene Segmentation
Jul 25, 2023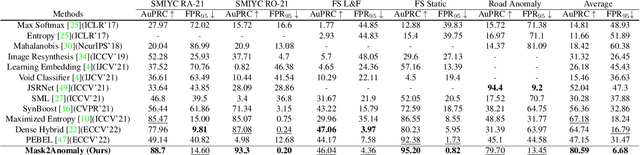
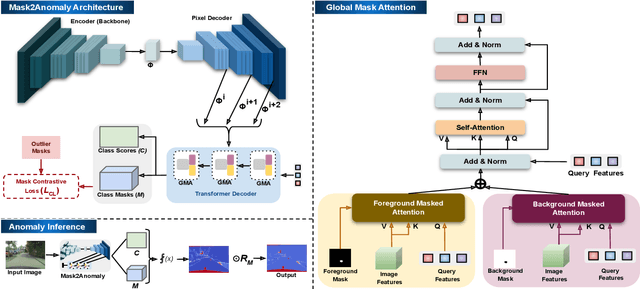
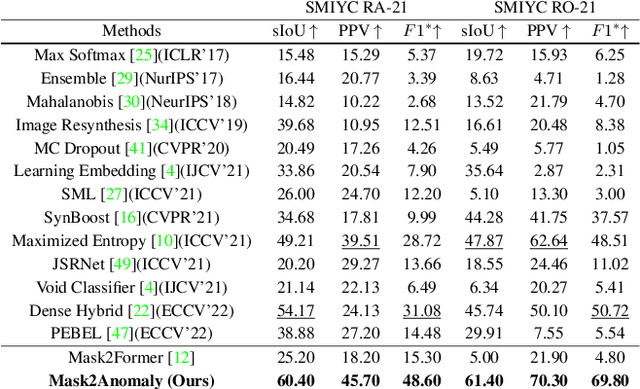

Anomaly segmentation is a critical task for driving applications, and it is approached traditionally as a per-pixel classification problem. However, reasoning individually about each pixel without considering their contextual semantics results in high uncertainty around the objects' boundaries and numerous false positives. We propose a paradigm change by shifting from a per-pixel classification to a mask classification. Our mask-based method, Mask2Anomaly, demonstrates the feasibility of integrating an anomaly detection method in a mask-classification architecture. Mask2Anomaly includes several technical novelties that are designed to improve the detection of anomalies in masks: i) a global masked attention module to focus individually on the foreground and background regions; ii) a mask contrastive learning that maximizes the margin between an anomaly and known classes; and iii) a mask refinement solution to reduce false positives. Mask2Anomaly achieves new state-of-the-art results across a range of benchmarks, both in the per-pixel and component-level evaluations. In particular, Mask2Anomaly reduces the average false positives rate by 60% wrt the previous state-of-the-art. Github page: https://github.com/shyam671/Mask2Anomaly-Unmasking-Anomalies-in-Road-Scene-Segmentation.
Detecting the unknown in Object Detection
Aug 24, 2022
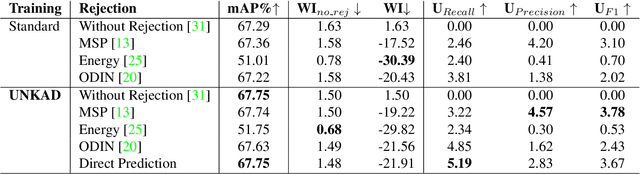

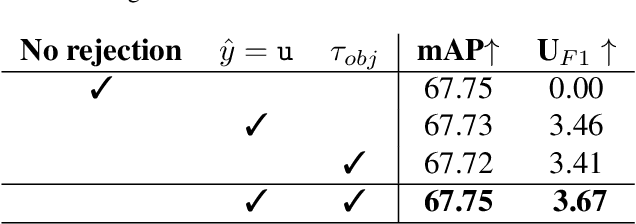
Object detection methods have witnessed impressive improvements in the last years thanks to the design of novel neural network architectures and the availability of large scale datasets. However, current methods have a significant limitation: they are able to detect only the classes observed during training time, that are only a subset of all the classes that a detector may encounter in the real world. Furthermore, the presence of unknown classes is often not considered at training time, resulting in methods not even able to detect that an unknown object is present in the image. In this work, we address the problem of detecting unknown objects, known as open-set object detection. We propose a novel training strategy, called UNKAD, able to predict unknown objects without requiring any annotation of them, exploiting non annotated objects that are already present in the background of training images. In particular, exploiting the four-steps training strategy of Faster R-CNN, UNKAD first identifies and pseudo-labels unknown objects and then uses the pseudo-annotations to train an additional unknown class. While UNKAD can directly detect unknown objects, we further combine it with previous unknown detection techniques, showing that it improves their performance at no costs.
Modeling Missing Annotations for Incremental Learning in Object Detection
Apr 21, 2022
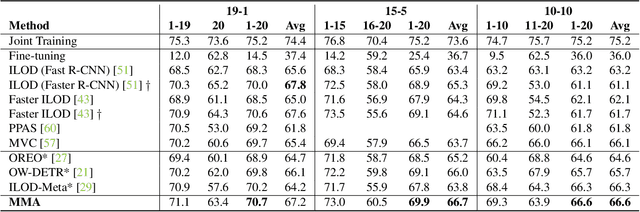
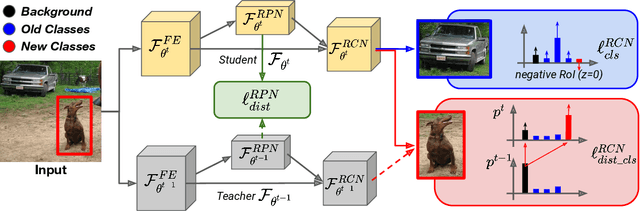

Despite the recent advances in the field of object detection, common architectures are still ill-suited to incrementally detect new categories over time. They are vulnerable to catastrophic forgetting: they forget what has been already learned while updating their parameters in absence of the original training data. Previous works extended standard classification methods in the object detection task, mainly adopting the knowledge distillation framework. However, we argue that object detection introduces an additional problem, which has been overlooked. While objects belonging to new classes are learned thanks to their annotations, if no supervision is provided for other objects that may still be present in the input, the model learns to associate them to background regions. We propose to handle these missing annotations by revisiting the standard knowledge distillation framework. Our approach outperforms current state-of-the-art methods in every setting of the Pascal-VOC dataset. We further propose an extension to instance segmentation, outperforming the other baselines. Code can be found here: https://github.com/fcdl94/MMA
Incremental Learning in Semantic Segmentation from Image Labels
Dec 03, 2021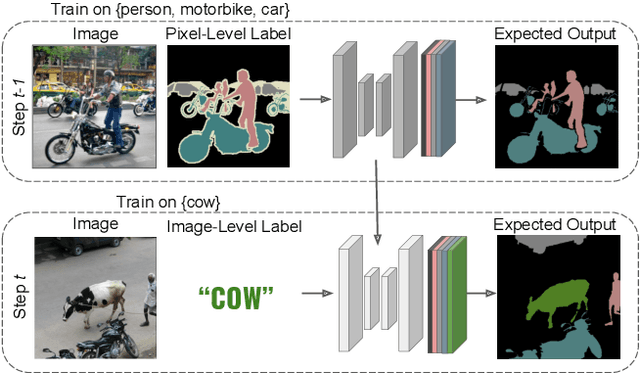
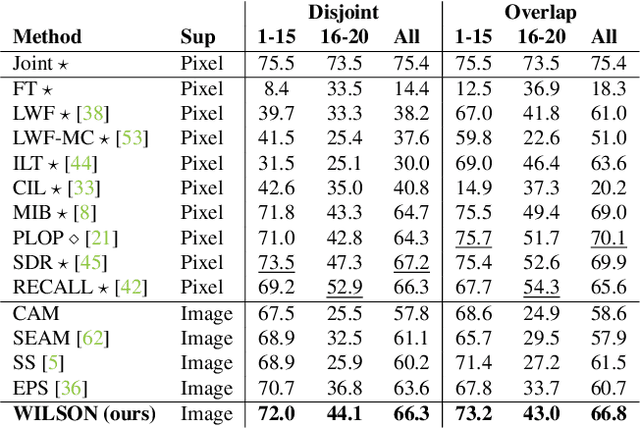
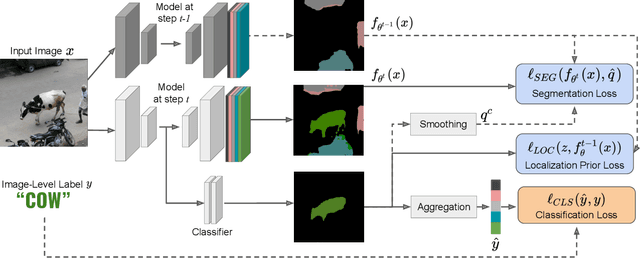
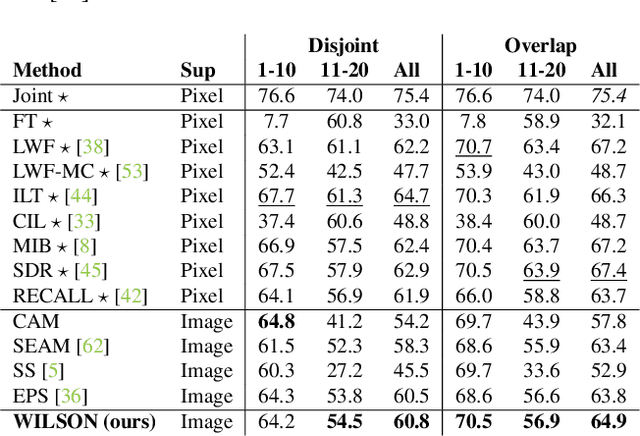
Although existing semantic segmentation approaches achieve impressive results, they still struggle to update their models incrementally as new categories are uncovered. Furthermore, pixel-by-pixel annotations are expensive and time-consuming. This paper proposes a novel framework for Weakly Incremental Learning for Semantic Segmentation, that aims at learning to segment new classes from cheap and largely available image-level labels. As opposed to existing approaches, that need to generate pseudo-labels offline, we use an auxiliary classifier, trained with image-level labels and regularized by the segmentation model, to obtain pseudo-supervision online and update the model incrementally. We cope with the inherent noise in the process by using soft-labels generated by the auxiliary classifier. We demonstrate the effectiveness of our approach on the Pascal VOC and COCO datasets, outperforming offline weakly-supervised methods and obtaining results comparable with incremental learning methods with full supervision.
On the Challenges of Open World Recognitionunder Shifting Visual Domains
Jul 09, 2021



Robotic visual systems operating in the wild must act in unconstrained scenarios, under different environmental conditions while facing a variety of semantic concepts, including unknown ones. To this end, recent works tried to empower visual object recognition methods with the capability to i) detect unseen concepts and ii) extended their knowledge over time, as images of new semantic classes arrive. This setting, called Open World Recognition (OWR), has the goal to produce systems capable of breaking the semantic limits present in the initial training set. However, this training set imposes to the system not only its own semantic limits, but also environmental ones, due to its bias toward certain acquisition conditions that do not necessarily reflect the high variability of the real-world. This discrepancy between training and test distribution is called domain-shift. This work investigates whether OWR algorithms are effective under domain-shift, presenting the first benchmark setup for assessing fairly the performances of OWR algorithms, with and without domain-shift. We then use this benchmark to conduct analyses in various scenarios, showing how existing OWR algorithms indeed suffer a severe performance degradation when train and test distributions differ. Our analysis shows that this degradation is only slightly mitigated by coupling OWR with domain generalization techniques, indicating that the mere plug-and-play of existing algorithms is not enough to recognize new and unknown categories in unseen domains. Our results clearly point toward open issues and future research directions, that need to be investigated for building robot visual systems able to function reliably under these challenging yet very real conditions. Code available at https://github.com/DarioFontanel/OWR-VisualDomains
Detecting Anomalies in Semantic Segmentation with Prototypes
Jun 01, 2021
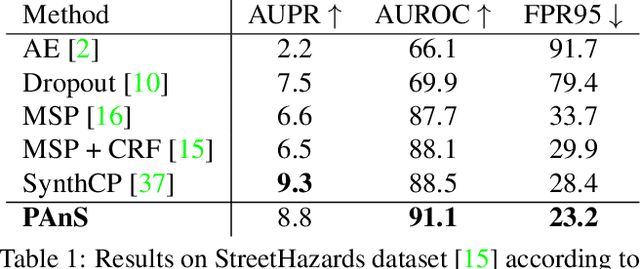


Traditional semantic segmentation methods can recognize at test time only the classes that are present in the training set. This is a significant limitation, especially for semantic segmentation algorithms mounted on intelligent autonomous systems, deployed in realistic settings. Regardless of how many classes the system has seen at training time, it is inevitable that unexpected, unknown objects will appear at test time. The failure in identifying such anomalies may lead to incorrect, even dangerous behaviors of the autonomous agent equipped with such segmentation model when deployed in the real world. Current state of the art of anomaly segmentation uses generative models, exploiting their incapability to reconstruct patterns unseen during training. However, training these models is expensive, and their generated artifacts may create false anomalies. In this paper we take a different route and we propose to address anomaly segmentation through prototype learning. Our intuition is that anomalous pixels are those that are dissimilar to all class prototypes known by the model. We extract class prototypes from the training data in a lightweight manner using a cosine similarity-based classifier. Experiments on StreetHazards show that our approach achieves the new state of the art, with a significant margin over previous works, despite the reduced computational overhead. Code is available at https://github.com/DarioFontanel/PAnS.
Boosting Deep Open World Recognition by Clustering
Apr 20, 2020
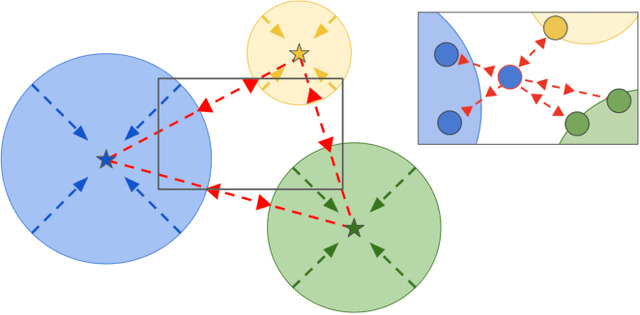


While convolutional neural networks have brought significant advances in robot vision, their ability is often limited to closed world scenarios, where the number of semantic concepts to be recognized is determined by the available training set. Since it is practically impossible to capture all possible semantic concepts present in the real world in a single training set, we need to break the closed world assumption, equipping our robot with the capability to act in an open world. To provide such ability, a robot vision system should be able to (i) identify whether an instance does not belong to the set of known categories (i.e. open set recognition), and (ii) extend its knowledge to learn new classes over time (i.e. incremental learning). In this work, we show how we can boost the performance of deep open world recognition algorithms by means of a new loss formulation enforcing a global to local clustering of class-specific features. In particular, a first loss term, i.e. global clustering, forces the network to map samples closer to the class centroid they belong to while the second one, local clustering, shapes the representation space in such a way that samples of the same class get closer in the representation space while pushing away neighbours belonging to other classes. Moreover, we propose a strategy to learn class-specific rejection thresholds, instead of heuristically estimating a single global threshold, as in previous works. Experiments on RGB-D Object and Core50 datasets show the effectiveness of our approach.