 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Latent Graph Structures and their Uncertainty
May 30, 2024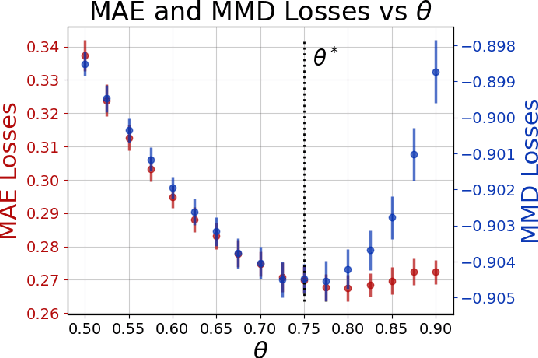



Within a prediction task, Graph Neural Networks (GNNs) use relational information as an inductive bias to enhance the model's accuracy. As task-relevant relations might be unknown, graph structure learning approaches have been proposed to learn them while solving the downstream prediction task. In this paper, we demonstrate that minimization of a point-prediction loss function, e.g., the mean absolute error, does not guarantee proper learning of the latent relational information and its associated uncertainty. Conversely, we prove that a suitable loss function on the stochastic model outputs simultaneously grants (i) the unknown adjacency matrix latent distribution and (ii) optimal performance on the prediction task. Finally, we propose a sampling-based method that solves this joint learning task. Empirical results validate our theoretical claims and demonstrate the effectiveness of the proposed approach.
A deep Natural Language Inference predictor without language-specific training data
Sep 06, 2023In this paper we present a technique of NLP to tackle the problem of inference relation (NLI) between pairs of sentences in a target language of choice without a language-specific training dataset. We exploit a generic translation dataset, manually translated, along with two instances of the same pre-trained model - the first to generate sentence embeddings for the source language, and the second fine-tuned over the target language to mimic the first. This technique is known as Knowledge Distillation. The model has been evaluated over machine translated Stanford NLI test dataset, machine translated Multi-Genre NLI test dataset, and manually translated RTE3-ITA test dataset. We also test the proposed architecture over different tasks to empirically demonstrate the generality of the NLI task. The model has been evaluated over the native Italian ABSITA dataset, on the tasks of Sentiment Analysis, Aspect-Based Sentiment Analysis, and Topic Recognition. We emphasise the generality and exploitability of the Knowledge Distillation technique that outperforms other methodologies based on machine translation, even though the former was not directly trained on the data it was tested over.