 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess mining-driven modeling and simulation to enhance fault diagnosis in cyber-physical systems
Jun 26, 2025Fault diagnosis in Cyber-Physical Systems (CPSs) is essential for ensuring system dependability and operational efficiency by accurately detecting anomalies and identifying their root causes. However, the manual modeling of faulty behaviors often demands extensive domain expertise and produces models that are complex, error-prone, and difficult to interpret. To address this challenge, we present a novel unsupervised fault diagnosis methodology that integrates collective anomaly detection in multivariate time series, process mining, and stochastic simulation. Initially, collective anomalies are detected from low-level sensor data using multivariate time-series analysis. These anomalies are then transformed into structured event logs, enabling the discovery of interpretable process models through process mining. By incorporating timing distributions into the extracted Petri nets, the approach supports stochastic simulation of faulty behaviors, thereby enhancing root cause analysis and behavioral understanding. The methodology is validated using the Robotic Arm Dataset (RoAD), a widely recognized benchmark in smart manufacturing. Experimental results demonstrate its effectiveness in modeling, simulating, and classifying faulty behaviors in CPSs. This enables the creation of comprehensive fault dictionaries that support predictive maintenance and the development of digital twins for industrial environments.
Enhancing Split Computing and Early Exit Applications through Predefined Sparsity
Jul 16, 2024



In the past decade, Deep Neural Networks (DNNs) achieved state-of-the-art performance in a broad range of problems, spanning from object classification and action recognition to smart building and healthcare. The flexibility that makes DNNs such a pervasive technology comes at a price: the computational requirements preclude their deployment on most of the resource-constrained edge devices available today to solve real-time and real-world tasks. This paper introduces a novel approach to address this challenge by combining the concept of predefined sparsity with Split Computing (SC) and Early Exit (EE). In particular, SC aims at splitting a DNN with a part of it deployed on an edge device and the rest on a remote server. Instead, EE allows the system to stop using the remote server and rely solely on the edge device's computation if the answer is already good enough. Specifically, how to apply such a predefined sparsity to a SC and EE paradigm has never been studied. This paper studies this problem and shows how predefined sparsity significantly reduces the computational, storage, and energy burdens during the training and inference phases, regardless of the hardware platform. This makes it a valuable approach for enhancing the performance of SC and EE applications. Experimental results showcase reductions exceeding 4x in storage and computational complexity without compromising performance. The source code is available at https://github.com/intelligolabs/sparsity_sc_ee.
MTL-Split: Multi-Task Learning for Edge Devices using Split Computing
Jul 08, 2024



Split Computing (SC), where a Deep Neural Network (DNN) is intelligently split with a part of it deployed on an edge device and the rest on a remote server is emerging as a promising approach. It allows the power of DNNs to be leveraged for latency-sensitive applications that do not allow the entire DNN to be deployed remotely, while not having sufficient computation bandwidth available locally. In many such embedded systems scenarios, such as those in the automotive domain, computational resource constraints also necessitate Multi-Task Learning (MTL), where the same DNN is used for multiple inference tasks instead of having dedicated DNNs for each task, which would need more computing bandwidth. However, how to partition such a multi-tasking DNN to be deployed within a SC framework has not been sufficiently studied. This paper studies this problem, and MTL-Split, our novel proposed architecture, shows encouraging results on both synthetic and real-world data. The source code is available at https://github.com/intelligolabs/MTL-Split.
Neuro-symbolic Empowered Denoising Diffusion Probabilistic Models for Real-time Anomaly Detection in Industry 4.0
Jul 18, 2023
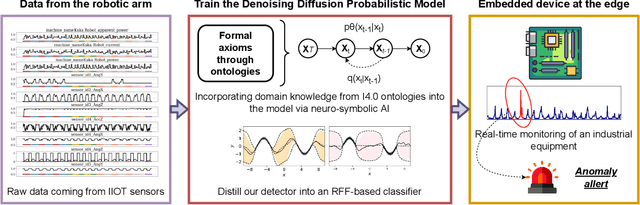
Industry 4.0 involves the integration of digital technologies, such as IoT, Big Data, and AI, into manufacturing and industrial processes to increase efficiency and productivity. As these technologies become more interconnected and interdependent, Industry 4.0 systems become more complex, which brings the difficulty of identifying and stopping anomalies that may cause disturbances in the manufacturing process. This paper aims to propose a diffusion-based model for real-time anomaly prediction in Industry 4.0 processes. Using a neuro-symbolic approach, we integrate industrial ontologies in the model, thereby adding formal knowledge on smart manufacturing. Finally, we propose a simple yet effective way of distilling diffusion models through Random Fourier Features for deployment on an embedded system for direct integration into the manufacturing process. To the best of our knowledge, this approach has never been explored before.