 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Online Gradient-Based Caching Policy with Logarithmic Complexity and Regret Guarantees
May 02, 2024The commonly used caching policies, such as LRU or LFU, exhibit optimal performance only for specific traffic patterns. Even advanced Machine Learning-based methods, which detect patterns in historical request data, struggle when future requests deviate from past trends. Recently, a new class of policies has emerged that makes no assumptions about the request arrival process. These algorithms solve an online optimization problem, enabling continuous adaptation to the context. They offer theoretical guarantees on the regret metric, which is the gap between the gain of the online policy and the gain of the optimal static cache allocation in hindsight. Nevertheless, the high computational complexity of these solutions hinders their practical adoption. In this study, we introduce a groundbreaking gradient-based online caching policy, the first to achieve logarithmic computational complexity relative to catalog size along with regret guarantees. This means our algorithm can efficiently handle large-scale data while minimizing the performance gap between real-time decisions and optimal hindsight choices. As requests arrive, our policy dynamically adjusts the probabilities of including items in the cache, which drive cache update decisions. Our algorithm's streamlined complexity is a key advantage, enabling its application to real-world traces featuring millions of requests and items. This is a significant achievement, as traces of this scale have been out of reach for existing policies with regret guarantees. To the best of our knowledge, our experimental results show for the first time that the regret guarantees of gradient-based caching policies bring significant benefits in scenarios of practical interest.
I-SPLIT: Deep Network Interpretability for Split Computing
Sep 23, 2022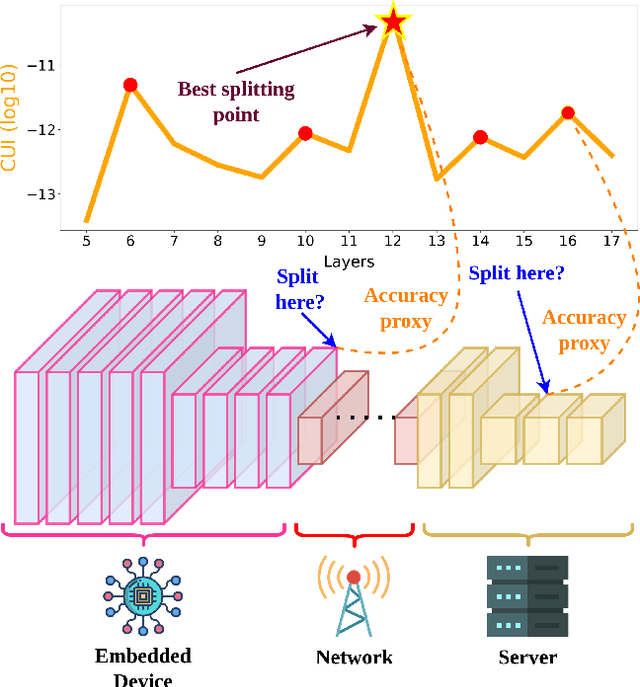
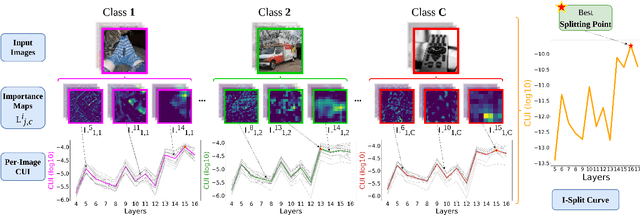
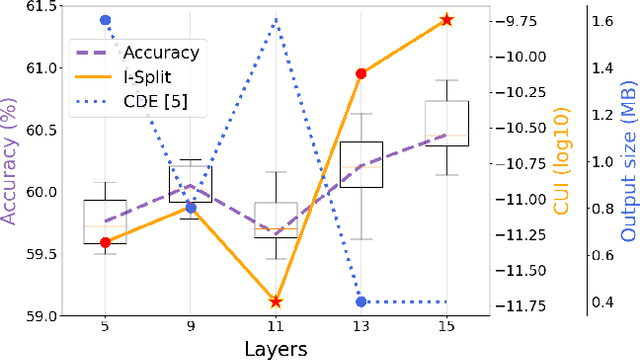
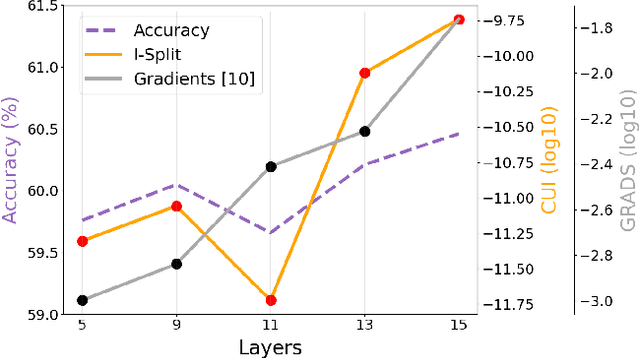
This work makes a substantial step in the field of split computing, i.e., how to split a deep neural network to host its early part on an embedded device and the rest on a server. So far, potential split locations have been identified exploiting uniquely architectural aspects, i.e., based on the layer sizes. Under this paradigm, the efficacy of the split in terms of accuracy can be evaluated only after having performed the split and retrained the entire pipeline, making an exhaustive evaluation of all the plausible splitting points prohibitive in terms of time. Here we show that not only the architecture of the layers does matter, but the importance of the neurons contained therein too. A neuron is important if its gradient with respect to the correct class decision is high. It follows that a split should be applied right after a layer with a high density of important neurons, in order to preserve the information flowing until then. Upon this idea, we propose Interpretable Split (I-SPLIT): a procedure that identifies the most suitable splitting points by providing a reliable prediction on how well this split will perform in terms of classification accuracy, beforehand of its effective implementation. As a further major contribution of I-SPLIT, we show that the best choice for the splitting point on a multiclass categorization problem depends also on which specific classes the network has to deal with. Exhaustive experiments have been carried out on two networks, VGG16 and ResNet-50, and three datasets, Tiny-Imagenet-200, notMNIST, and Chest X-Ray Pneumonia. The source code is available at https://github.com/vips4/I-Split.
AÇAI: Ascent Similarity Caching with Approximate Indexes
Jul 02, 2021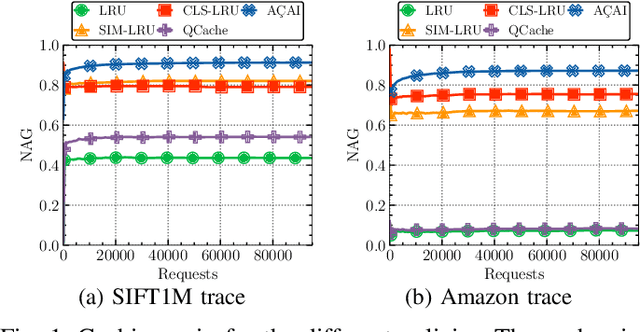
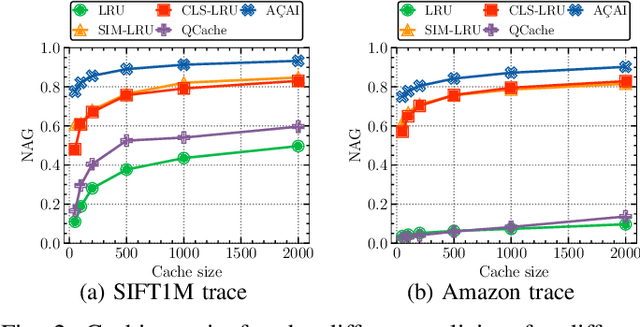
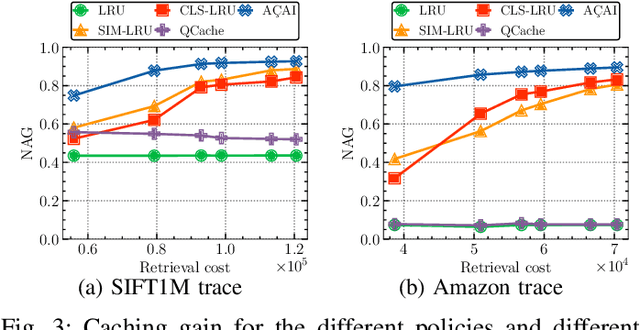
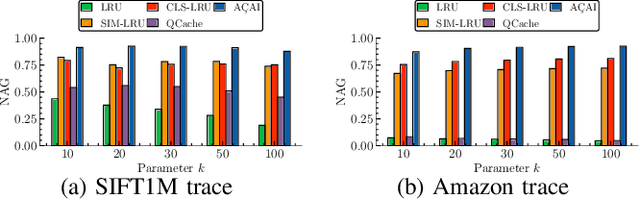
Similarity search is a key operation in multimedia retrieval systems and recommender systems, and it will play an important role also for future machine learning and augmented reality applications. When these systems need to serve large objects with tight delay constraints, edge servers close to the end-user can operate as similarity caches to speed up the retrieval. In this paper we present A\c{C}AI, a new similarity caching policy which improves on the state of the art by using (i) an (approximate) index for the whole catalog to decide which objects to serve locally and which to retrieve from the remote server, and (ii) a mirror ascent algorithm to update the set of local objects with strong guarantees even when the request process does not exhibit any statistical regularity.