 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversity-Driven Learning: Tackling Spurious Correlations and Data Heterogeneity in Federated Models
Paper and Code
Apr 15, 2025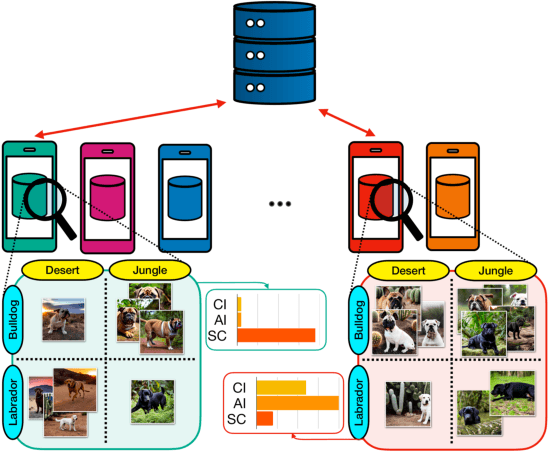

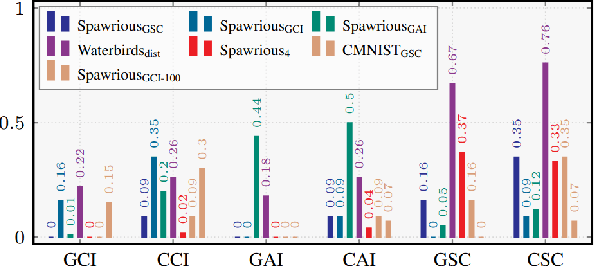
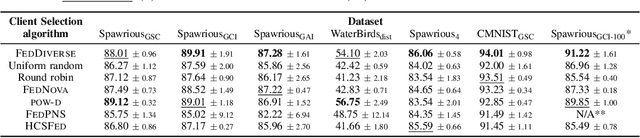
Federated Learning (FL) enables decentralized training of machine learning models on distributed data while preserving privacy. However, in real-world FL settings, client data is often non-identically distributed and imbalanced, resulting in statistical data heterogeneity which impacts the generalization capabilities of the server's model across clients, slows convergence and reduces performance. In this paper, we address this challenge by first proposing a characterization of statistical data heterogeneity by means of 6 metrics of global and client attribute imbalance, class imbalance, and spurious correlations. Next, we create and share 7 computer vision datasets for binary and multiclass image classification tasks in Federated Learning that cover a broad range of statistical data heterogeneity and hence simulate real-world situations. Finally, we propose FedDiverse, a novel client selection algorithm in FL which is designed to manage and leverage data heterogeneity across clients by promoting collaboration between clients with complementary data distributions. Experiments on the seven proposed FL datasets demonstrate FedDiverse's effectiveness in enhancing the performance and robustness of a variety of FL methods while having low communication and computational overhead.