 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMARS: Annotating Remote Sensing Images for Disaster Management using Foundation Models
May 30, 2024



Very-High Resolution (VHR) remote sensing imagery is increasingly accessible, but often lacks annotations for effective machine learning applications. Recent foundation models like GroundingDINO and Segment Anything (SAM) provide opportunities to automatically generate annotations. This study introduces FMARS (Foundation Model Annotations in Remote Sensing), a methodology leveraging VHR imagery and foundation models for fast and robust annotation. We focus on disaster management and provide a large-scale dataset with labels obtained from pre-event imagery over 19 disaster events, derived from the Maxar Open Data initiative. We train segmentation models on the generated labels, using Unsupervised Domain Adaptation (UDA) techniques to increase transferability to real-world scenarios. Our results demonstrate the effectiveness of leveraging foundation models to automatically annotate remote sensing data at scale, enabling robust downstream models for critical applications. Code and dataset are available at \url{https://github.com/links-ads/igarss-fmars}.
Robust Burned Area Delineation through Multitask Learning
Sep 15, 2023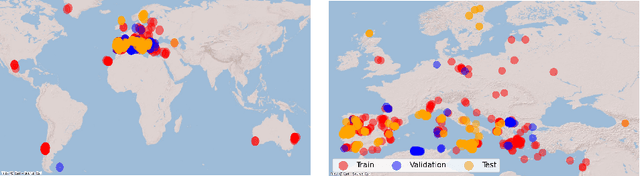
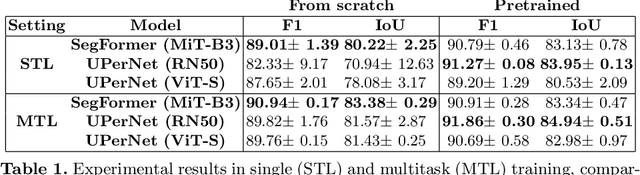
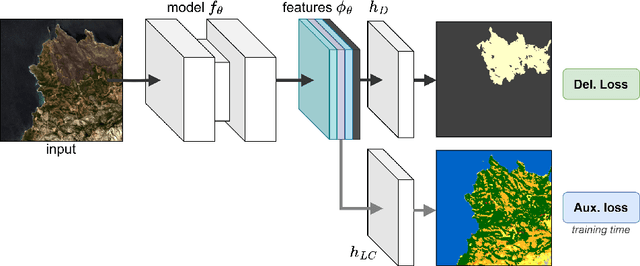
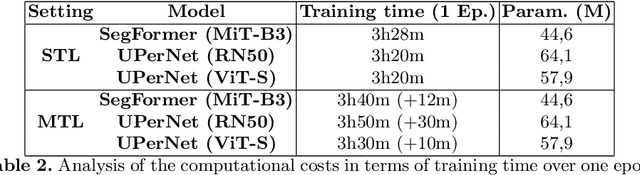
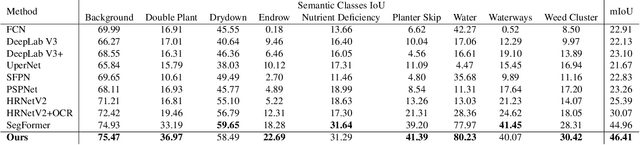
In recent years, wildfires have posed a significant challenge due to their increasing frequency and severity. For this reason, accurate delineation of burned areas is crucial for environmental monitoring and post-fire assessment. However, traditional approaches relying on binary segmentation models often struggle to achieve robust and accurate results, especially when trained from scratch, due to limited resources and the inherent imbalance of this segmentation task. We propose to address these limitations in two ways: first, we construct an ad-hoc dataset to cope with the limited resources, combining information from Sentinel-2 feeds with Copernicus activations and other data sources. In this dataset, we provide annotations for multiple tasks, including burned area delineation and land cover segmentation. Second, we propose a multitask learning framework that incorporates land cover classification as an auxiliary task to enhance the robustness and performance of the burned area segmentation models. We compare the performance of different models, including UPerNet and SegFormer, demonstrating the effectiveness of our approach in comparison to standard binary segmentation.
A Multimodal Supervised Machine Learning Approach for Satellite-based Wildfire Identification in Europe
Jul 27, 2023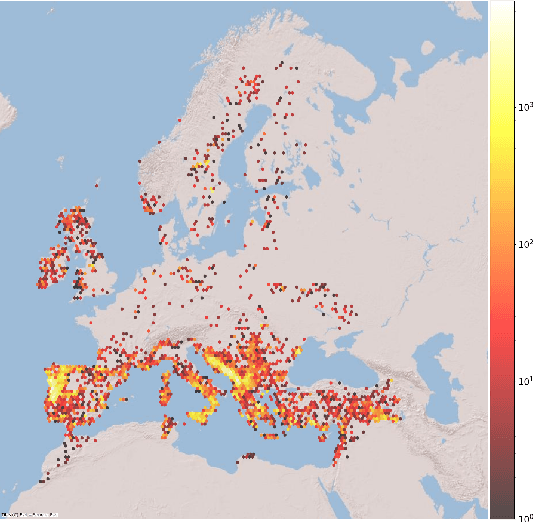

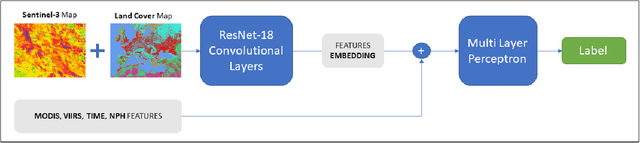

The increasing frequency of catastrophic natural events, such as wildfires, calls for the development of rapid and automated wildfire detection systems. In this paper, we propose a wildfire identification solution to improve the accuracy of automated satellite-based hotspot detection systems by leveraging multiple information sources. We cross-reference the thermal anomalies detected by the Moderate-resolution Imaging Spectroradiometer (MODIS) and the Visible Infrared Imaging Radiometer Suite (VIIRS) hotspot services with the European Forest Fire Information System (EFFIS) database to construct a large-scale hotspot dataset for wildfire-related studies in Europe. Then, we propose a novel multimodal supervised machine learning approach to disambiguate hotspot detections, distinguishing between wildfires and other events. Our methodology includes the use of multimodal data sources, such as the ERSI annual Land Use Land Cover (LULC) and the Copernicus Sentinel-3 data. Experimental results demonstrate the effectiveness of our approach in the task of wildfire identification.
Land Cover Segmentation with Sparse Annotations from Sentinel-2 Imagery
Jun 28, 2023Land cover (LC) segmentation plays a critical role in various applications, including environmental analysis and natural disaster management. However, generating accurate LC maps is a complex and time-consuming task that requires the expertise of multiple annotators and regular updates to account for environmental changes. In this work, we introduce SPADA, a framework for fuel map delineation that addresses the challenges associated with LC segmentation using sparse annotations and domain adaptation techniques for semantic segmentation. Performance evaluations using reliable ground truths, such as LUCAS and Urban Atlas, demonstrate the technique's effectiveness. SPADA outperforms state-of-the-art semantic segmentation approaches as well as third-party products, achieving a mean Intersection over Union (IoU) score of 42.86 and an F1 score of 67.93 on Urban Atlas and LUCAS, respectively.
Hierarchical Instance Mixing across Domains in Aerial Segmentation
Oct 12, 2022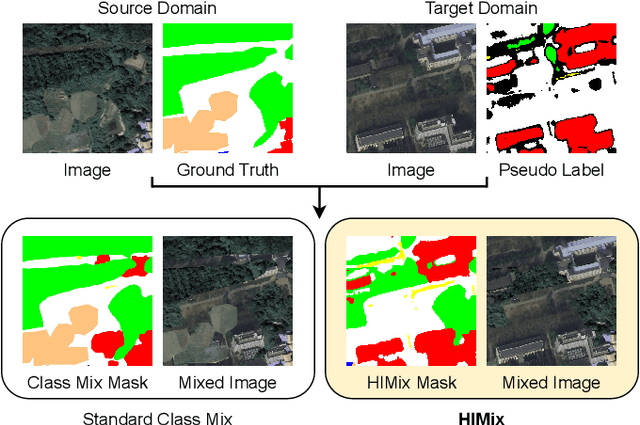
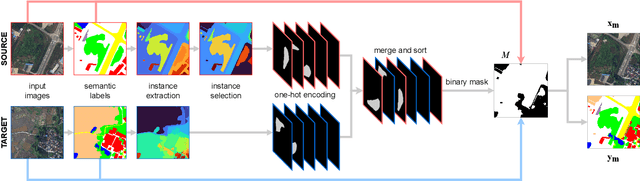

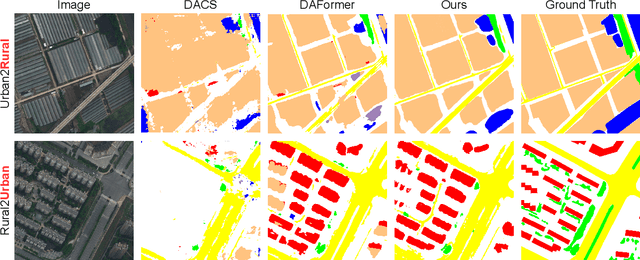
We investigate the task of unsupervised domain adaptation in aerial semantic segmentation and discover that the current state-of-the-art algorithms designed for autonomous driving based on domain mixing do not translate well to the aerial setting. This is due to two factors: (i) a large disparity in the extension of the semantic categories, which causes a domain imbalance in the mixed image, and (ii) a weaker structural consistency in aerial scenes than in driving scenes since the same scene might be viewed from different perspectives and there is no well-defined and repeatable structure of the semantic elements in the images. Our solution to these problems is composed of: (i) a new mixing strategy for aerial segmentation across domains called Hierarchical Instance Mixing (HIMix), which extracts a set of connected components from each semantic mask and mixes them according to a semantic hierarchy and, (ii) a twin-head architecture in which two separate segmentation heads are fed with variations of the same images in a contrastive fashion to produce finer segmentation maps. We conduct extensive experiments on the LoveDA benchmark, where our solution outperforms the current state-of-the-art.
Augmentation Invariance and Adaptive Sampling in Semantic Segmentation of Agricultural Aerial Images
Apr 17, 2022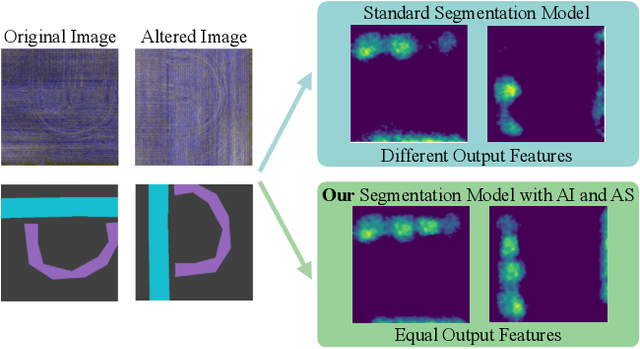
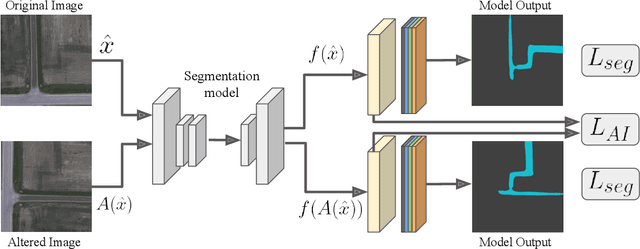
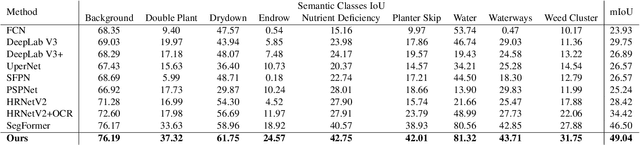
In this paper, we investigate the problem of Semantic Segmentation for agricultural aerial imagery. We observe that the existing methods used for this task are designed without considering two characteristics of the aerial data: (i) the top-down perspective implies that the model cannot rely on a fixed semantic structure of the scene, because the same scene may be experienced with different rotations of the sensor; (ii) there can be a strong imbalance in the distribution of semantic classes because the relevant objects of the scene may appear at extremely different scales (e.g., a field of crops and a small vehicle). We propose a solution to these problems based on two ideas: (i) we use together a set of suitable augmentation and a consistency loss to guide the model to learn semantic representations that are invariant to the photometric and geometric shifts typical of the top-down perspective (Augmentation Invariance); (ii) we use a sampling method (Adaptive Sampling) that selects the training images based on a measure of pixel-wise distribution of classes and actual network confidence. With an extensive set of experiments conducted on the Agriculture-Vision dataset, we demonstrate that our proposed strategies improve the performance of the current state-of-the-art method.
A Contrastive Distillation Approach for Incremental Semantic Segmentation in Aerial Images
Dec 07, 2021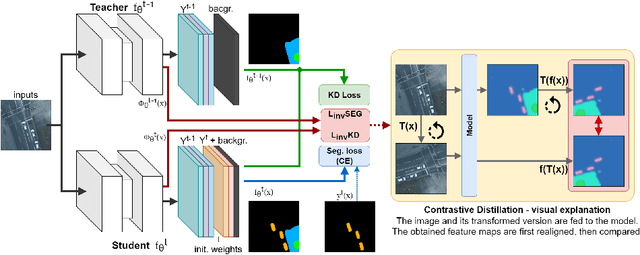
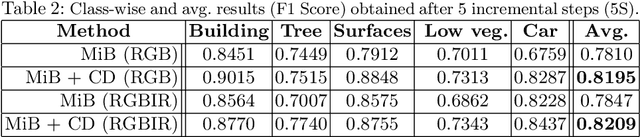
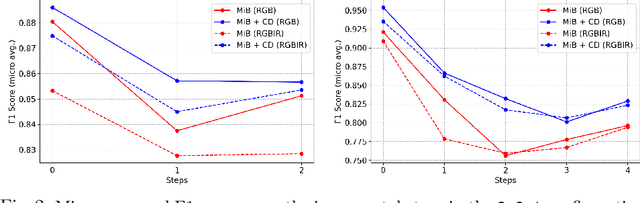
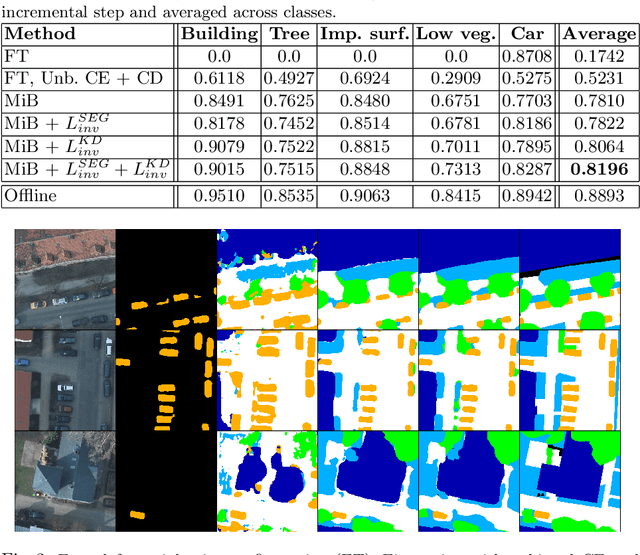
Incremental learning represents a crucial task in aerial image processing, especially given the limited availability of large-scale annotated datasets. A major issue concerning current deep neural architectures is known as catastrophic forgetting, namely the inability to faithfully maintain past knowledge once a new set of data is provided for retraining. Over the years, several techniques have been proposed to mitigate this problem for image classification and object detection. However, only recently the focus has shifted towards more complex downstream tasks such as instance or semantic segmentation. Starting from incremental-class learning for semantic segmentation tasks, our goal is to adapt this strategy to the aerial domain, exploiting a peculiar feature that differentiates it from natural images, namely the orientation. In addition to the standard knowledge distillation approach, we propose a contrastive regularization, where any given input is compared with its augmented version (i.e. flipping and rotations) in order to minimize the difference between the segmentation features produced by both inputs. We show the effectiveness of our solution on the Potsdam dataset, outperforming the incremental baseline in every test. Code available at: https://github.com/edornd/contrastive-distillation.