 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep Natural Language Inference predictor without language-specific training data
Sep 06, 2023In this paper we present a technique of NLP to tackle the problem of inference relation (NLI) between pairs of sentences in a target language of choice without a language-specific training dataset. We exploit a generic translation dataset, manually translated, along with two instances of the same pre-trained model - the first to generate sentence embeddings for the source language, and the second fine-tuned over the target language to mimic the first. This technique is known as Knowledge Distillation. The model has been evaluated over machine translated Stanford NLI test dataset, machine translated Multi-Genre NLI test dataset, and manually translated RTE3-ITA test dataset. We also test the proposed architecture over different tasks to empirically demonstrate the generality of the NLI task. The model has been evaluated over the native Italian ABSITA dataset, on the tasks of Sentiment Analysis, Aspect-Based Sentiment Analysis, and Topic Recognition. We emphasise the generality and exploitability of the Knowledge Distillation technique that outperforms other methodologies based on machine translation, even though the former was not directly trained on the data it was tested over.
Content-Based Textual File Type Detection at Scale
Jan 21, 2021
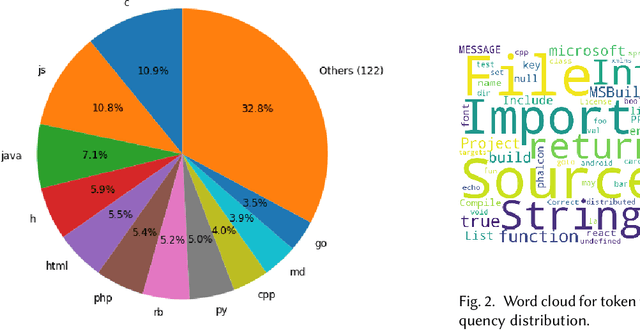
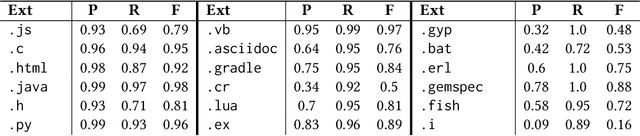
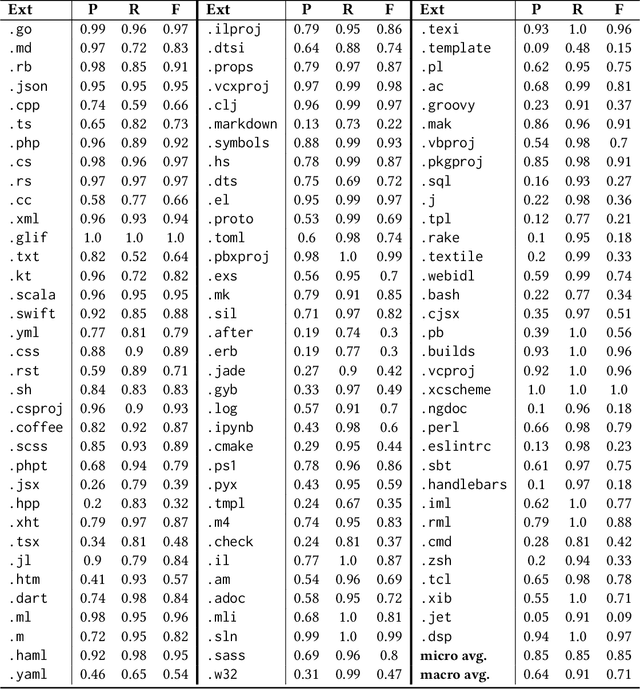
Programming language detection is a common need in the analysis of large source code bases. It is supported by a number of existing tools that rely on several features, and most notably file extensions, to determine file types. We consider the problem of accurately detecting the type of files commonly found in software code bases, based solely on textual file content. Doing so is helpful to classify source code that lack file extensions (e.g., code snippets posted on the Web or executable scripts), to avoid misclassifying source code that has been recorded with wrong or uncommon file extensions, and also shed some light on the intrinsic recognizability of source code files. We propose a simple model that (a) use a language-agnostic word tokenizer for textual files, (b) group tokens in 1-/2-grams, (c) build feature vectors based on N-gram frequencies, and (d) use a simple fully connected neural network as classifier. As training set we use textual files extracted from GitHub repositories with at least 1000 stars, using existing file extensions as ground truth. Despite its simplicity the proposed model reaches 85% in our experiments for a relatively high number of recognized classes (more than 130 file types).