 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurin3D: Evaluating Adaptation Strategies under Label Scarcity in Urban LiDAR Segmentation with Semi-Supervised Techniques
Apr 08, 20253D semantic segmentation plays a critical role in urban modelling, enabling detailed understanding and mapping of city environments. In this paper, we introduce Turin3D: a new aerial LiDAR dataset for point cloud semantic segmentation covering an area of around 1.43 km2 in the city centre of Turin with almost 70M points. We describe the data collection process and compare Turin3D with others previously proposed in the literature. We did not fully annotate the dataset due to the complexity and time-consuming nature of the process; however, a manual annotation process was performed on the validation and test sets, to enable a reliable evaluation of the proposed techniques. We first benchmark the performances of several point cloud semantic segmentation models, trained on the existing datasets, when tested on Turin3D, and then improve their performances by applying a semi-supervised learning technique leveraging the unlabelled training set. The dataset will be publicly available to support research in outdoor point cloud segmentation, with particular relevance for self-supervised and semi-supervised learning approaches given the absence of ground truth annotations for the training set.
Land Cover Segmentation with Sparse Annotations from Sentinel-2 Imagery
Jun 28, 2023Land cover (LC) segmentation plays a critical role in various applications, including environmental analysis and natural disaster management. However, generating accurate LC maps is a complex and time-consuming task that requires the expertise of multiple annotators and regular updates to account for environmental changes. In this work, we introduce SPADA, a framework for fuel map delineation that addresses the challenges associated with LC segmentation using sparse annotations and domain adaptation techniques for semantic segmentation. Performance evaluations using reliable ground truths, such as LUCAS and Urban Atlas, demonstrate the technique's effectiveness. SPADA outperforms state-of-the-art semantic segmentation approaches as well as third-party products, achieving a mean Intersection over Union (IoU) score of 42.86 and an F1 score of 67.93 on Urban Atlas and LUCAS, respectively.
Hierarchical Instance Mixing across Domains in Aerial Segmentation
Oct 12, 2022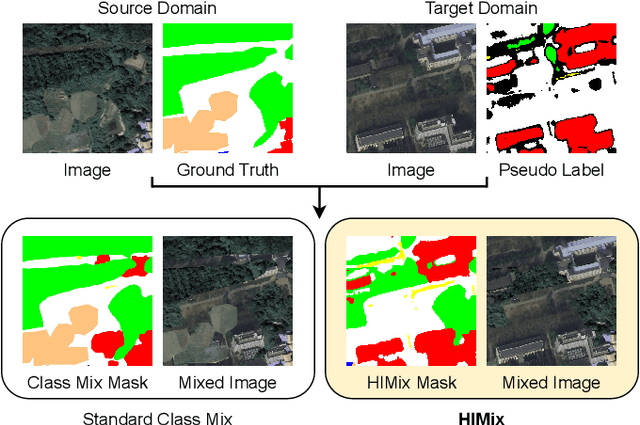
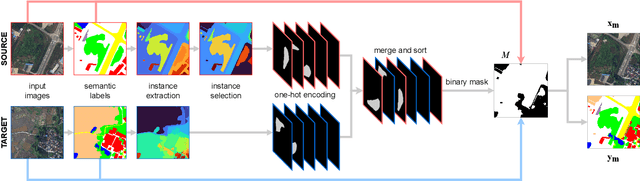

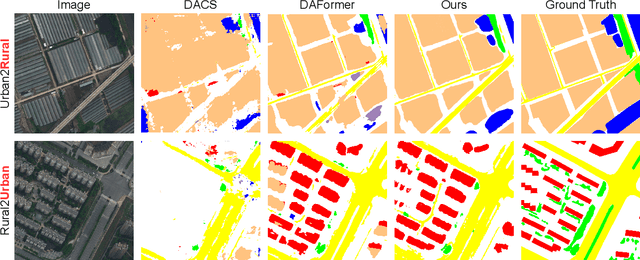
We investigate the task of unsupervised domain adaptation in aerial semantic segmentation and discover that the current state-of-the-art algorithms designed for autonomous driving based on domain mixing do not translate well to the aerial setting. This is due to two factors: (i) a large disparity in the extension of the semantic categories, which causes a domain imbalance in the mixed image, and (ii) a weaker structural consistency in aerial scenes than in driving scenes since the same scene might be viewed from different perspectives and there is no well-defined and repeatable structure of the semantic elements in the images. Our solution to these problems is composed of: (i) a new mixing strategy for aerial segmentation across domains called Hierarchical Instance Mixing (HIMix), which extracts a set of connected components from each semantic mask and mixes them according to a semantic hierarchy and, (ii) a twin-head architecture in which two separate segmentation heads are fed with variations of the same images in a contrastive fashion to produce finer segmentation maps. We conduct extensive experiments on the LoveDA benchmark, where our solution outperforms the current state-of-the-art.