 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-by-Pixel Cross-Domain Alignment for Few-Shot Semantic Segmentation
Paper and Code
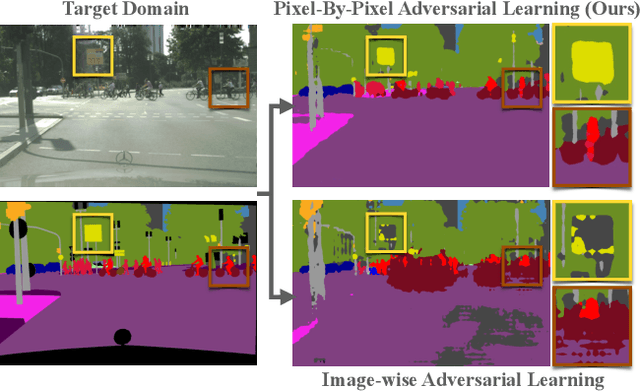
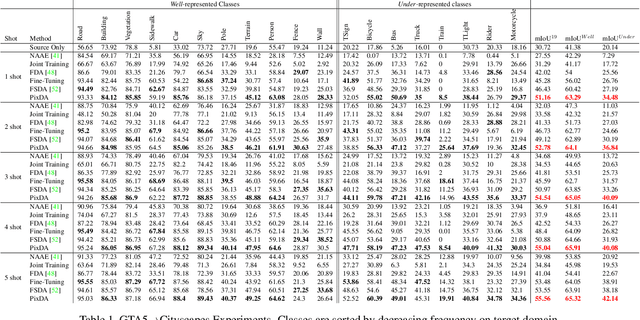
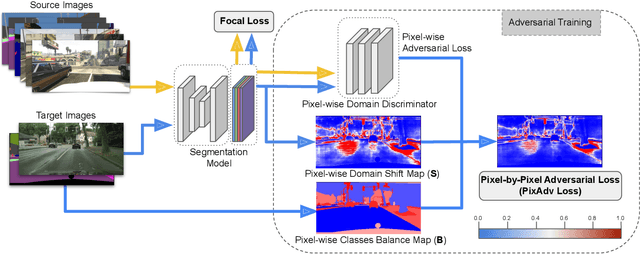
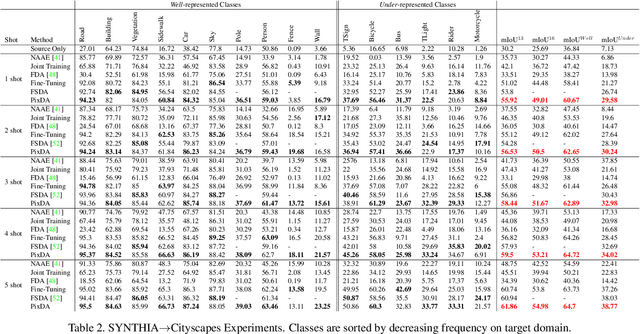
In this paper we consider the task of semantic segmentation in autonomous driving applications. Specifically, we consider the cross-domain few-shot setting where training can use only few real-world annotated images and many annotated synthetic images. In this context, aligning the domains is made more challenging by the pixel-wise class imbalance that is intrinsic in the segmentation and that leads to ignoring the underrepresented classes and overfitting the well represented ones. We address this problem with a novel framework called Pixel-By-Pixel Cross-Domain Alignment (PixDA). We propose a novel pixel-by-pixel domain adversarial loss following three criteria: (i) align the source and the target domain for each pixel, (ii) avoid negative transfer on the correctly represented pixels, and (iii) regularize the training of infrequent classes to avoid overfitting. The pixel-wise adversarial training is assisted by a novel sample selection procedure, that handles the imbalance between source and target data, and a knowledge distillation strategy, that avoids overfitting towards the few target images. We demonstrate on standard synthetic-to-real benchmarks that PixDA outperforms previous state-of-the-art methods in (1-5)-shot settings.