 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChronosAD: Leveraging Time Series Foundation Models for Accurate Anomaly Detection
May 31, 2026Time series anomaly detection is a crucial task in various domains, including finance, healthcare, and industry. However, existing methods often struggle to generalize across different datasets, especially when anomalies are subtle or context-dependent. To solve this issue, we introduce ChronosAD, a novel architecture for anomaly detection that uses a time series foundation model as a feature extractor. Specifically, it employs a two-stage pipeline: first, it uses the foundation model to extract embeddings for each time series in a zero-shot manner. Then, a custom-developed Temporal Block, composed of Bidirectional Long Short-Term Memory (BiLSTM) and Multi-Head Attention, refines these embeddings to capture temporal dependencies and highlight salient patterns. Unlike previous approaches, our model requires minimal task-specific tuning and demonstrates robust generalization across a wide range of domains, including industrial, medical, cyber-physical, and automotive systems. Extensive experiments on 11 benchmarks show that ChronosAD outperforms existing methods by 4.72% in AUC and 6.60% in AP on average. The source code is available at https://github.com/intelligolabs/ChronosAD.
Anomaly-Aware Vision-Language Adapters for Zero-Shot Anomaly Detection
May 12, 2026Zero-shot anomaly detection aims to identify defects in unseen categories without target-specific training. Existing methods usually apply the same feature transformation to all samples, treating normal and anomalous data uniformly despite their fundamentally asymmetric distributions, compact normals versus diverse anomalies. We instead exploit this natural asymmetry by proposing AVA-DINO, an anomaly-aware vision-language adaptation framework with dual specialized branches for normal and anomalous patterns that adapt frozen DINOv3 visual features. During training on auxiliary data, the two branches are learned jointly with a text-guided routing mechanism and explicit routing regularization that encourages branch specialization. At test time, only the input image and fixed, predefined language descriptions are used to dynamically combine the two branches, enabling an asymmetric activation. This design prevents degenerate uniform routing and allows context-specific feature transformations. Experiments across nine industrial and medical benchmarks demonstrate state-of-the-art performance, achieving 93.5% image-AUROC on MVTec-AD and strong cross-domain generalization to medical imaging without domain-specific fine-tuning. https://github.com/aqeeelmirza/AVA-DINO
Multimodal Abstractive Summarization of Instructional Videos with Vision-Language Models
May 12, 2026Multimodal video summarization requires visual features that align semantically with language generation. Traditional approaches rely on CNN features trained for object classification, which represent visual concepts as discrete categories not aligned with natural language. We propose ClipSum, a framework that leverages frozen CLIP vision-language features with explicit temporal modeling and dimension-adaptive fusion for instructional video summarization. CLIP's contrastive pre-training on 400M image-text pairs yields visual features semantically aligned with the linguistic concepts that text decoders generate, bridging the vision-language gap at the representation level. On YouCook2, ClipSum achieves 33.0% ROUGE-1 versus 30.5% for ResNet-152 with 4x lower dimensionality (512 vs. 2048), demonstrating that semantic alignment matters more than feature capacity. Frozen CLIP (33.0%) surpasses fine-tuned CLIP (32.3%), showing that preserving pre-trained alignment is more valuable than task-specific adaptation. https://github.com/aqeeelmirza/clipsum
MECAD: A multi-expert architecture for continual anomaly detection
Dec 17, 2025



In this paper we propose MECAD, a novel approach for continual anomaly detection using a multi-expert architecture. Our system dynamically assigns experts to object classes based on feature similarity and employs efficient memory management to preserve the knowledge of previously seen classes. By leveraging an optimized coreset selection and a specialized replay buffer mechanism, we enable incremental learning without requiring full model retraining. Our experimental evaluation on the MVTec AD dataset demonstrates that the optimal 5-expert configuration achieves an average AUROC of 0.8259 across 15 diverse object categories while significantly reducing knowledge degradation compared to single-expert approaches. This framework balances computational efficiency, specialized knowledge retention, and adaptability, making it well-suited for industrial environments with evolving product types.
Robust Anomaly Detection in Industrial Environments via Meta-Learning
Aug 25, 2025Anomaly detection is fundamental for ensuring quality control and operational efficiency in industrial environments, yet conventional approaches face significant challenges when training data contains mislabeled samples-a common occurrence in real-world scenarios. This paper presents RAD, a robust anomaly detection framework that integrates Normalizing Flows with Model-Agnostic Meta-Learning to address the critical challenge of label noise in industrial settings. Our approach employs a bi-level optimization strategy where meta-learning enables rapid adaptation to varying noise conditions, while uncertainty quantification guides adaptive L2 regularization to maintain model stability. The framework incorporates multiscale feature processing through pretrained feature extractors and leverages the precise likelihood estimation capabilities of Normalizing Flows for robust anomaly scoring. Comprehensive evaluation on MVTec-AD and KSDD2 datasets demonstrates superior performance, achieving I-AUROC scores of 95.4% and 94.6% respectively under clean conditions, while maintaining robust detection capabilities above 86.8% and 92.1% even when 50% of training samples are mislabeled. The results highlight RAD's exceptional resilience to noisy training conditions and its ability to detect subtle anomalies across diverse industrial scenarios, making it a practical solution for real-world anomaly detection applications where perfect data curation is challenging.
Diffusion-Based Data Augmentation for Medical Image Segmentation
Aug 25, 2025Medical image segmentation models struggle with rare abnormalities due to scarce annotated pathological data. We propose DiffAug a novel framework that combines textguided diffusion-based generation with automatic segmentation validation to address this challenge. Our proposed approach uses latent diffusion models conditioned on medical text descriptions and spatial masks to synthesize abnormalities via inpainting on normal images. Generated samples undergo dynamic quality validation through a latentspace segmentation network that ensures accurate localization while enabling single-step inference. The text prompts, derived from medical literature, guide the generation of diverse abnormality types without requiring manual annotation. Our validation mechanism filters synthetic samples based on spatial accuracy, maintaining quality while operating efficiently through direct latent estimation. Evaluated on three medical imaging benchmarks (CVC-ClinicDB, Kvasir-SEG, REFUGE2), our framework achieves state-of-the-art performance with 8-10% Dice improvements over baselines and reduces false negative rates by up to 28% for challenging cases like small polyps and flat lesions critical for early detection in screening applications.
A Contrastive Learning-Guided Confident Meta-learning for Zero Shot Anomaly Detection
Aug 25, 2025Industrial and medical anomaly detection faces critical challenges from data scarcity and prohibitive annotation costs, particularly in evolving manufacturing and healthcare settings. To address this, we propose CoZAD, a novel zero-shot anomaly detection framework that integrates soft confident learning with meta-learning and contrastive feature representation. Unlike traditional confident learning that discards uncertain samples, our method assigns confidence-based weights to all training data, preserving boundary information while emphasizing prototypical normal patterns. The framework quantifies data uncertainty through IQR-based thresholding and model uncertainty via covariance based regularization within a Model-Agnostic Meta-Learning. Contrastive learning creates discriminative feature spaces where normal patterns form compact clusters, enabling rapid domain adaptation. Comprehensive evaluation across 10 datasets spanning industrial and medical domains demonstrates state-of-the-art performance, outperforming existing methods on 6 out of 7 industrial benchmarks with notable improvements on texture-rich datasets (99.2% I-AUROC on DTD-Synthetic, 97.2% on BTAD) and pixellevel localization (96.3% P-AUROC on MVTec-AD). The framework eliminates dependence on vision-language alignments or model ensembles, making it valuable for resourceconstrained environments requiring rapid deployment.
Meta Learning-Driven Iterative Refinement for Robust Anomaly Detection in Industrial Inspection
Mar 03, 2025



This study investigates the performance of robust anomaly detection models in industrial inspection, focusing particularly on their ability to handle noisy data. We propose to leverage the adaptation ability of meta learning approaches to identify and reject noisy training data to improve the learning process. In our model, we employ Model Agnostic Meta Learning (MAML) and an iterative refinement process through an Inter-Quartile Range rejection scheme to enhance their adaptability and robustness. This approach significantly improves the models capability to distinguish between normal and defective conditions. Our results of experiments conducted on well known MVTec and KSDD2 datasets demonstrate that the proposed method not only excels in environments with substantial noise but can also contribute in case of a clear training set, isolating those samples that are relatively out of distribution, thus offering significant improvements over traditional models.
Material synthesis through simulations guided by machine learning: a position paper
Nov 21, 2024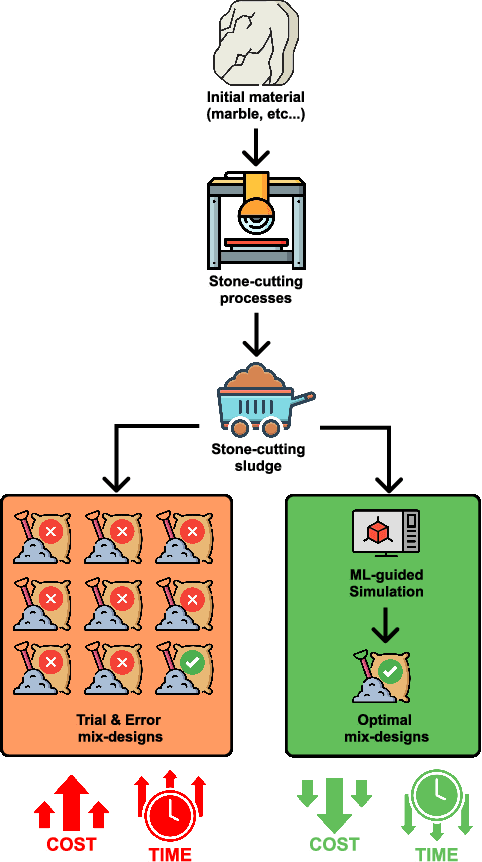
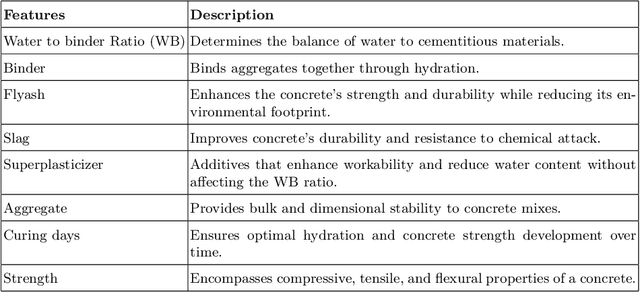
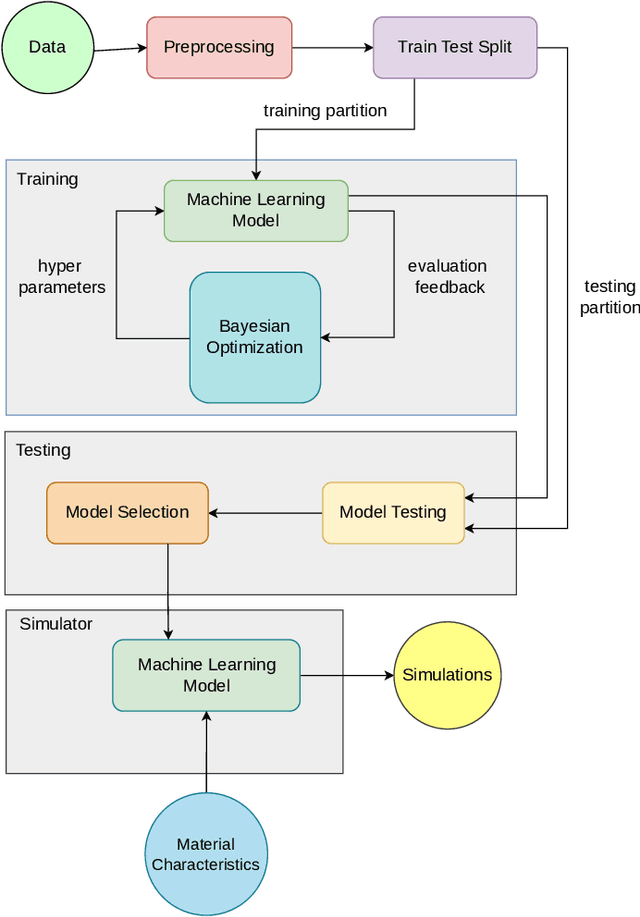

In this position paper, we propose an approach for sustainable data collection in the field of optimal mix design for marble sludge reuse. Marble sludge, a calcium-rich residual from stone-cutting processes, can be repurposed by mixing it with various ingredients. However, determining the optimal mix design is challenging due to the variability in sludge composition and the costly, time-consuming nature of experimental data collection. Also, we investigate the possibility of using machine learning models using meta-learning as an optimization tool to estimate the correct quantity of stone-cutting sludge to be used in aggregates to obtain a mix design with specific mechanical properties that can be used successfully in the building industry. Our approach offers two key advantages: (i) through simulations, a large dataset can be generated, saving time and money during the data collection phase, and (ii) Utilizing machine learning models, with performance enhancement through hyper-parameter optimization via meta-learning, to estimate optimal mix designs reducing the need for extensive manual experimentation, lowering costs, minimizing environmental impact, and accelerating the processing of quarry sludge. Our idea promises to streamline the marble sludge reuse process by leveraging collective data and advanced machine learning, promoting sustainability and efficiency in the stonecutting sector.
Self-Supervised Iterative Refinement for Anomaly Detection in Industrial Quality Control
Aug 21, 2024This study introduces the Iterative Refinement Process (IRP), a robust anomaly detection methodology designed for high-stakes industrial quality control. The IRP enhances defect detection accuracy through a cyclic data refinement strategy, iteratively removing misleading data points to improve model performance and robustness. We validate the IRP's effectiveness using two benchmark datasets, Kolektor SDD2 (KSDD2) and MVTec AD, covering a wide range of industrial products and defect types. Our experimental results demonstrate that the IRP consistently outperforms traditional anomaly detection models, particularly in environments with high noise levels. This study highlights the IRP's potential to significantly enhance anomaly detection processes in industrial settings, effectively managing the challenges of sparse and noisy data.