 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Temperature Prediction Using Remote Sensing Data Via Convolutional Neural Network
May 31, 2024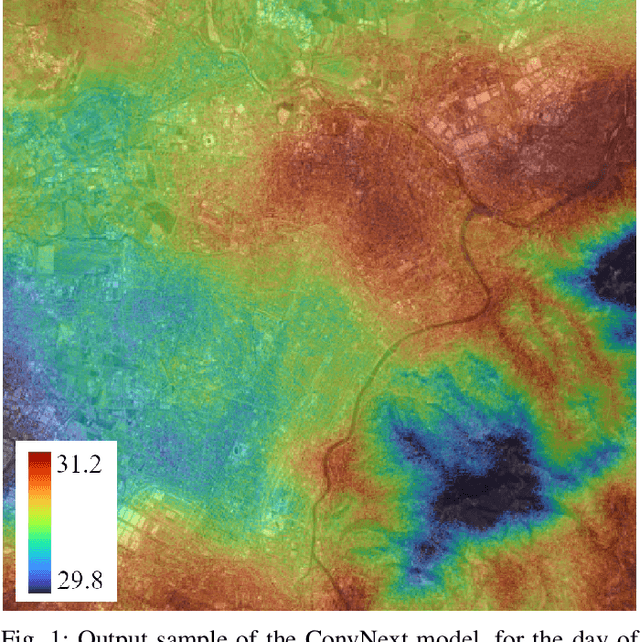
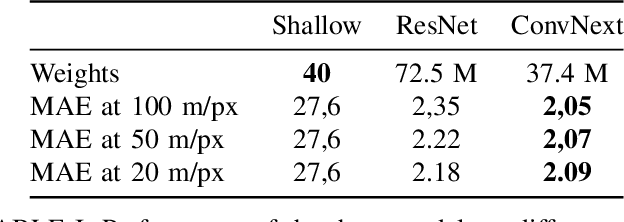
Urban heat islands, defined as specific zones exhibiting substantially higher temperatures than their immediate environs, pose significant threats to environmental sustainability and public health. This study introduces a novel machine-learning model that amalgamates data from the Sentinel-3 satellite, meteorological predictions, and additional remote sensing inputs. The primary aim is to generate detailed spatiotemporal maps that forecast the peak temperatures within a 24-hour period in Turin. Experimental results validate the model's proficiency in predicting temperature patterns, achieving a Mean Absolute Error (MAE) of 2.09 degrees Celsius for the year 2023 at a resolution of 20 meters per pixel, thereby enriching our knowledge of urban climatic behavior. This investigation enhances the understanding of urban microclimates, emphasizing the importance of cross-disciplinary data integration, and laying the groundwork for informed policy-making aimed at alleviating the negative impacts of extreme urban temperatures.
Rapid Wildfire Hotspot Detection Using Self-Supervised Learning on Temporal Remote Sensing Data
May 30, 2024
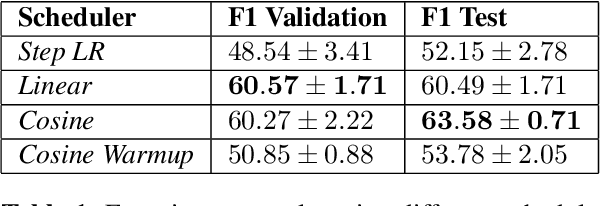

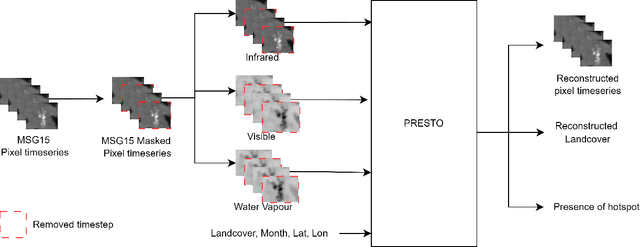
Rapid detection and well-timed intervention are essential to mitigate the impacts of wildfires. Leveraging remote sensed data from satellite networks and advanced AI models to automatically detect hotspots (i.e., thermal anomalies caused by active fires) is an effective way to build wildfire monitoring systems. In this work, we propose a novel dataset containing time series of remotely sensed data related to European fire events and a Self-Supervised Learning (SSL)-based model able to analyse multi-temporal data and identify hotspots in potentially near real time. We train and evaluate the performance of our model using our dataset and Thraws, a dataset of thermal anomalies including several fire events, obtaining an F1 score of 63.58.
Urban Air Pollution Forecasting: a Machine Learning Approach leveraging Satellite Observations and Meteorological Forecasts
May 30, 2024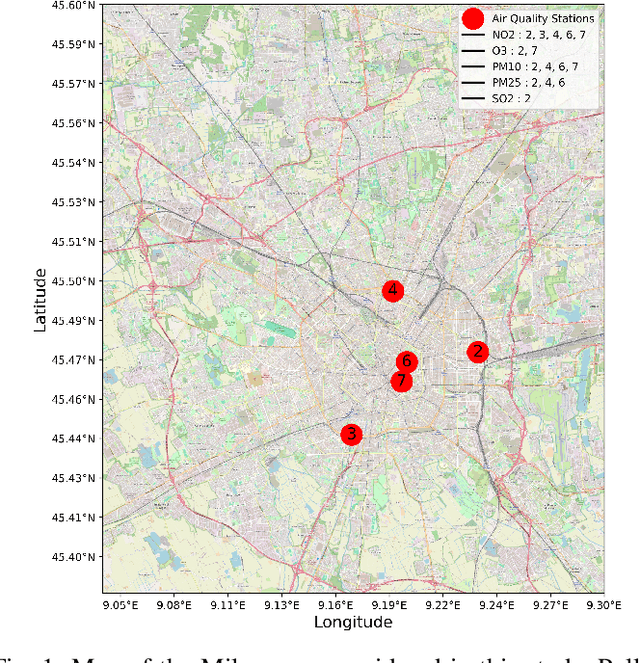
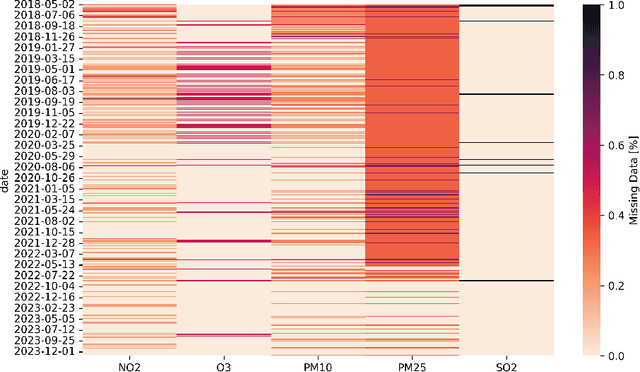
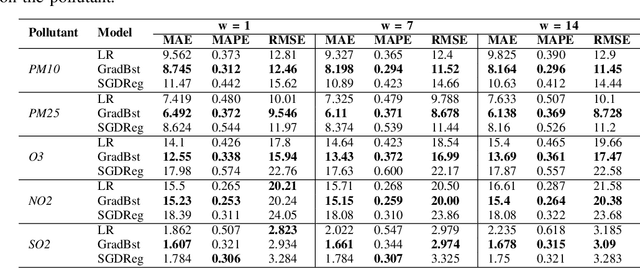
Air pollution poses a significant threat to public health and well-being, particularly in urban areas. This study introduces a series of machine-learning models that integrate data from the Sentinel-5P satellite, meteorological conditions, and topological characteristics to forecast future levels of five major pollutants. The investigation delineates the process of data collection, detailing the combination of diverse data sources utilized in the study. Through experiments conducted in the Milan metropolitan area, the models demonstrate their efficacy in predicting pollutant levels for the forthcoming day, achieving a percentage error of around 30%. The proposed models are advantageous as they are independent of monitoring stations, facilitating their use in areas without existing infrastructure. Additionally, we have released the collected dataset to the public, aiming to stimulate further research in this field. This research contributes to advancing our understanding of urban air quality dynamics and emphasizes the importance of amalgamating satellite, meteorological, and topographical data to develop robust pollution forecasting models.
Landslide mapping from Sentinel-2 imagery through change detection
May 30, 2024
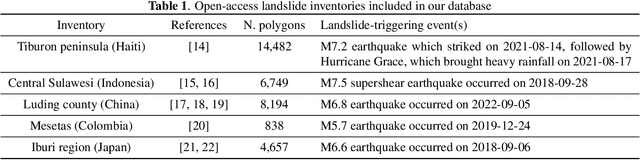
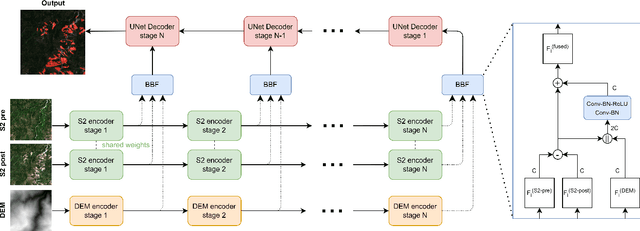
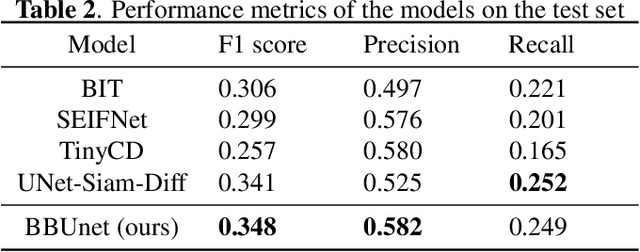
Landslides are one of the most critical and destructive geohazards. Widespread development of human activities and settlements combined with the effects of climate change on weather are resulting in a high increase in the frequency and destructive power of landslides, making them a major threat to human life and the economy. In this paper, we explore methodologies to map newly-occurred landslides using Sentinel-2 imagery automatically. All approaches presented are framed as a bi-temporal change detection problem, requiring only a pair of Sentinel-2 images, taken respectively before and after a landslide-triggering event. Furthermore, we introduce a novel deep learning architecture for fusing Sentinel-2 bi-temporal image pairs with Digital Elevation Model (DEM) data, showcasing its promising performances w.r.t. other change detection models in the literature. As a parallel task, we address limitations in existing datasets by creating a novel geodatabase, which includes manually validated open-access landslide inventories over heterogeneous ecoregions of the world. We release both code and dataset with an open-source license.
FMARS: Annotating Remote Sensing Images for Disaster Management using Foundation Models
May 30, 2024



Very-High Resolution (VHR) remote sensing imagery is increasingly accessible, but often lacks annotations for effective machine learning applications. Recent foundation models like GroundingDINO and Segment Anything (SAM) provide opportunities to automatically generate annotations. This study introduces FMARS (Foundation Model Annotations in Remote Sensing), a methodology leveraging VHR imagery and foundation models for fast and robust annotation. We focus on disaster management and provide a large-scale dataset with labels obtained from pre-event imagery over 19 disaster events, derived from the Maxar Open Data initiative. We train segmentation models on the generated labels, using Unsupervised Domain Adaptation (UDA) techniques to increase transferability to real-world scenarios. Our results demonstrate the effectiveness of leveraging foundation models to automatically annotate remote sensing data at scale, enabling robust downstream models for critical applications. Code and dataset are available at \url{https://github.com/links-ads/igarss-fmars}.
Robust Burned Area Delineation through Multitask Learning
Sep 15, 2023
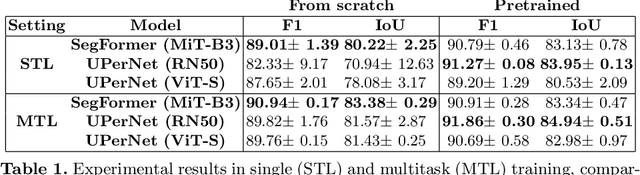
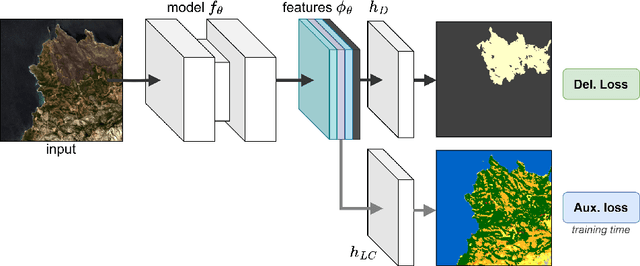
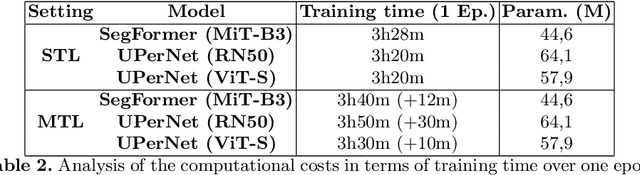
In recent years, wildfires have posed a significant challenge due to their increasing frequency and severity. For this reason, accurate delineation of burned areas is crucial for environmental monitoring and post-fire assessment. However, traditional approaches relying on binary segmentation models often struggle to achieve robust and accurate results, especially when trained from scratch, due to limited resources and the inherent imbalance of this segmentation task. We propose to address these limitations in two ways: first, we construct an ad-hoc dataset to cope with the limited resources, combining information from Sentinel-2 feeds with Copernicus activations and other data sources. In this dataset, we provide annotations for multiple tasks, including burned area delineation and land cover segmentation. Second, we propose a multitask learning framework that incorporates land cover classification as an auxiliary task to enhance the robustness and performance of the burned area segmentation models. We compare the performance of different models, including UPerNet and SegFormer, demonstrating the effectiveness of our approach in comparison to standard binary segmentation.
A Multimodal Supervised Machine Learning Approach for Satellite-based Wildfire Identification in Europe
Jul 27, 2023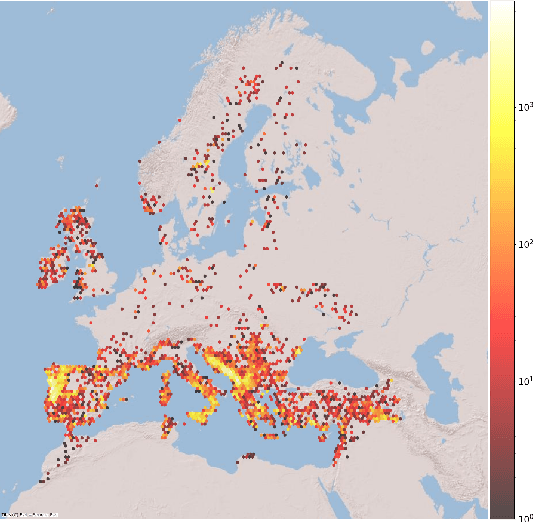

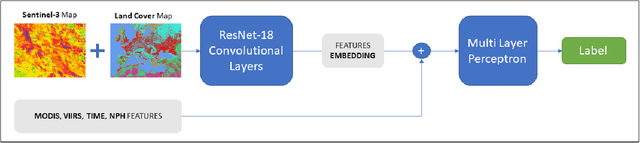

The increasing frequency of catastrophic natural events, such as wildfires, calls for the development of rapid and automated wildfire detection systems. In this paper, we propose a wildfire identification solution to improve the accuracy of automated satellite-based hotspot detection systems by leveraging multiple information sources. We cross-reference the thermal anomalies detected by the Moderate-resolution Imaging Spectroradiometer (MODIS) and the Visible Infrared Imaging Radiometer Suite (VIIRS) hotspot services with the European Forest Fire Information System (EFFIS) database to construct a large-scale hotspot dataset for wildfire-related studies in Europe. Then, we propose a novel multimodal supervised machine learning approach to disambiguate hotspot detections, distinguishing between wildfires and other events. Our methodology includes the use of multimodal data sources, such as the ERSI annual Land Use Land Cover (LULC) and the Copernicus Sentinel-3 data. Experimental results demonstrate the effectiveness of our approach in the task of wildfire identification.
Land Cover Segmentation with Sparse Annotations from Sentinel-2 Imagery
Jun 28, 2023Land cover (LC) segmentation plays a critical role in various applications, including environmental analysis and natural disaster management. However, generating accurate LC maps is a complex and time-consuming task that requires the expertise of multiple annotators and regular updates to account for environmental changes. In this work, we introduce SPADA, a framework for fuel map delineation that addresses the challenges associated with LC segmentation using sparse annotations and domain adaptation techniques for semantic segmentation. Performance evaluations using reliable ground truths, such as LUCAS and Urban Atlas, demonstrate the technique's effectiveness. SPADA outperforms state-of-the-art semantic segmentation approaches as well as third-party products, achieving a mean Intersection over Union (IoU) score of 42.86 and an F1 score of 67.93 on Urban Atlas and LUCAS, respectively.
Category Theory for Autonomous Robots: The Marathon 2 Use Case
Mar 02, 2023
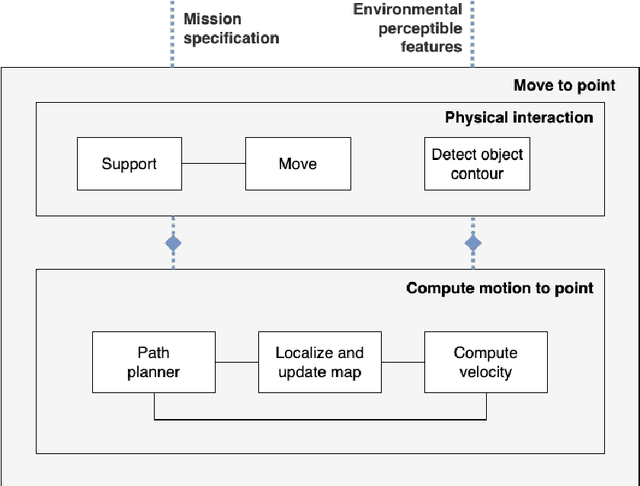


Model-based systems engineering (MBSE) is a methodology that exploits system representation during the entire system life-cycle. The use of formal models has gained momentum in robotics engineering over the past few years. Models play a crucial role in robot design; they serve as the basis for achieving holistic properties, such as functional reliability or adaptive resilience, and facilitate the automated production of modules. We propose the use of formal conceptualizations beyond the engineering phase, providing accurate models that can be leveraged at runtime. This paper explores the use of Category Theory, a mathematical framework for describing abstractions, as a formal language to produce such robot models. To showcase its practical application, we present a concrete example based on the Marathon 2 experiment. Here, we illustrate the potential of formalizing systems -- including their recovery mechanisms -- which allows engineers to design more trustworthy autonomous robots. This, in turn, enhances their dependability and performance.
A Contrastive Distillation Approach for Incremental Semantic Segmentation in Aerial Images
Dec 07, 2021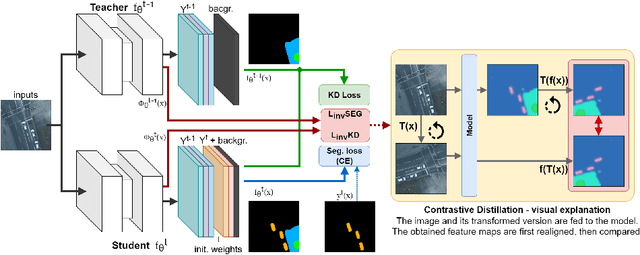
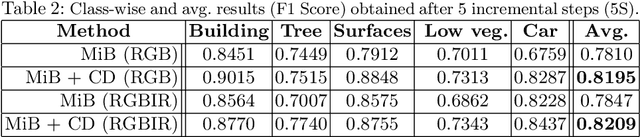
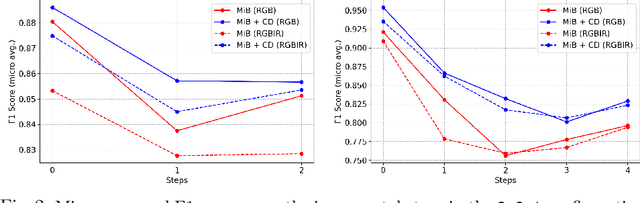
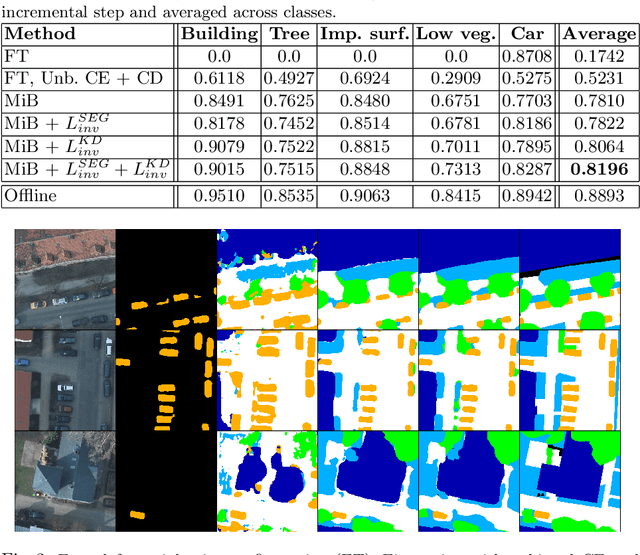
Incremental learning represents a crucial task in aerial image processing, especially given the limited availability of large-scale annotated datasets. A major issue concerning current deep neural architectures is known as catastrophic forgetting, namely the inability to faithfully maintain past knowledge once a new set of data is provided for retraining. Over the years, several techniques have been proposed to mitigate this problem for image classification and object detection. However, only recently the focus has shifted towards more complex downstream tasks such as instance or semantic segmentation. Starting from incremental-class learning for semantic segmentation tasks, our goal is to adapt this strategy to the aerial domain, exploiting a peculiar feature that differentiates it from natural images, namely the orientation. In addition to the standard knowledge distillation approach, we propose a contrastive regularization, where any given input is compared with its augmented version (i.e. flipping and rotations) in order to minimize the difference between the segmentation features produced by both inputs. We show the effectiveness of our solution on the Potsdam dataset, outperforming the incremental baseline in every test. Code available at: https://github.com/edornd/contrastive-distillation.