 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Segmentation Networks to New Domains by Disentangling Latent Representations
Paper and Code
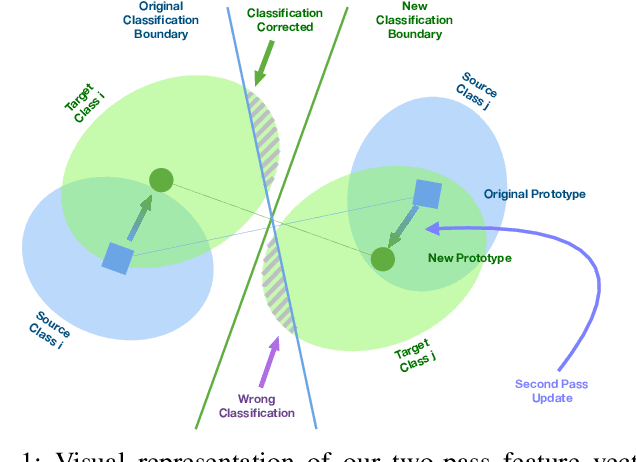
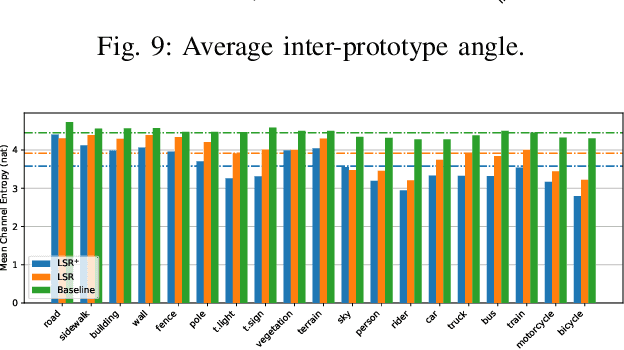
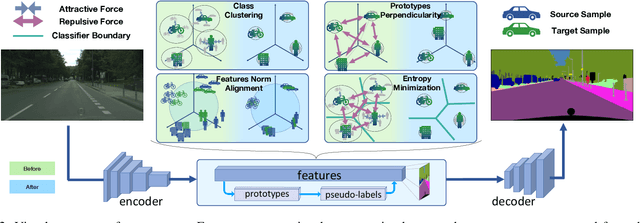
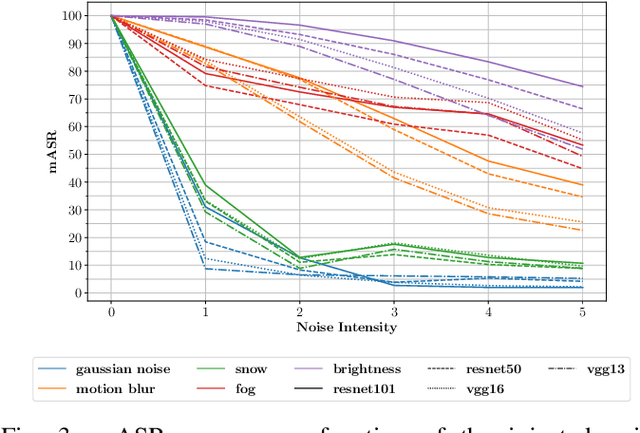
Deep learning models achieve outstanding accuracy in semantic segmentation, however they require a huge amount of labeled data for their optimization. Hence, domain adaptation approaches have come into play to transfer knowledge acquired on a label-abundant source domain to a related label-scarce target domain. However, such models do not generalize well to data with statistical properties not perfectly matching the ones of the training samples. In this work, we design and carefully analyze multiple latent space-shaping regularization strategies that work in conjunction to reduce the domain discrepancy in semantic segmentation. In particular, we devise a feature clustering strategy to increase domain alignment, a feature perpendicularity constraint to space apart feature belonging to different semantic classes, including those not present in the current batch, and a feature norm alignment strategy to separate active and inactive channels. Additionally, we propose a novel performance metric to capture the relative efficacy of an adaptation strategy compared to supervised training. We verify the effectiveness of our framework in synthetic-to-real and real-to-real adaptation scenarios, outperforming previous state-of-the-art methods on multiple road scenes benchmarks and using different backbones.